Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResilient Combination of Complementary CNN and RNN Features for Text Classification through Attention and Ensembling
Paper and Code
Mar 28, 2019

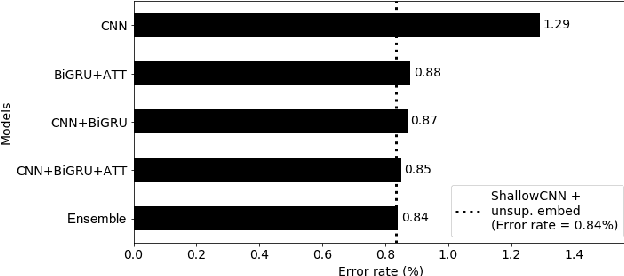
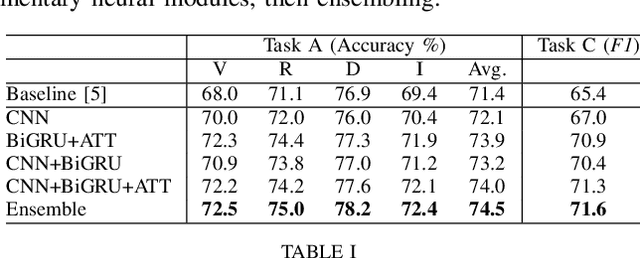
State-of-the-art methods for text classification include several distinct steps of pre-processing, feature extraction and post-processing. In this work, we focus on end-to-end neural architectures and show that the best performance in text classification is obtained by combining information from different neural modules. Concretely, we combine convolution, recurrent and attention modules with ensemble methods and show that they are complementary. We introduce ECGA, an end-to-end go-to architecture for novel text classification tasks. We prove that it is efficient and robust, as it attains or surpasses the state-of-the-art on varied datasets, including both low and high data regimes.
* 5 pages, 1 figure, SDS 2019 - The 6th Swiss Conference on Data
Science
View paper on