 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning for Character Detection in Ancient Greek Papyri
Sep 16, 2024This thesis investigates the effectiveness of SimCLR, a contrastive learning technique, in Greek letter recognition, focusing on the impact of various augmentation techniques. We pretrain the SimCLR backbone using the Alpub dataset (pretraining dataset) and fine-tune it on a smaller ICDAR dataset (finetuning dataset) to compare SimCLR's performance against traditional baseline models, which use cross-entropy and triplet loss functions. Additionally, we explore the role of different data augmentation strategies, essential for the SimCLR training process. Methodologically, we examine three primary approaches: (1) a baseline model using cross-entropy loss, (2) a triplet embedding model with a classification layer, and (3) a SimCLR pretrained model with a classification layer. Initially, we train the baseline, triplet, and SimCLR models using 93 augmentations on ResNet-18 and ResNet-50 networks with the ICDAR dataset. From these, the top four augmentations are selected using a statistical t-test. Pretraining of SimCLR is conducted on the Alpub dataset, followed by fine-tuning on the ICDAR dataset. The triplet loss model undergoes a similar process, being pretrained on the top four augmentations before fine-tuning on ICDAR. Our experiments show that SimCLR does not outperform the baselines in letter recognition tasks. The baseline model with cross-entropy loss demonstrates better performance than both SimCLR and the triplet loss model. This study provides a detailed evaluation of contrastive learning for letter recognition, highlighting SimCLR's limitations while emphasizing the strengths of traditional supervised learning models in this task. We believe SimCLR's cropping strategies may cause a semantic shift in the input image, reducing training effectiveness despite the large pretraining dataset. Our code is available at https://github.com/DIVA-DIA/MT_augmentation_and_contrastive_learning/.
Impact of Ground Truth Quality on Handwriting Recognition
Dec 14, 2023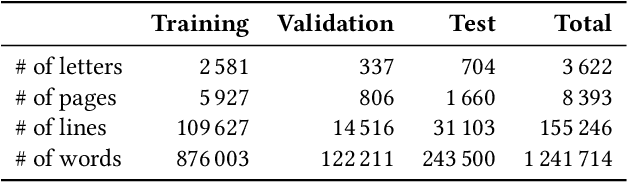

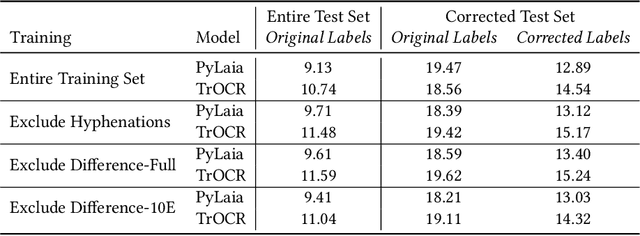
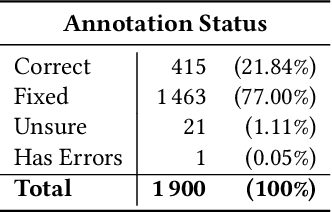
Handwriting recognition is a key technology for accessing the content of old manuscripts, helping to preserve cultural heritage. Deep learning shows an impressive performance in solving this task. However, to achieve its full potential, it requires a large amount of labeled data, which is difficult to obtain for ancient languages and scripts. Often, a trade-off has to be made between ground truth quantity and quality, as is the case for the recently introduced Bullinger database. It contains an impressive amount of over a hundred thousand labeled text line images of mostly premodern German and Latin texts that were obtained by automatically aligning existing page-level transcriptions with text line images. However, the alignment process introduces systematic errors, such as wrongly hyphenated words. In this paper, we investigate the impact of such errors on training and evaluation and suggest means to detect and correct typical alignment errors.
* SOICT 2023
DIVA-DAF: A Deep Learning Framework for Historical Document Image Analysis
Jan 21, 2022

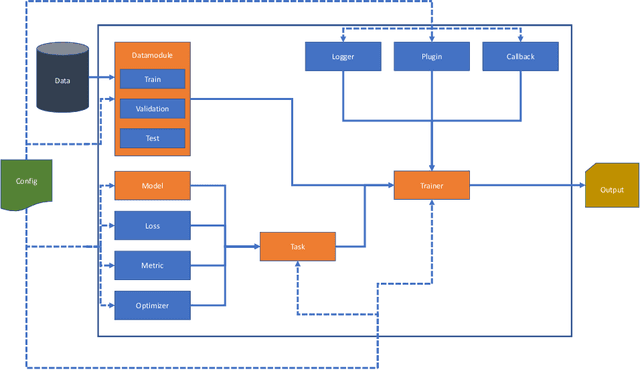
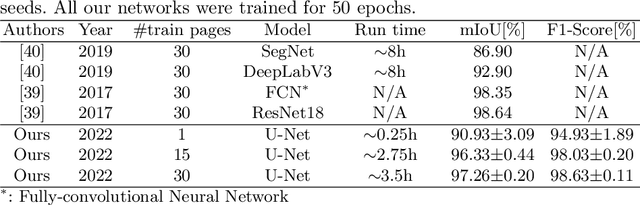
In this paper, we introduce a new deep learning framework called DIVA-DAF. We have developed this framework to support our research on historical document image analysis tasks and to develop techniques to reduce the need for manually-labeled ground truth. We want to apply self-supervised learning techniques and use different kinds of training data. Our new framework aids us in performing rapid prototyping and reproducible experiments. We present a first semantic segmentation experiment on DIVA-HisDB using our framework, achieving state-of-the-art results. The DIVA-DAF framework is open-source, and we encourage other research groups to use it for their experiments.
Generating Synthetic Handwritten Historical Documents With OCR Constrained GANs
Mar 15, 2021

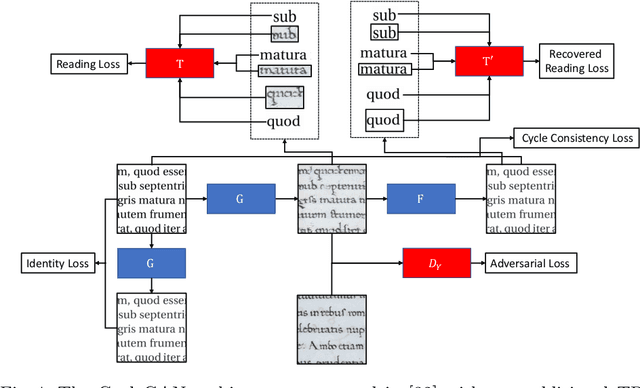

We present a framework to generate synthetic historical documents with precise ground truth using nothing more than a collection of unlabeled historical images. Obtaining large labeled datasets is often the limiting factor to effectively use supervised deep learning methods for Document Image Analysis (DIA). Prior approaches towards synthetic data generation either require expertise or result in poor accuracy in the synthetic documents. To achieve high precision transformations without requiring expertise, we tackle the problem in two steps. First, we create template documents with user-specified content and structure. Second, we transfer the style of a collection of unlabeled historical images to these template documents while preserving their text and layout. We evaluate the use of our synthetic historical documents in a pre-training setting and find that we outperform the baselines (randomly initialized and pre-trained). Additionally, with visual examples, we demonstrate a high-quality synthesis that makes it possible to generate large labeled historical document datasets with precise ground truth.
Trainable Spectrally Initializable Matrix Transformations in Convolutional Neural Networks
Nov 13, 2019



In this work, we investigate the application of trainable and spectrally initializable matrix transformations on the feature maps produced by convolution operations. While previous literature has already demonstrated the possibility of adding static spectral transformations as feature processors, our focus is on more general trainable transforms. We study the transforms in various architectural configurations on four datasets of different nature: from medical (ColorectalHist, HAM10000) and natural (Flowers, ImageNet) images to historical documents (CB55) and handwriting recognition (GPDS). With rigorous experiments that control for the number of parameters and randomness, we show that networks utilizing the introduced matrix transformations outperform vanilla neural networks. The observed accuracy increases by an average of 2.2 across all datasets. In addition, we show that the benefit of spectral initialization leads to significantly faster convergence, as opposed to randomly initialized matrix transformations. The transformations are implemented as auto-differentiable PyTorch modules that can be incorporated into any neural network architecture. The entire code base is open-source.
Labeling, Cutting, Grouping: an Efficient Text Line Segmentation Method for Medieval Manuscripts
Jul 01, 2019



This paper introduces a new way for text-line extraction by integrating deep-learning based pre-classification and state-of-the-art segmentation methods. Text-line extraction in complex handwritten documents poses a significant challenge, even to the most modern computer vision algorithms. Historical manuscripts are a particularly hard class of documents as they present several forms of noise, such as degradation, bleed-through, interlinear glosses, and elaborated scripts. In this work, we propose a novel method which uses semantic segmentation at pixel level as intermediate task, followed by a text-line extraction step. We measured the performance of our method on a recent dataset of challenging medieval manuscripts and surpassed state-of-the-art results by reducing the error by 80.7%. Furthermore, we demonstrate the effectiveness of our approach on various other datasets written in different scripts. Hence, our contribution is two-fold. First, we demonstrate that semantic pixel segmentation can be used as strong denoising pre-processing step before performing text line extraction. Second, we introduce a novel, simple and robust algorithm that leverages the high-quality semantic segmentation to achieve a text-line extraction performance of 99.42% line IU on a challenging dataset.
Graph-Based Offline Signature Verification
Jun 25, 2019

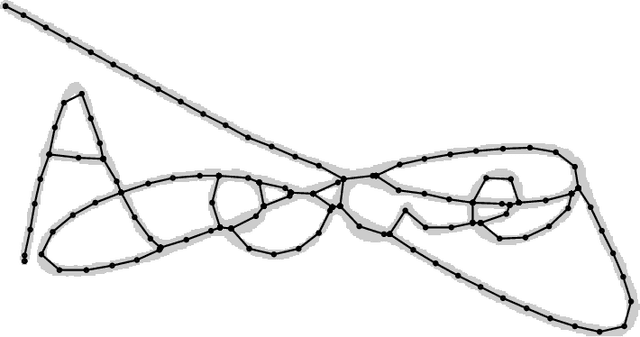
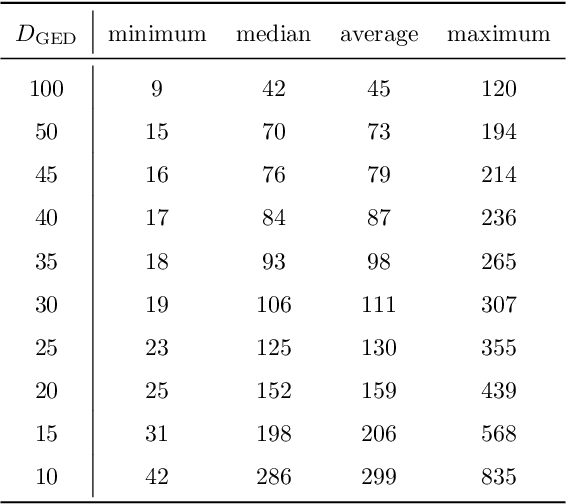
Graphs provide a powerful representation formalism that offers great promise to benefit tasks like handwritten signature verification. While most state-of-the-art approaches to signature verification rely on fixed-size representations, graphs are flexible in size and allow modeling local features as well as the global structure of the handwriting. In this article, we present two recent graph-based approaches to offline signature verification: keypoint graphs with approximated graph edit distance and inkball models. We provide a comprehensive description of the methods, propose improvements both in terms of computational time and accuracy, and report experimental results for four benchmark datasets. The proposed methods achieve top results for several benchmarks, highlighting the potential of graph-based signature verification.
Improving Reproducible Deep Learning Workflows with DeepDIVA
Jun 11, 2019
The field of deep learning is experiencing a trend towards producing reproducible research. Nevertheless, it is still often a frustrating experience to reproduce scientific results. This is especially true in the machine learning community, where it is considered acceptable to have black boxes in your experiments. We present DeepDIVA, a framework designed to facilitate easy experimentation and their reproduction. This framework allows researchers to share their experiments with others, while providing functionality that allows for easy experimentation, such as: boilerplate code, experiment management, hyper-parameter optimization, verification of data integrity and visualization of data and results. Additionally, the code of DeepDIVA is well-documented and supported by several tutorials that allow a new user to quickly familiarize themselves with the framework.
Survey of Artificial Intelligence for Card Games and Its Application to the Swiss Game Jass
Jun 11, 2019In the last decades we have witnessed the success of applications of Artificial Intelligence to playing games. In this work we address the challenging field of games with hidden information and card games in particular. Jass is a very popular card game in Switzerland and is closely connected with Swiss culture. To the best of our knowledge, performances of Artificial Intelligence agents in the game of Jass do not outperform top players yet. Our contribution to the community is two-fold. First, we provide an overview of the current state-of-the-art of Artificial Intelligence methods for card games in general. Second, we discuss their application to the use-case of the Swiss card game Jass. This paper aims to be an entry point for both seasoned researchers and new practitioners who want to join in the Jass challenge.
A Comprehensive Study of ImageNet Pre-Training for Historical Document Image Analysis
May 22, 2019


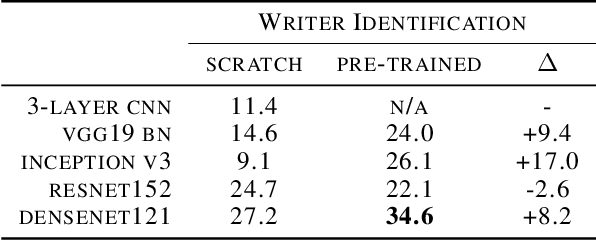
Automatic analysis of scanned historical documents comprises a wide range of image analysis tasks, which are often challenging for machine learning due to a lack of human-annotated learning samples. With the advent of deep neural networks, a promising way to cope with the lack of training data is to pre-train models on images from a different domain and then fine-tune them on historical documents. In the current research, a typical example of such cross-domain transfer learning is the use of neural networks that have been pre-trained on the ImageNet database for object recognition. It remains a mostly open question whether or not this pre-training helps to analyse historical documents, which have fundamentally different image properties when compared with ImageNet. In this paper, we present a comprehensive empirical survey on the effect of ImageNet pre-training for diverse historical document analysis tasks, including character recognition, style classification, manuscript dating, semantic segmentation, and content-based retrieval. While we obtain mixed results for semantic segmentation at pixel-level, we observe a clear trend across different network architectures that ImageNet pre-training has a positive effect on classification as well as content-based retrieval.