 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Swiss German Dictionary: Variation in Speech and Writing
Mar 31, 2020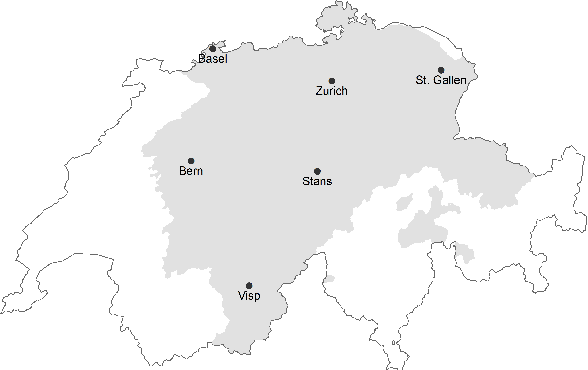
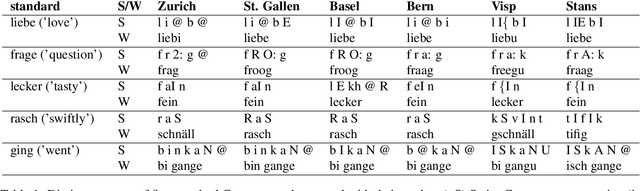

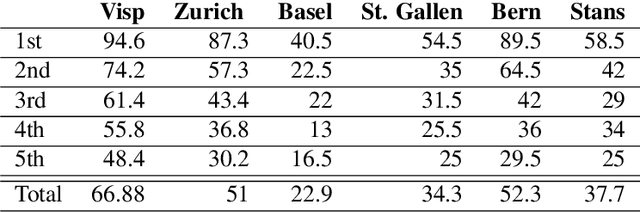
We introduce a dictionary containing forms of common words in various Swiss German dialects normalized into High German. As Swiss German is, for now, a predominantly spoken language, there is a significant variation in the written forms, even between speakers of the same dialect. To alleviate the uncertainty associated with this diversity, we complement the pairs of Swiss German - High German words with the Swiss German phonetic transcriptions (SAMPA). This dictionary becomes thus the first resource to combine large-scale spontaneous translation with phonetic transcriptions. Moreover, we control for the regional distribution and insure the equal representation of the major Swiss dialects. The coupling of the phonetic and written Swiss German forms is powerful. We show that they are sufficient to train a Transformer-based phoneme to grapheme model that generates credible novel Swiss German writings. In addition, we show that the inverse mapping - from graphemes to phonemes - can be modeled with a transformer trained with the novel dictionary. This generation of pronunciations for previously unknown words is key in training extensible automated speech recognition (ASR) systems, which are key beneficiaries of this dictionary.
Automatic Creation of Text Corpora for Low-Resource Languages from the Internet: The Case of Swiss German
Nov 30, 2019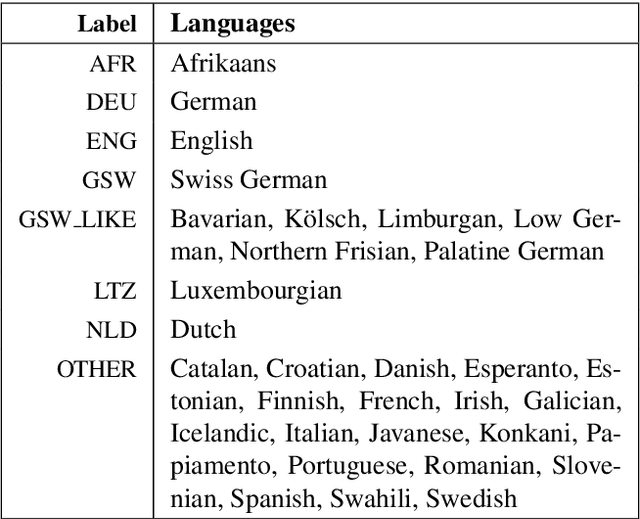
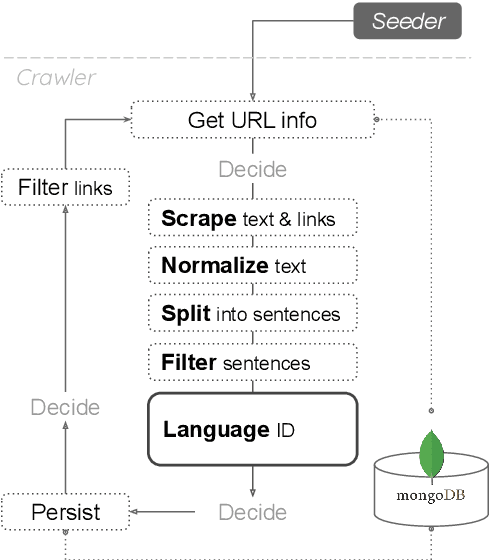
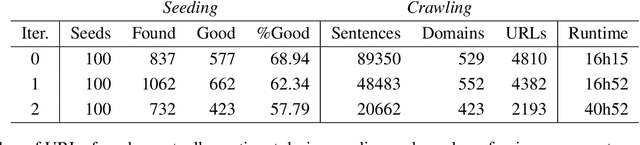
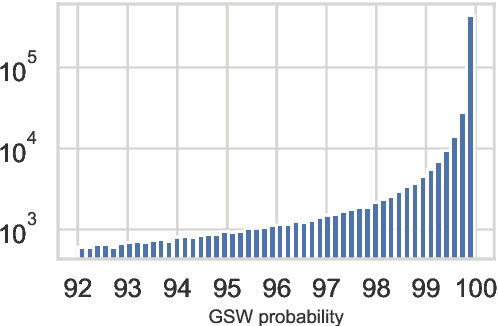
This paper presents SwissCrawl, the largest Swiss German text corpus to date. Composed of more than half a million sentences, it was generated using a customized web scraping tool that could be applied to other low-resource languages as well. The approach demonstrates how freely available web pages can be used to construct comprehensive text corpora, which are of fundamental importance for natural language processing. In an experimental evaluation, we show that using the new corpus leads to significant improvements for the task of language modeling. To capture new content, our approach will run continuously to keep increasing the corpus over time.