 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning-Based Cervical Cytology Diagnostics in Low-Data Regime and Low-Resource Setting
Feb 10, 2023



Screening Papanicolaou test samples effectively reduces cervical cancer-related mortality, but the lack of trained cytopathologists prevents its widespread adoption in low-resource settings. Developing AI algorithms, e.g., deep learning to analyze the digitized cytology images suited to resource-constrained countries is appealing. Albeit successful, it comes at the price of collecting large annotated training datasets, which is both costly and time-consuming. Our study shows that the large number of unlabeled images that can be sampled from digitized cytology slides make for a ripe ground where self-supervised learning methods can thrive and even outperform off-the-shelf deep learning models on various downstream tasks. Along the same line, we report improved performance and data efficiency using modern augmentation strategies.
Self-Rule to Adapt: Generalized Multi-source Feature Learning Using Unsupervised Domain Adaptation for Colorectal Cancer Tissue Detection
Aug 20, 2021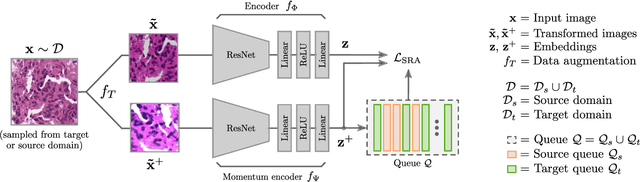
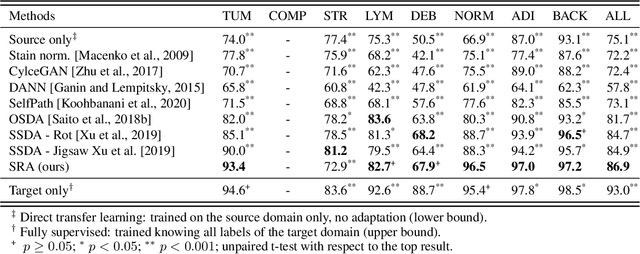
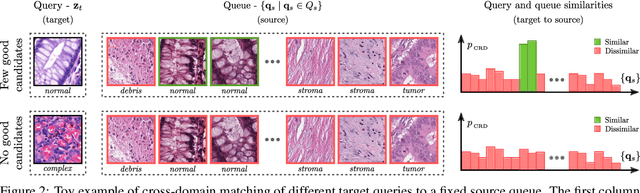
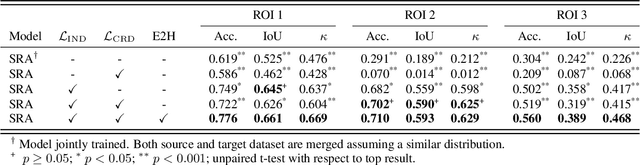
Supervised learning is constrained by the availability of labeled data, which are especially expensive to acquire in the field of digital pathology. Making use of open-source data for pre-training or using domain adaptation can be a way to overcome this issue. However, pre-trained networks often fail to generalize to new test domains that are not distributed identically due to variations in tissue stainings, types, and textures. Additionally, current domain adaptation methods mainly rely on fully-labeled source datasets. In this work, we propose SRA, which takes advantage of self-supervised learning to perform domain adaptation and removes the necessity of a fully-labeled source dataset. SRA can effectively transfer the discriminative knowledge obtained from a few labeled source domain's data to a new target domain without requiring additional tissue annotations. Our method harnesses both domains' structures by capturing visual similarity with intra-domain and cross-domain self-supervision. Moreover, we present a generalized formulation of our approach that allows the architecture to learn from multi-source domains. We show that our proposed method outperforms baselines for domain adaptation of colorectal tissue type classification and further validate our approach on our in-house clinical cohort. The code and models are available open-source: https://github.com/christianabbet/SRA.
Divide-and-Rule: Self-Supervised Learning for Survival Analysis in Colorectal Cancer
Jul 07, 2020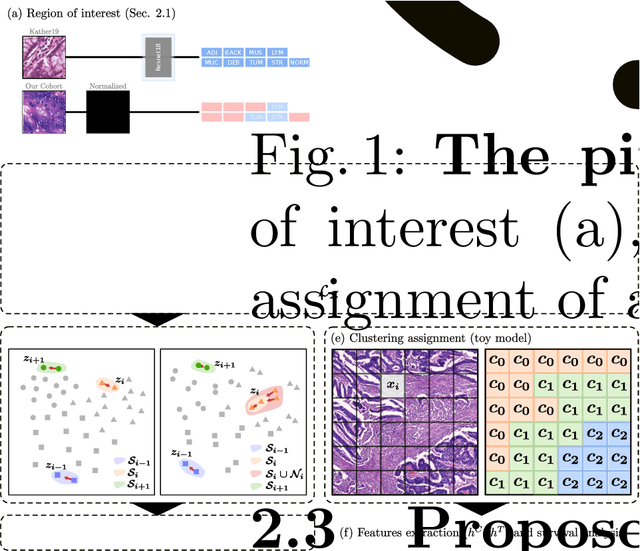
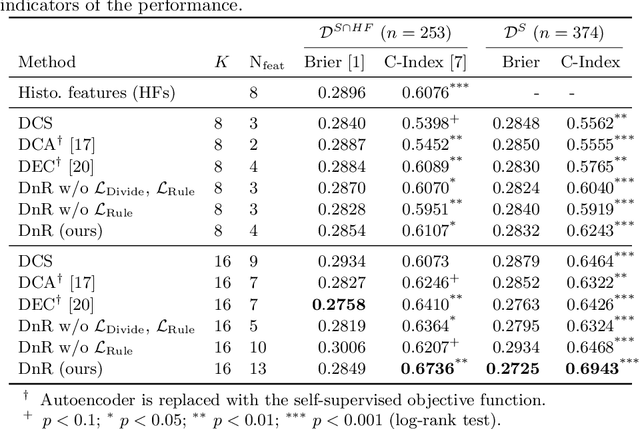
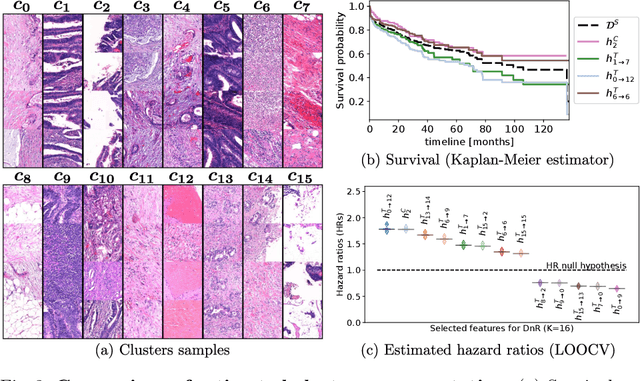
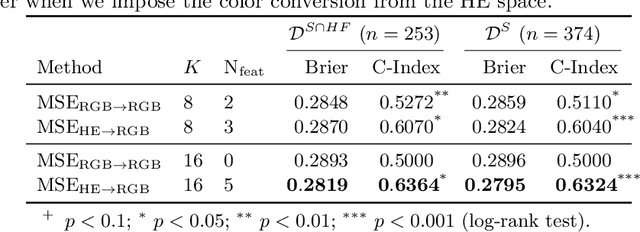
With the long-term rapid increase in incidences of colorectal cancer (CRC), there is an urgent clinical need to improve risk stratification. The conventional pathology report is usually limited to only a few histopathological features. However, most of the tumor microenvironments used to describe patterns of aggressive tumor behavior are ignored. In this work, we aim to learn histopathological patterns within cancerous tissue regions that can be used to improve prognostic stratification for colorectal cancer. To do so, we propose a self-supervised learning method that jointly learns a representation of tissue regions as well as a metric of the clustering to obtain their underlying patterns. These histopathological patterns are then used to represent the interaction between complex tissues and predict clinical outcomes directly. We furthermore show that the proposed approach can benefit from linear predictors to avoid overfitting in patient outcomes predictions. To this end, we introduce a new well-characterized clinicopathological dataset, including a retrospective collective of 374 patients, with their survival time and treatment information. Histomorphological clusters obtained by our method are evaluated by training survival models. The experimental results demonstrate statistically significant patient stratification, and our approach outperformed the state-of-the-art deep clustering methods.
Churn Intent Detection in Multilingual Chatbot Conversations and Social Media
Aug 25, 2018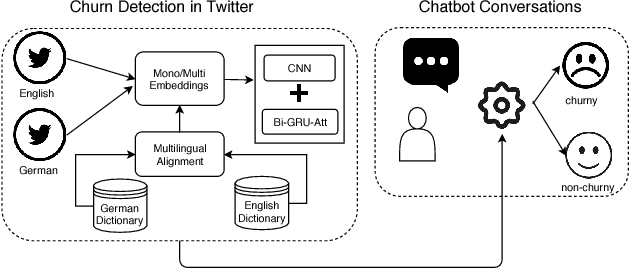


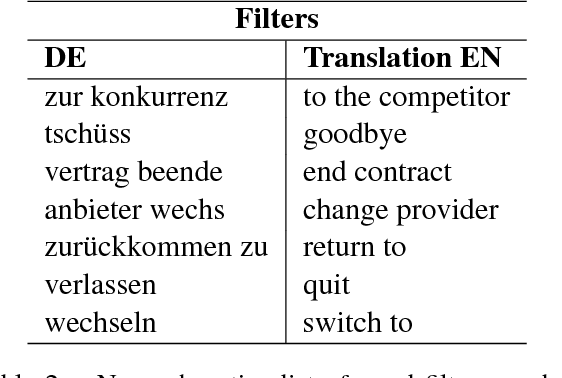
We propose a new method to detect when users express the intent to leave a service, also known as churn. While previous work focuses solely on social media, we show that this intent can be detected in chatbot conversations. As companies increasingly rely on chatbots they need an overview of potentially churny users. To this end, we crowdsource and publish a dataset of churn intent expressions in chatbot interactions in German and English. We show that classifiers trained on social media data can detect the same intent in the context of chatbots. We introduce a classification architecture that outperforms existing work on churn intent detection in social media. Moreover, we show that, using bilingual word embeddings, a system trained on combined English and German data outperforms monolingual approaches. As the only existing dataset is in English, we crowdsource and publish a novel dataset of German tweets. We thus underline the universal aspect of the problem, as examples of churn intent in English help us identify churn in German tweets and chatbot conversations.