 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Rule to Adapt: Generalized Multi-source Feature Learning Using Unsupervised Domain Adaptation for Colorectal Cancer Tissue Detection
Aug 20, 2021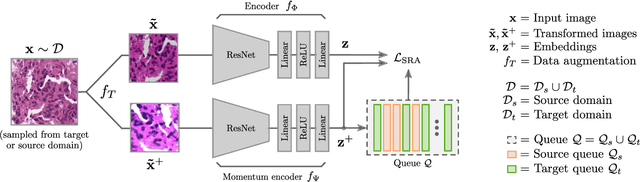
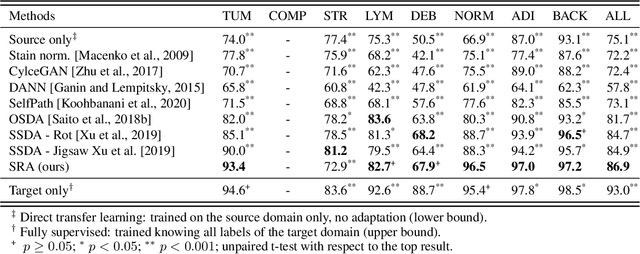
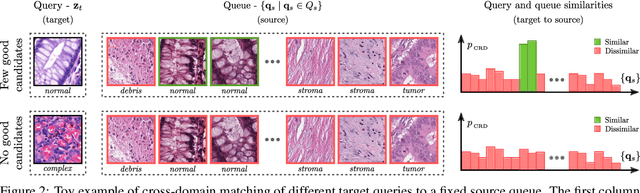
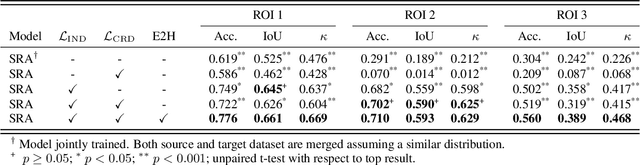
Supervised learning is constrained by the availability of labeled data, which are especially expensive to acquire in the field of digital pathology. Making use of open-source data for pre-training or using domain adaptation can be a way to overcome this issue. However, pre-trained networks often fail to generalize to new test domains that are not distributed identically due to variations in tissue stainings, types, and textures. Additionally, current domain adaptation methods mainly rely on fully-labeled source datasets. In this work, we propose SRA, which takes advantage of self-supervised learning to perform domain adaptation and removes the necessity of a fully-labeled source dataset. SRA can effectively transfer the discriminative knowledge obtained from a few labeled source domain's data to a new target domain without requiring additional tissue annotations. Our method harnesses both domains' structures by capturing visual similarity with intra-domain and cross-domain self-supervision. Moreover, we present a generalized formulation of our approach that allows the architecture to learn from multi-source domains. We show that our proposed method outperforms baselines for domain adaptation of colorectal tissue type classification and further validate our approach on our in-house clinical cohort. The code and models are available open-source: https://github.com/christianabbet/SRA.
A Comprehensive Study of ImageNet Pre-Training for Historical Document Image Analysis
May 22, 2019


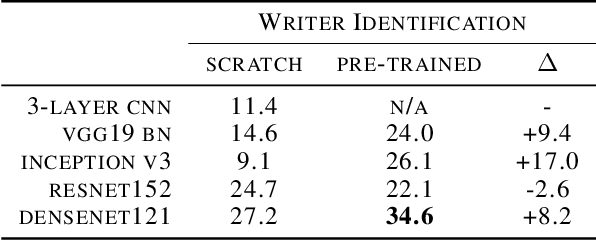
Automatic analysis of scanned historical documents comprises a wide range of image analysis tasks, which are often challenging for machine learning due to a lack of human-annotated learning samples. With the advent of deep neural networks, a promising way to cope with the lack of training data is to pre-train models on images from a different domain and then fine-tune them on historical documents. In the current research, a typical example of such cross-domain transfer learning is the use of neural networks that have been pre-trained on the ImageNet database for object recognition. It remains a mostly open question whether or not this pre-training helps to analyse historical documents, which have fundamentally different image properties when compared with ImageNet. In this paper, we present a comprehensive empirical survey on the effect of ImageNet pre-training for diverse historical document analysis tasks, including character recognition, style classification, manuscript dating, semantic segmentation, and content-based retrieval. While we obtain mixed results for semantic segmentation at pixel-level, we observe a clear trend across different network architectures that ImageNet pre-training has a positive effect on classification as well as content-based retrieval.