Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIVA-DAF: A Deep Learning Framework for Historical Document Image Analysis
Paper and Code


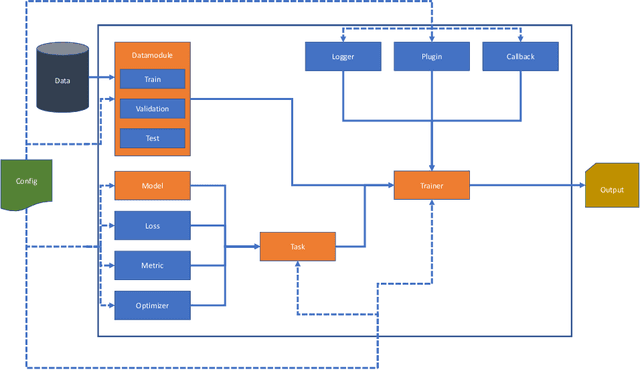
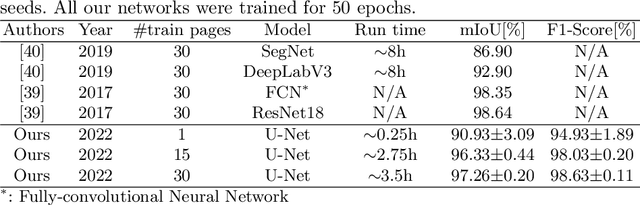
In this paper, we introduce a new deep learning framework called DIVA-DAF. We have developed this framework to support our research on historical document image analysis tasks and to develop techniques to reduce the need for manually-labeled ground truth. We want to apply self-supervised learning techniques and use different kinds of training data. Our new framework aids us in performing rapid prototyping and reproducible experiments. We present a first semantic segmentation experiment on DIVA-HisDB using our framework, achieving state-of-the-art results. The DIVA-DAF framework is open-source, and we encourage other research groups to use it for their experiments.
View paper on