 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Prompting and Few-Shot Fine-Tuning: Revisiting Document Image Classification Using Large Language Models
Dec 18, 2024Classifying scanned documents is a challenging problem that involves image, layout, and text analysis for document understanding. Nevertheless, for certain benchmark datasets, notably RVL-CDIP, the state of the art is closing in to near-perfect performance when considering hundreds of thousands of training samples. With the advent of large language models (LLMs), which are excellent few-shot learners, the question arises to what extent the document classification problem can be addressed with only a few training samples, or even none at all. In this paper, we investigate this question in the context of zero-shot prompting and few-shot model fine-tuning, with the aim of reducing the need for human-annotated training samples as much as possible.
* ICPR 2024
Impact of Ground Truth Quality on Handwriting Recognition
Dec 14, 2023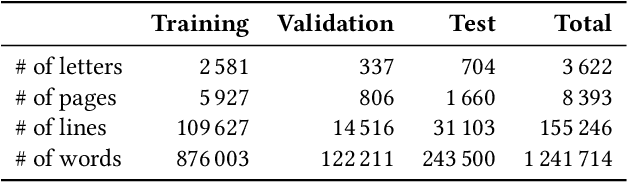

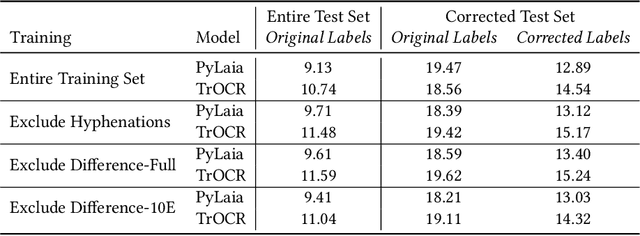
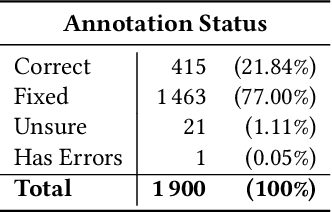
Handwriting recognition is a key technology for accessing the content of old manuscripts, helping to preserve cultural heritage. Deep learning shows an impressive performance in solving this task. However, to achieve its full potential, it requires a large amount of labeled data, which is difficult to obtain for ancient languages and scripts. Often, a trade-off has to be made between ground truth quantity and quality, as is the case for the recently introduced Bullinger database. It contains an impressive amount of over a hundred thousand labeled text line images of mostly premodern German and Latin texts that were obtained by automatically aligning existing page-level transcriptions with text line images. However, the alignment process introduces systematic errors, such as wrongly hyphenated words. In this paper, we investigate the impact of such errors on training and evaluation and suggest means to detect and correct typical alignment errors.
* SOICT 2023
Character Queries: A Transformer-based Approach to On-Line Handwritten Character Segmentation
Sep 06, 2023On-line handwritten character segmentation is often associated with handwriting recognition and even though recognition models include mechanisms to locate relevant positions during the recognition process, it is typically insufficient to produce a precise segmentation. Decoupling the segmentation from the recognition unlocks the potential to further utilize the result of the recognition. We specifically focus on the scenario where the transcription is known beforehand, in which case the character segmentation becomes an assignment problem between sampling points of the stylus trajectory and characters in the text. Inspired by the $k$-means clustering algorithm, we view it from the perspective of cluster assignment and present a Transformer-based architecture where each cluster is formed based on a learned character query in the Transformer decoder block. In order to assess the quality of our approach, we create character segmentation ground truths for two popular on-line handwriting datasets, IAM-OnDB and HANDS-VNOnDB, and evaluate multiple methods on them, demonstrating that our approach achieves the overall best results.
* ICDAR 2023 Best Student Paper Award. Code available at https://github.com/jungomi/character-queries
Automatic Creation of Text Corpora for Low-Resource Languages from the Internet: The Case of Swiss German
Nov 30, 2019
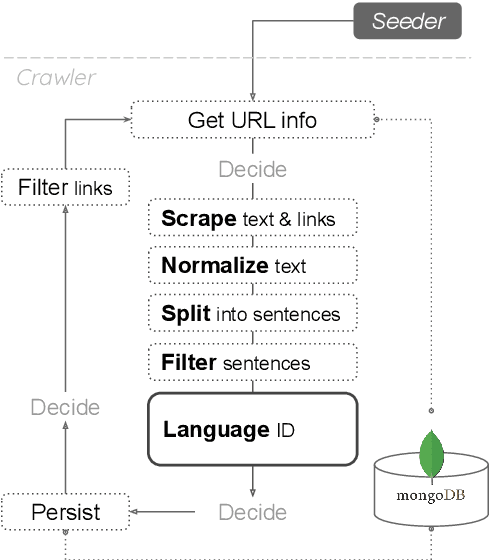
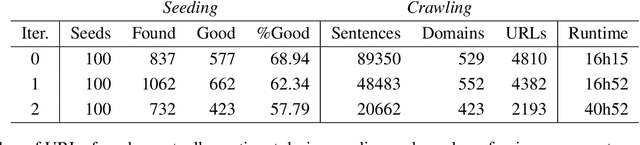
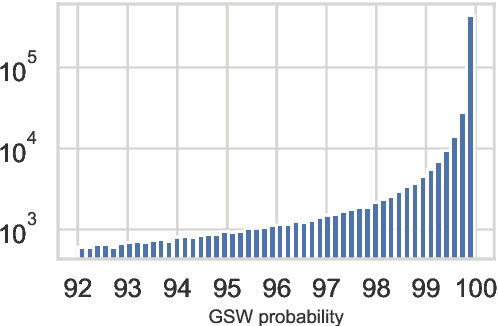
This paper presents SwissCrawl, the largest Swiss German text corpus to date. Composed of more than half a million sentences, it was generated using a customized web scraping tool that could be applied to other low-resource languages as well. The approach demonstrates how freely available web pages can be used to construct comprehensive text corpora, which are of fundamental importance for natural language processing. In an experimental evaluation, we show that using the new corpus leads to significant improvements for the task of language modeling. To capture new content, our approach will run continuously to keep increasing the corpus over time.