 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressed Learning for Nanosurface Deficiency Recognition Using Angle-resolved Scatterometry Data
Aug 25, 2025Nanoscale manufacturing requires high-precision surface inspection to guarantee the quality of the produced nanostructures. For production environments, angle-resolved scatterometry offers a non- invasive and in-line compatible alternative to traditional surface inspection methods, such as scanning electron microscopy. However, angle-resolved scatterometry currently suffers from long data acquisition time. Our study addresses the issue of slow data acquisition by proposing a compressed learning framework for the accurate recognition of nanosurface deficiencies using angle-resolved scatterometry data. The framework uses the particle swarm optimization algorithm with a sampling scheme customized for scattering patterns. This combination allows the identification of optimal sampling points in scatterometry data that maximize the detection accuracy of five different levels of deficiency in ZnO nanosurfaces. The proposed method significantly reduces the amount of sampled data while maintaining a high accuracy in deficiency detection, even in noisy environments. Notably, by sampling only 1% of the data, the method achieves an accuracy of over 86%, which further improves to 94% when the sampling rate is increased to 6%. These results demonstrate a favorable balance between data reduction and classification performance. The obtained results also show that the compressed learning framework effectively identifies critical sampling areas.
CTC Transcription Alignment of the Bullinger Letters: Automatic Improvement of Annotation Quality
Aug 11, 2025Handwritten text recognition for historical documents remains challenging due to handwriting variability, degraded sources, and limited layout-aware annotations. In this work, we address annotation errors - particularly hyphenation issues - in the Bullinger correspondence, a large 16th-century letter collection. We introduce a self-training method based on a CTC alignment algorithm that matches full transcriptions to text line images using dynamic programming and model output probabilities trained with the CTC loss. Our approach improves performance (e.g., by 1.1 percentage points CER with PyLaia) and increases alignment accuracy. Interestingly, we find that weaker models yield more accurate alignments, enabling an iterative training strategy. We release a new manually corrected subset of 100 pages from the Bullinger dataset, along with our code and benchmarks. Our approach can be applied iteratively to further improve the CER as well as the alignment quality for text recognition pipelines. Code and data are available via https://github.com/andreas-fischer-unifr/nntp.
Synthetic Data Augmentation for Table Detection: Re-evaluating TableNet's Performance with Automatically Generated Document Images
Jun 17, 2025Document pages captured by smartphones or scanners often contain tables, yet manual extraction is slow and error-prone. We introduce an automated LaTeX-based pipeline that synthesizes realistic two-column pages with visually diverse table layouts and aligned ground-truth masks. The generated corpus augments the real-world Marmot benchmark and enables a systematic resolution study of TableNet. Training TableNet on our synthetic data achieves a pixel-wise XOR error of 4.04% on our synthetic test set with a 256x256 input resolution, and 4.33% with 1024x1024. The best performance on the Marmot benchmark is 9.18% (at 256x256), while cutting manual annotation effort through automation.
Zero-Shot Prompting and Few-Shot Fine-Tuning: Revisiting Document Image Classification Using Large Language Models
Dec 18, 2024Classifying scanned documents is a challenging problem that involves image, layout, and text analysis for document understanding. Nevertheless, for certain benchmark datasets, notably RVL-CDIP, the state of the art is closing in to near-perfect performance when considering hundreds of thousands of training samples. With the advent of large language models (LLMs), which are excellent few-shot learners, the question arises to what extent the document classification problem can be addressed with only a few training samples, or even none at all. In this paper, we investigate this question in the context of zero-shot prompting and few-shot model fine-tuning, with the aim of reducing the need for human-annotated training samples as much as possible.
* ICPR 2024
Contrastive Learning for Character Detection in Ancient Greek Papyri
Sep 16, 2024This thesis investigates the effectiveness of SimCLR, a contrastive learning technique, in Greek letter recognition, focusing on the impact of various augmentation techniques. We pretrain the SimCLR backbone using the Alpub dataset (pretraining dataset) and fine-tune it on a smaller ICDAR dataset (finetuning dataset) to compare SimCLR's performance against traditional baseline models, which use cross-entropy and triplet loss functions. Additionally, we explore the role of different data augmentation strategies, essential for the SimCLR training process. Methodologically, we examine three primary approaches: (1) a baseline model using cross-entropy loss, (2) a triplet embedding model with a classification layer, and (3) a SimCLR pretrained model with a classification layer. Initially, we train the baseline, triplet, and SimCLR models using 93 augmentations on ResNet-18 and ResNet-50 networks with the ICDAR dataset. From these, the top four augmentations are selected using a statistical t-test. Pretraining of SimCLR is conducted on the Alpub dataset, followed by fine-tuning on the ICDAR dataset. The triplet loss model undergoes a similar process, being pretrained on the top four augmentations before fine-tuning on ICDAR. Our experiments show that SimCLR does not outperform the baselines in letter recognition tasks. The baseline model with cross-entropy loss demonstrates better performance than both SimCLR and the triplet loss model. This study provides a detailed evaluation of contrastive learning for letter recognition, highlighting SimCLR's limitations while emphasizing the strengths of traditional supervised learning models in this task. We believe SimCLR's cropping strategies may cause a semantic shift in the input image, reducing training effectiveness despite the large pretraining dataset. Our code is available at https://github.com/DIVA-DIA/MT_augmentation_and_contrastive_learning/.
Contextual Categorization Enhancement through LLMs Latent-Space
Apr 25, 2024Managing the semantic quality of the categorization in large textual datasets, such as Wikipedia, presents significant challenges in terms of complexity and cost. In this paper, we propose leveraging transformer models to distill semantic information from texts in the Wikipedia dataset and its associated categories into a latent space. We then explore different approaches based on these encodings to assess and enhance the semantic identity of the categories. Our graphical approach is powered by Convex Hull, while we utilize Hierarchical Navigable Small Worlds (HNSWs) for the hierarchical approach. As a solution to the information loss caused by the dimensionality reduction, we modulate the following mathematical solution: an exponential decay function driven by the Euclidean distances between the high-dimensional encodings of the textual categories. This function represents a filter built around a contextual category and retrieves items with a certain Reconsideration Probability (RP). Retrieving high-RP items serves as a tool for database administrators to improve data groupings by providing recommendations and identifying outliers within a contextual framework.
Impact of Ground Truth Quality on Handwriting Recognition
Dec 14, 2023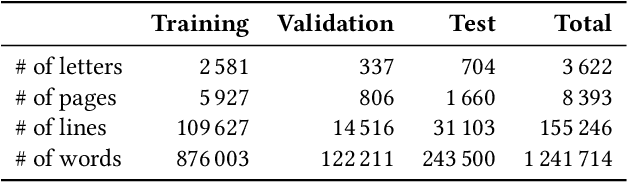

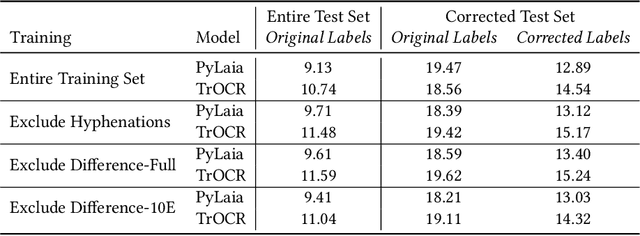
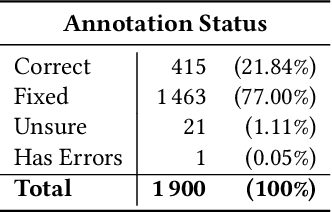
Handwriting recognition is a key technology for accessing the content of old manuscripts, helping to preserve cultural heritage. Deep learning shows an impressive performance in solving this task. However, to achieve its full potential, it requires a large amount of labeled data, which is difficult to obtain for ancient languages and scripts. Often, a trade-off has to be made between ground truth quantity and quality, as is the case for the recently introduced Bullinger database. It contains an impressive amount of over a hundred thousand labeled text line images of mostly premodern German and Latin texts that were obtained by automatically aligning existing page-level transcriptions with text line images. However, the alignment process introduces systematic errors, such as wrongly hyphenated words. In this paper, we investigate the impact of such errors on training and evaluation and suggest means to detect and correct typical alignment errors.
* SOICT 2023
Character Queries: A Transformer-based Approach to On-Line Handwritten Character Segmentation
Sep 06, 2023On-line handwritten character segmentation is often associated with handwriting recognition and even though recognition models include mechanisms to locate relevant positions during the recognition process, it is typically insufficient to produce a precise segmentation. Decoupling the segmentation from the recognition unlocks the potential to further utilize the result of the recognition. We specifically focus on the scenario where the transcription is known beforehand, in which case the character segmentation becomes an assignment problem between sampling points of the stylus trajectory and characters in the text. Inspired by the $k$-means clustering algorithm, we view it from the perspective of cluster assignment and present a Transformer-based architecture where each cluster is formed based on a learned character query in the Transformer decoder block. In order to assess the quality of our approach, we create character segmentation ground truths for two popular on-line handwriting datasets, IAM-OnDB and HANDS-VNOnDB, and evaluate multiple methods on them, demonstrating that our approach achieves the overall best results.
* ICDAR 2023 Best Student Paper Award. Code available at https://github.com/jungomi/character-queries
Towards Resolving Word Ambiguity with Word Embeddings
Jul 25, 2023Ambiguity is ubiquitous in natural language. Resolving ambiguous meanings is especially important in information retrieval tasks. While word embeddings carry semantic information, they fail to handle ambiguity well. Transformer models have been shown to handle word ambiguity for complex queries, but they cannot be used to identify ambiguous words, e.g. for a 1-word query. Furthermore, training these models is costly in terms of time, hardware resources, and training data, prohibiting their use in specialized environments with sensitive data. Word embeddings can be trained using moderate hardware resources. This paper shows that applying DBSCAN clustering to the latent space can identify ambiguous words and evaluate their level of ambiguity. An automatic DBSCAN parameter selection leads to high-quality clusters, which are semantically coherent and correspond well to the perceived meanings of a given word.
Improving Image Tracing with Convolutional Autoencoders by High-Pass Filter Preprocessing
Jun 15, 2023The process of transforming a raster image into a vector representation is known as image tracing. This study looks into several processing methods that include high-pass filtering, autoencoding, and vectorization to extract an abstract representation of an image. According to the findings, rebuilding an image with autoencoders, high-pass filtering it, and then vectorizing it can represent the image more abstractly while increasing the effectiveness of the vectorization process.