 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResilient Combination of Complementary CNN and RNN Features for Text Classification through Attention and Ensembling
Mar 28, 2019

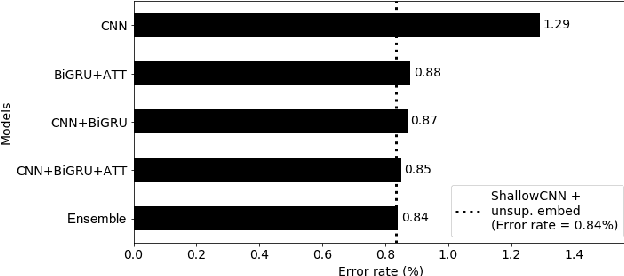
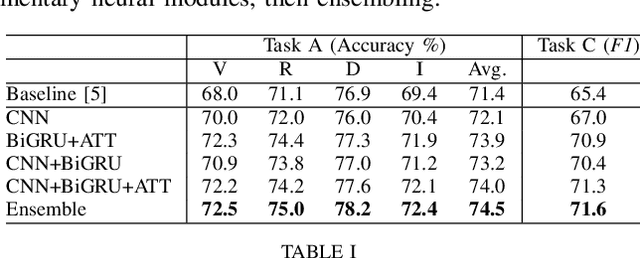
State-of-the-art methods for text classification include several distinct steps of pre-processing, feature extraction and post-processing. In this work, we focus on end-to-end neural architectures and show that the best performance in text classification is obtained by combining information from different neural modules. Concretely, we combine convolution, recurrent and attention modules with ensemble methods and show that they are complementary. We introduce ECGA, an end-to-end go-to architecture for novel text classification tasks. We prove that it is efficient and robust, as it attains or surpasses the state-of-the-art on varied datasets, including both low and high data regimes.
Churn Intent Detection in Multilingual Chatbot Conversations and Social Media
Aug 25, 2018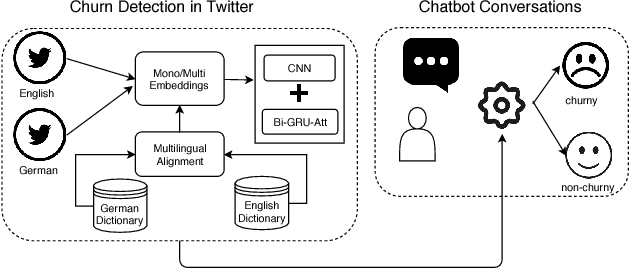


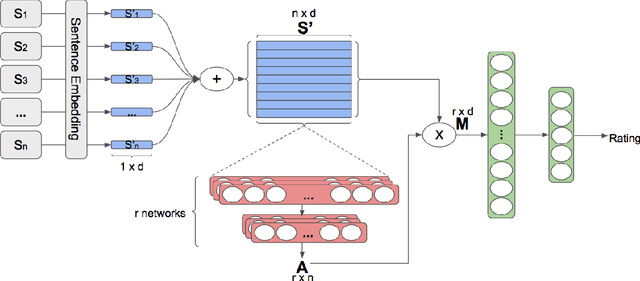
We propose a new method to detect when users express the intent to leave a service, also known as churn. While previous work focuses solely on social media, we show that this intent can be detected in chatbot conversations. As companies increasingly rely on chatbots they need an overview of potentially churny users. To this end, we crowdsource and publish a dataset of churn intent expressions in chatbot interactions in German and English. We show that classifiers trained on social media data can detect the same intent in the context of chatbots. We introduce a classification architecture that outperforms existing work on churn intent detection in social media. Moreover, we show that, using bilingual word embeddings, a system trained on combined English and German data outperforms monolingual approaches. As the only existing dataset is in English, we crowdsource and publish a novel dataset of German tweets. We thus underline the universal aspect of the problem, as examples of churn intent in English help us identify churn in German tweets and chatbot conversations.
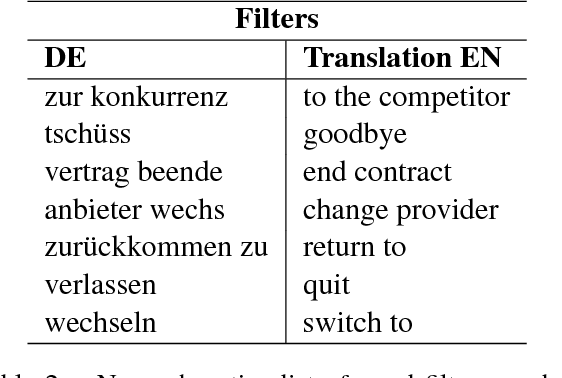
Dataset Construction via Attention for Aspect Term Extraction with Distant Supervision
Sep 26, 2017
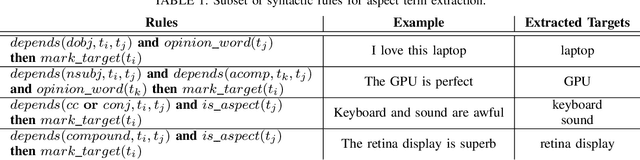
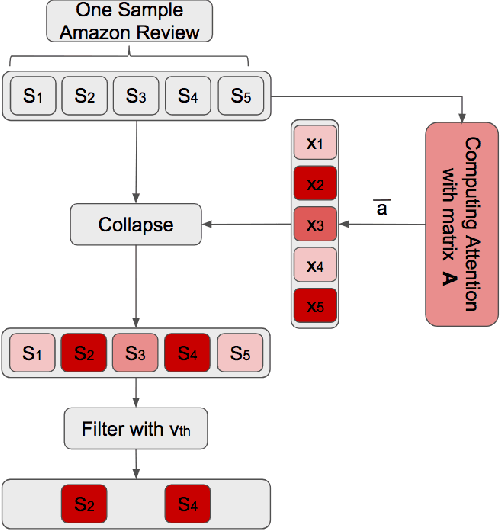
Aspect Term Extraction (ATE) detects opinionated aspect terms in sentences or text spans, with the end goal of performing aspect-based sentiment analysis. The small amount of available datasets for supervised ATE and the fact that they cover only a few domains raise the need for exploiting other data sources in new and creative ways. Publicly available review corpora contain a plethora of opinionated aspect terms and cover a larger domain spectrum. In this paper, we first propose a method for using such review corpora for creating a new dataset for ATE. Our method relies on an attention mechanism to select sentences that have a high likelihood of containing actual opinionated aspects. We thus improve the quality of the extracted aspects. We then use the constructed dataset to train a model and perform ATE with distant supervision. By evaluating on human annotated datasets, we prove that our method achieves a significantly improved performance over various unsupervised and supervised baselines. Finally, we prove that sentence selection matters when it comes to creating new datasets for ATE. Specifically, we show that, using a set of selected sentences leads to higher ATE performance compared to using the whole sentence set.
Unsupervised Aspect Term Extraction with B-LSTM & CRF using Automatically Labelled Datasets
Sep 15, 2017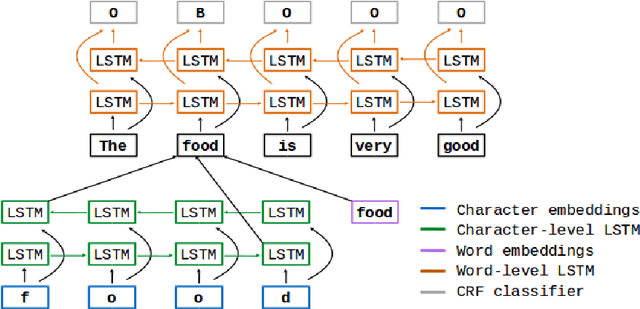
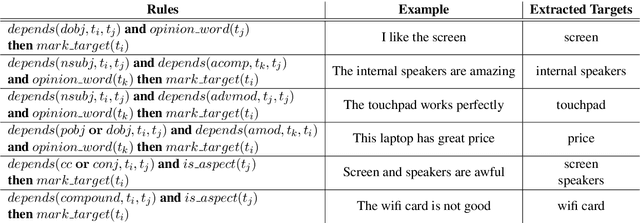
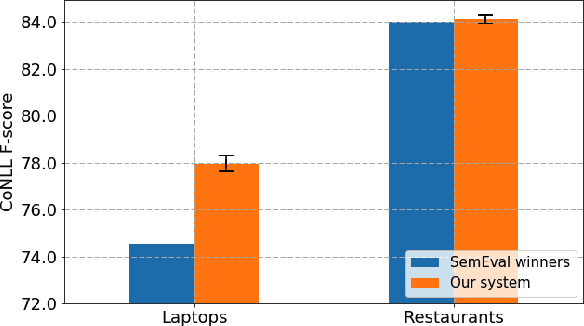
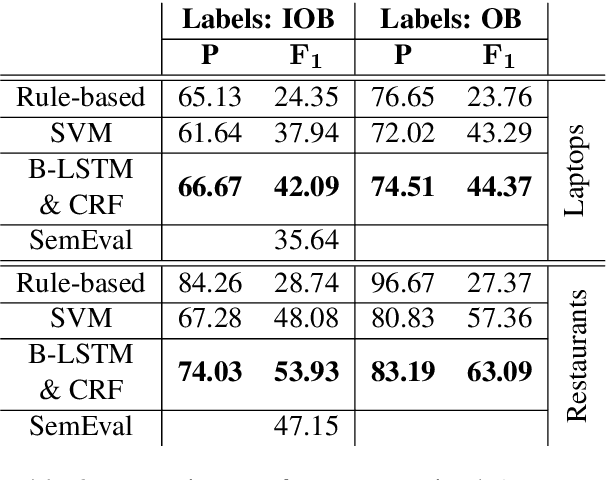
Aspect Term Extraction (ATE) identifies opinionated aspect terms in texts and is one of the tasks in the SemEval Aspect Based Sentiment Analysis (ABSA) contest. The small amount of available datasets for supervised ATE and the costly human annotation for aspect term labelling give rise to the need for unsupervised ATE. In this paper, we introduce an architecture that achieves top-ranking performance for supervised ATE. Moreover, it can be used efficiently as feature extractor and classifier for unsupervised ATE. Our second contribution is a method to automatically construct datasets for ATE. We train a classifier on our automatically labelled datasets and evaluate it on the human annotated SemEval ABSA test sets. Compared to a strong rule-based baseline, we obtain a dramatically higher F-score and attain precision values above 80%. Our unsupervised method beats the supervised ABSA baseline from SemEval, while preserving high precision scores.