 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Synthetic Handwritten Historical Documents With OCR Constrained GANs
Paper and Code


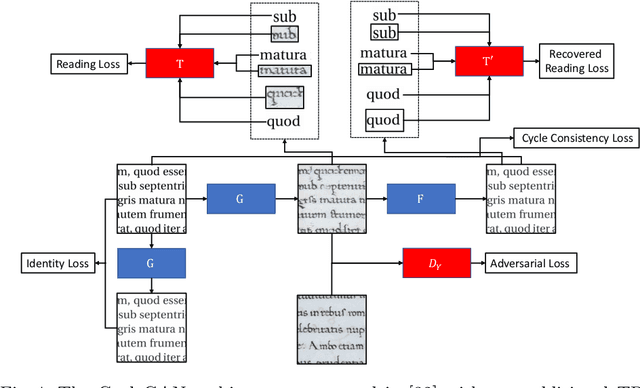

We present a framework to generate synthetic historical documents with precise ground truth using nothing more than a collection of unlabeled historical images. Obtaining large labeled datasets is often the limiting factor to effectively use supervised deep learning methods for Document Image Analysis (DIA). Prior approaches towards synthetic data generation either require expertise or result in poor accuracy in the synthetic documents. To achieve high precision transformations without requiring expertise, we tackle the problem in two steps. First, we create template documents with user-specified content and structure. Second, we transfer the style of a collection of unlabeled historical images to these template documents while preserving their text and layout. We evaluate the use of our synthetic historical documents in a pre-training setting and find that we outperform the baselines (randomly initialized and pre-trained). Additionally, with visual examples, we demonstrate a high-quality synthesis that makes it possible to generate large labeled historical document datasets with precise ground truth.