 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Prompting and Few-Shot Fine-Tuning: Revisiting Document Image Classification Using Large Language Models
Dec 18, 2024Classifying scanned documents is a challenging problem that involves image, layout, and text analysis for document understanding. Nevertheless, for certain benchmark datasets, notably RVL-CDIP, the state of the art is closing in to near-perfect performance when considering hundreds of thousands of training samples. With the advent of large language models (LLMs), which are excellent few-shot learners, the question arises to what extent the document classification problem can be addressed with only a few training samples, or even none at all. In this paper, we investigate this question in the context of zero-shot prompting and few-shot model fine-tuning, with the aim of reducing the need for human-annotated training samples as much as possible.
* ICPR 2024
Impact of Ground Truth Quality on Handwriting Recognition
Dec 14, 2023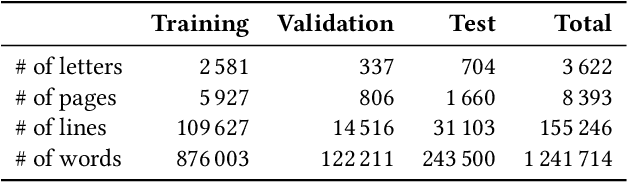

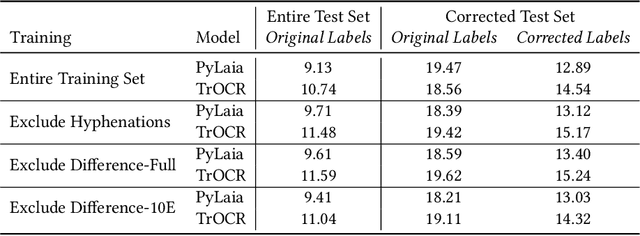
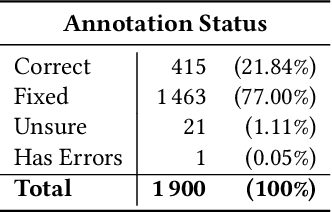
Handwriting recognition is a key technology for accessing the content of old manuscripts, helping to preserve cultural heritage. Deep learning shows an impressive performance in solving this task. However, to achieve its full potential, it requires a large amount of labeled data, which is difficult to obtain for ancient languages and scripts. Often, a trade-off has to be made between ground truth quantity and quality, as is the case for the recently introduced Bullinger database. It contains an impressive amount of over a hundred thousand labeled text line images of mostly premodern German and Latin texts that were obtained by automatically aligning existing page-level transcriptions with text line images. However, the alignment process introduces systematic errors, such as wrongly hyphenated words. In this paper, we investigate the impact of such errors on training and evaluation and suggest means to detect and correct typical alignment errors.
* SOICT 2023
DIVA-DAF: A Deep Learning Framework for Historical Document Image Analysis
Jan 21, 2022

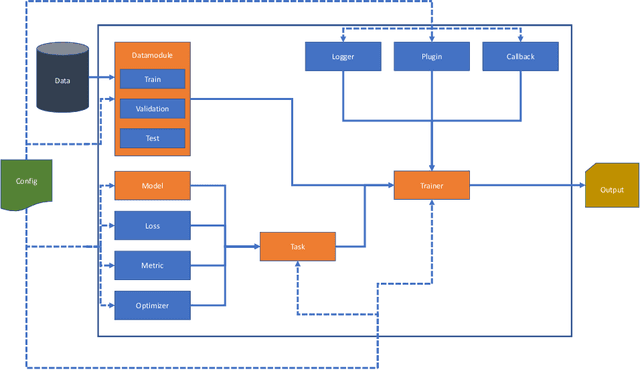
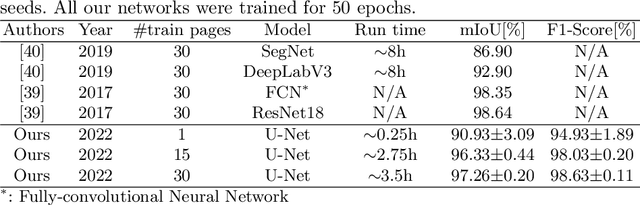
In this paper, we introduce a new deep learning framework called DIVA-DAF. We have developed this framework to support our research on historical document image analysis tasks and to develop techniques to reduce the need for manually-labeled ground truth. We want to apply self-supervised learning techniques and use different kinds of training data. Our new framework aids us in performing rapid prototyping and reproducible experiments. We present a first semantic segmentation experiment on DIVA-HisDB using our framework, achieving state-of-the-art results. The DIVA-DAF framework is open-source, and we encourage other research groups to use it for their experiments.
Generating Synthetic Handwritten Historical Documents With OCR Constrained GANs
Mar 15, 2021

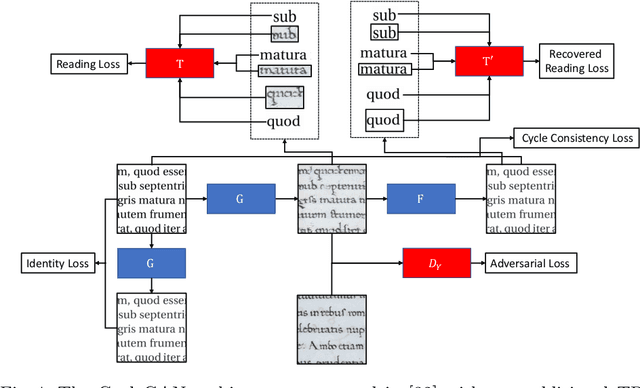

We present a framework to generate synthetic historical documents with precise ground truth using nothing more than a collection of unlabeled historical images. Obtaining large labeled datasets is often the limiting factor to effectively use supervised deep learning methods for Document Image Analysis (DIA). Prior approaches towards synthetic data generation either require expertise or result in poor accuracy in the synthetic documents. To achieve high precision transformations without requiring expertise, we tackle the problem in two steps. First, we create template documents with user-specified content and structure. Second, we transfer the style of a collection of unlabeled historical images to these template documents while preserving their text and layout. We evaluate the use of our synthetic historical documents in a pre-training setting and find that we outperform the baselines (randomly initialized and pre-trained). Additionally, with visual examples, we demonstrate a high-quality synthesis that makes it possible to generate large labeled historical document datasets with precise ground truth.
Labeling, Cutting, Grouping: an Efficient Text Line Segmentation Method for Medieval Manuscripts
Jul 01, 2019



This paper introduces a new way for text-line extraction by integrating deep-learning based pre-classification and state-of-the-art segmentation methods. Text-line extraction in complex handwritten documents poses a significant challenge, even to the most modern computer vision algorithms. Historical manuscripts are a particularly hard class of documents as they present several forms of noise, such as degradation, bleed-through, interlinear glosses, and elaborated scripts. In this work, we propose a novel method which uses semantic segmentation at pixel level as intermediate task, followed by a text-line extraction step. We measured the performance of our method on a recent dataset of challenging medieval manuscripts and surpassed state-of-the-art results by reducing the error by 80.7%. Furthermore, we demonstrate the effectiveness of our approach on various other datasets written in different scripts. Hence, our contribution is two-fold. First, we demonstrate that semantic pixel segmentation can be used as strong denoising pre-processing step before performing text line extraction. Second, we introduce a novel, simple and robust algorithm that leverages the high-quality semantic segmentation to achieve a text-line extraction performance of 99.42% line IU on a challenging dataset.
Improving Reproducible Deep Learning Workflows with DeepDIVA
Jun 11, 2019
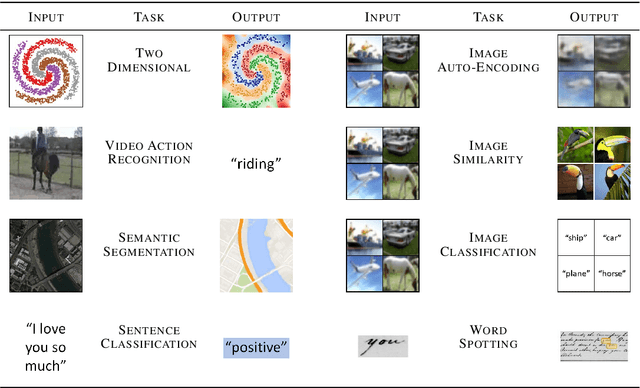
The field of deep learning is experiencing a trend towards producing reproducible research. Nevertheless, it is still often a frustrating experience to reproduce scientific results. This is especially true in the machine learning community, where it is considered acceptable to have black boxes in your experiments. We present DeepDIVA, a framework designed to facilitate easy experimentation and their reproduction. This framework allows researchers to share their experiments with others, while providing functionality that allows for easy experimentation, such as: boilerplate code, experiment management, hyper-parameter optimization, verification of data integrity and visualization of data and results. Additionally, the code of DeepDIVA is well-documented and supported by several tutorials that allow a new user to quickly familiarize themselves with the framework.