 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of Ground Truth Quality on Handwriting Recognition
Paper and Code
Dec 14, 2023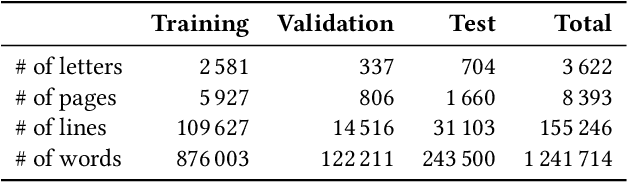

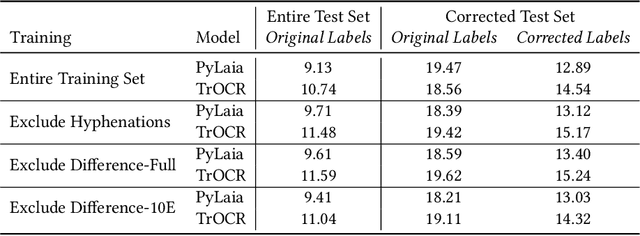
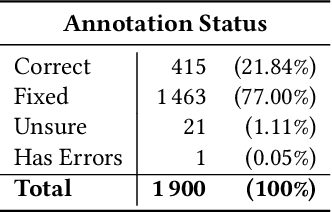
Handwriting recognition is a key technology for accessing the content of old manuscripts, helping to preserve cultural heritage. Deep learning shows an impressive performance in solving this task. However, to achieve its full potential, it requires a large amount of labeled data, which is difficult to obtain for ancient languages and scripts. Often, a trade-off has to be made between ground truth quantity and quality, as is the case for the recently introduced Bullinger database. It contains an impressive amount of over a hundred thousand labeled text line images of mostly premodern German and Latin texts that were obtained by automatically aligning existing page-level transcriptions with text line images. However, the alignment process introduces systematic errors, such as wrongly hyphenated words. In this paper, we investigate the impact of such errors on training and evaluation and suggest means to detect and correct typical alignment errors.