 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResilient Combination of Complementary CNN and RNN Features for Text Classification through Attention and Ensembling
Mar 28, 2019

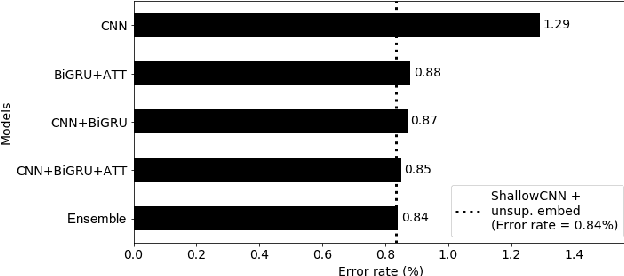
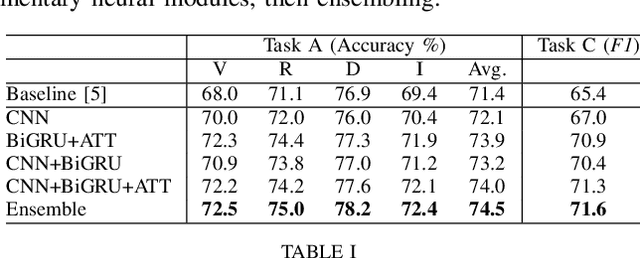
State-of-the-art methods for text classification include several distinct steps of pre-processing, feature extraction and post-processing. In this work, we focus on end-to-end neural architectures and show that the best performance in text classification is obtained by combining information from different neural modules. Concretely, we combine convolution, recurrent and attention modules with ensemble methods and show that they are complementary. We introduce ECGA, an end-to-end go-to architecture for novel text classification tasks. We prove that it is efficient and robust, as it attains or surpasses the state-of-the-art on varied datasets, including both low and high data regimes.
Expanding the Text Classification Toolbox with Cross-Lingual Embeddings
Mar 26, 2019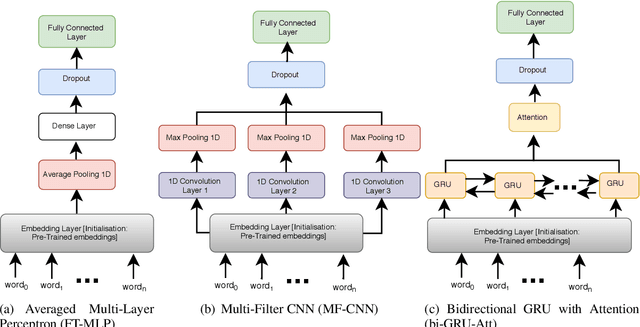

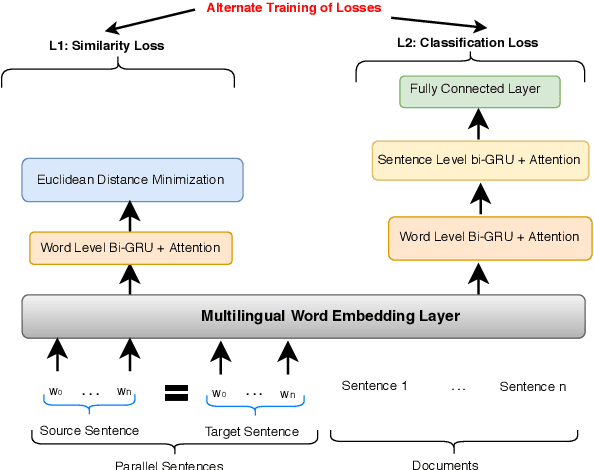
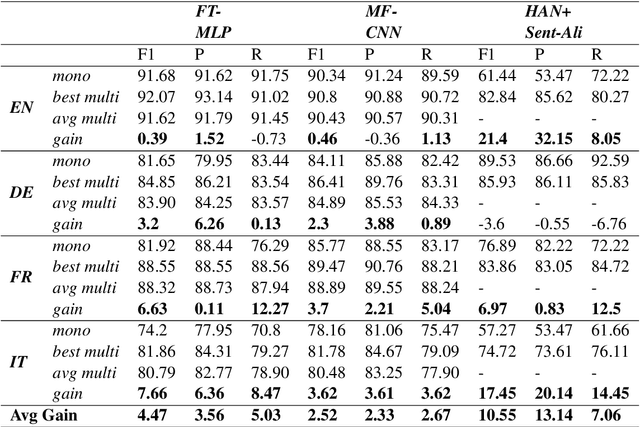
Most work in text classification and Natural Language Processing (NLP) focuses on English or a handful of other languages that have text corpora of hundreds of millions of words. This is creating a new version of the digital divide: the artificial intelligence (AI) divide. Transfer-based approaches, such as Cross-Lingual Text Classification (CLTC) - the task of categorizing texts written in different languages into a common taxonomy, are a promising solution to the emerging AI divide. Recent work on CLTC has focused on demonstrating the benefits of using bilingual word embeddings as features, relegating the CLTC problem to a mere benchmark based on a simple averaged perceptron. In this paper, we explore more extensively and systematically two flavors of the CLTC problem: news topic classification and textual churn intent detection (TCID) in social media. In particular, we test the hypothesis that embeddings with context are more effective, by multi-tasking the learning of multilingual word embeddings and text classification; we explore neural architectures for CLTC; and we move from bi- to multi-lingual word embeddings. For all architectures, types of word embeddings and datasets, we notice a consistent gain trend in favor of multilingual joint training, especially for low-resourced languages.
Embedding Individual Table Columns for Resilient SQL Chatbots
Nov 01, 2018
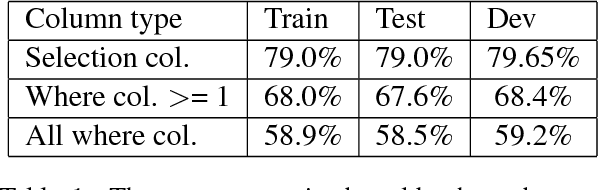
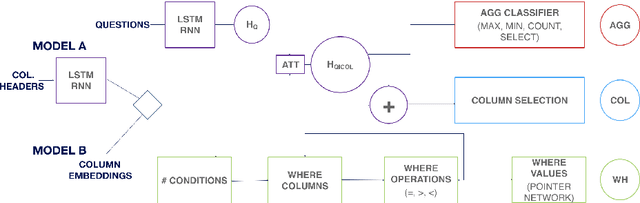

Most of the world's data is stored in relational databases. Accessing these requires specialized knowledge of the Structured Query Language (SQL), putting them out of the reach of many people. A recent research thread in Natural Language Processing (NLP) aims to alleviate this problem by automatically translating natural language questions into SQL queries. While the proposed solutions are a great start, they lack robustness and do not easily generalize: the methods require high quality descriptions of the database table columns, and the most widely used training dataset, WikiSQL, is heavily biased towards using those descriptions as part of the questions. In this work, we propose solutions to both problems: we entirely eliminate the need for column descriptions, by relying solely on their contents, and we augment the WikiSQL dataset by paraphrasing column names to reduce bias. We show that the accuracy of existing methods drops when trained on our augmented, column-agnostic dataset, and that our own method reaches state of the art accuracy, while relying on column contents only.
Simple Unsupervised Keyphrase Extraction using Sentence Embeddings
Sep 05, 2018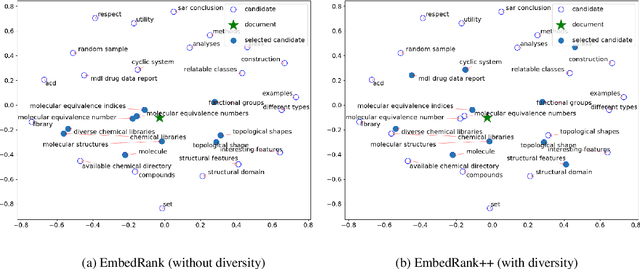

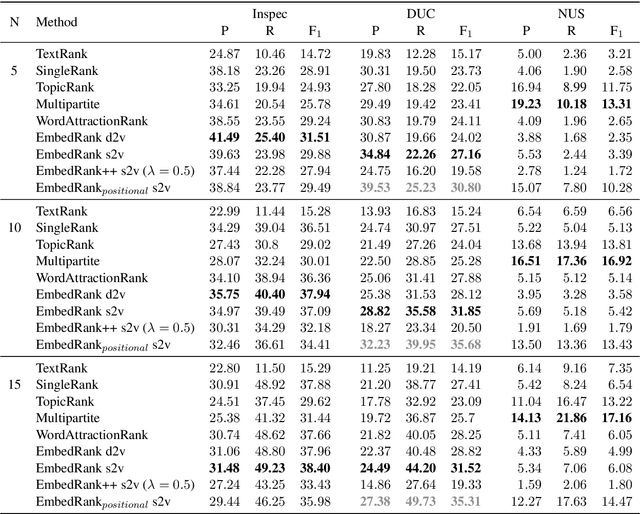
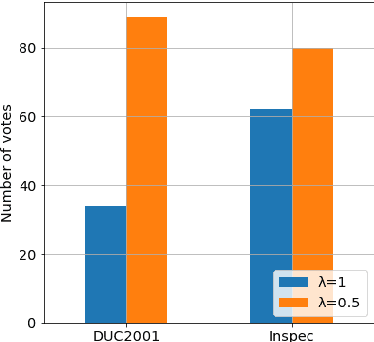
Keyphrase extraction is the task of automatically selecting a small set of phrases that best describe a given free text document. Supervised keyphrase extraction requires large amounts of labeled training data and generalizes very poorly outside the domain of the training data. At the same time, unsupervised systems have poor accuracy, and often do not generalize well, as they require the input document to belong to a larger corpus also given as input. Addressing these drawbacks, in this paper, we tackle keyphrase extraction from single documents with EmbedRank: a novel unsupervised method, that leverages sentence embeddings. EmbedRank achieves higher F-scores than graph-based state of the art systems on standard datasets and is suitable for real-time processing of large amounts of Web data. With EmbedRank, we also explicitly increase coverage and diversity among the selected keyphrases by introducing an embedding-based maximal marginal relevance (MMR) for new phrases. A user study including over 200 votes showed that, although reducing the phrases' semantic overlap leads to no gains in F-score, our high diversity selection is preferred by humans.
Churn Intent Detection in Multilingual Chatbot Conversations and Social Media
Aug 25, 2018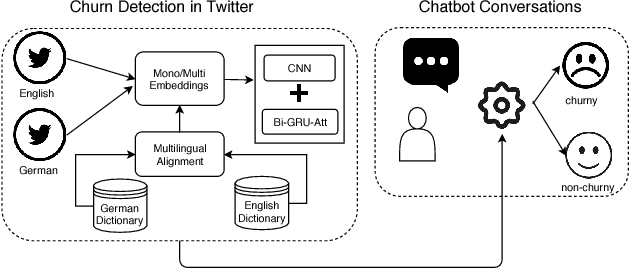


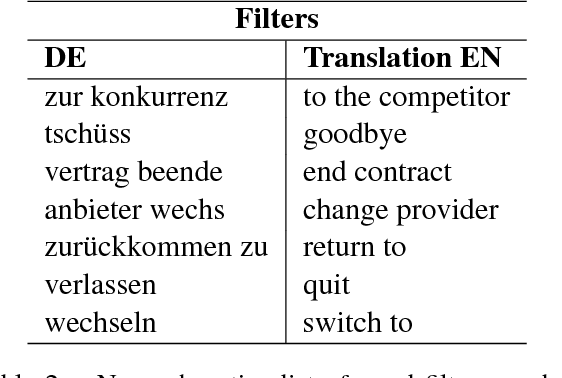
We propose a new method to detect when users express the intent to leave a service, also known as churn. While previous work focuses solely on social media, we show that this intent can be detected in chatbot conversations. As companies increasingly rely on chatbots they need an overview of potentially churny users. To this end, we crowdsource and publish a dataset of churn intent expressions in chatbot interactions in German and English. We show that classifiers trained on social media data can detect the same intent in the context of chatbots. We introduce a classification architecture that outperforms existing work on churn intent detection in social media. Moreover, we show that, using bilingual word embeddings, a system trained on combined English and German data outperforms monolingual approaches. As the only existing dataset is in English, we crowdsource and publish a novel dataset of German tweets. We thus underline the universal aspect of the problem, as examples of churn intent in English help us identify churn in German tweets and chatbot conversations.
Goal-Oriented Chatbot Dialog Management Bootstrapping with Transfer Learning
Jul 24, 2018
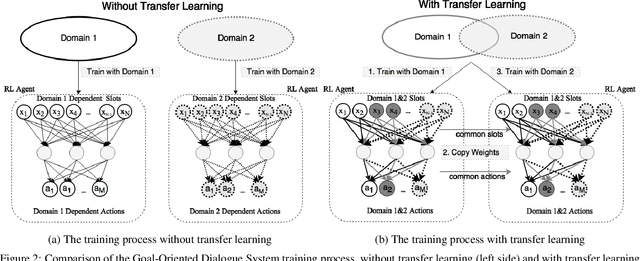
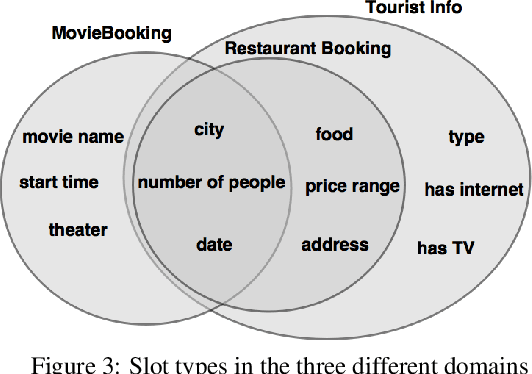
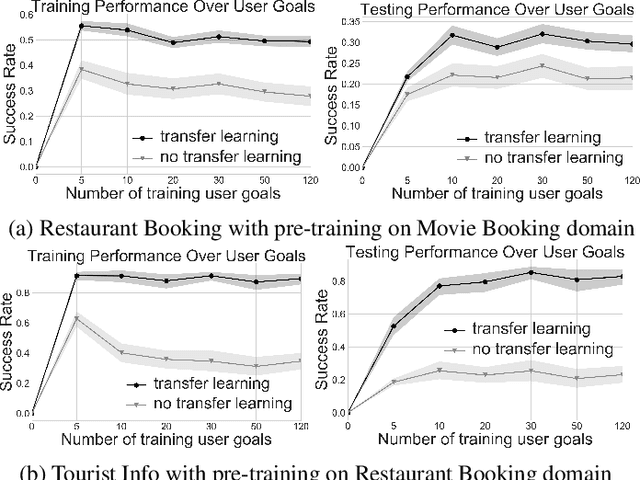
Goal-Oriented (GO) Dialogue Systems, colloquially known as goal oriented chatbots, help users achieve a predefined goal (e.g. book a movie ticket) within a closed domain. A first step is to understand the user's goal by using natural language understanding techniques. Once the goal is known, the bot must manage a dialogue to achieve that goal, which is conducted with respect to a learnt policy. The success of the dialogue system depends on the quality of the policy, which is in turn reliant on the availability of high-quality training data for the policy learning method, for instance Deep Reinforcement Learning. Due to the domain specificity, the amount of available data is typically too low to allow the training of good dialogue policies. In this paper we introduce a transfer learning method to mitigate the effects of the low in-domain data availability. Our transfer learning based approach improves the bot's success rate by 20% in relative terms for distant domains and we more than double it for close domains, compared to the model without transfer learning. Moreover, the transfer learning chatbots learn the policy up to 5 to 10 times faster. Finally, as the transfer learning approach is complementary to additional processing such as warm-starting, we show that their joint application gives the best outcomes.
Submodularity-Inspired Data Selection for Goal-Oriented Chatbot Training Based on Sentence Embeddings
Jul 08, 2018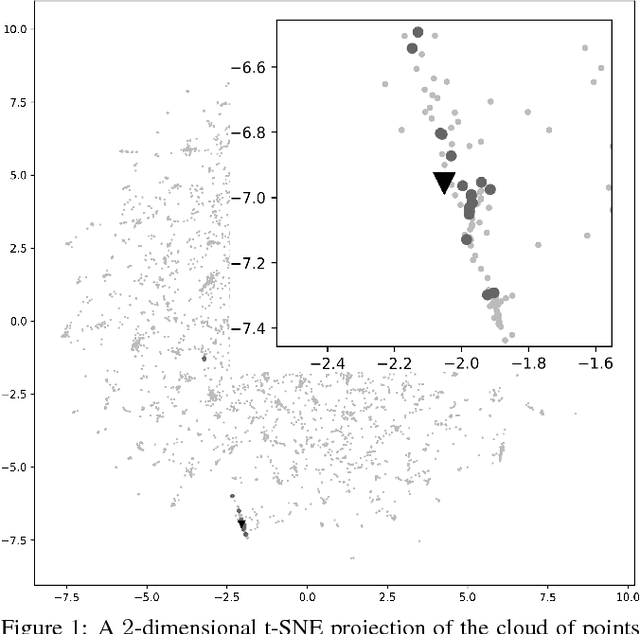
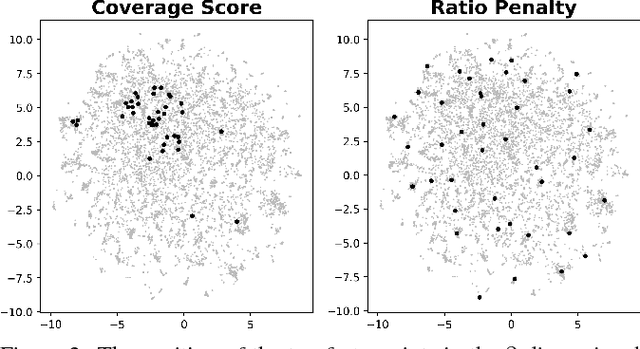


Spoken language understanding (SLU) systems, such as goal-oriented chatbots or personal assistants, rely on an initial natural language understanding (NLU) module to determine the intent and to extract the relevant information from the user queries they take as input. SLU systems usually help users to solve problems in relatively narrow domains and require a large amount of in-domain training data. This leads to significant data availability issues that inhibit the development of successful systems. To alleviate this problem, we propose a technique of data selection in the low-data regime that enables us to train with fewer labeled sentences, thus smaller labelling costs. We propose a submodularity-inspired data ranking function, the ratio-penalty marginal gain, for selecting data points to label based only on the information extracted from the textual embedding space. We show that the distances in the embedding space are a viable source of information that can be used for data selection. Our method outperforms two known active learning techniques and enables cost-efficient training of the NLU unit. Moreover, our proposed selection technique does not need the model to be retrained in between the selection steps, making it time efficient as well.
GitGraph - Architecture Search Space Creation through Frequent Computational Subgraph Mining
Jan 16, 2018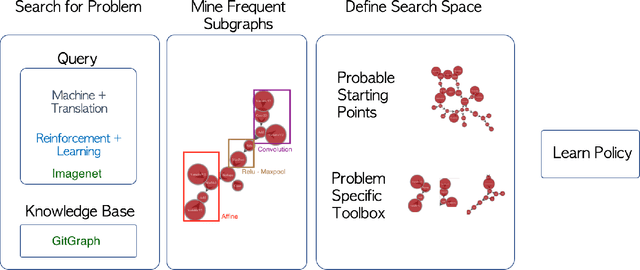
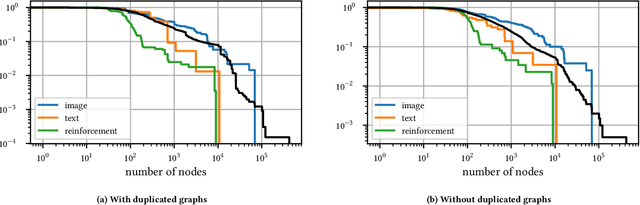
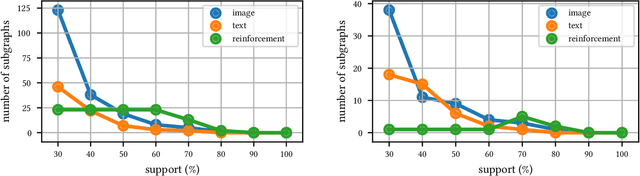
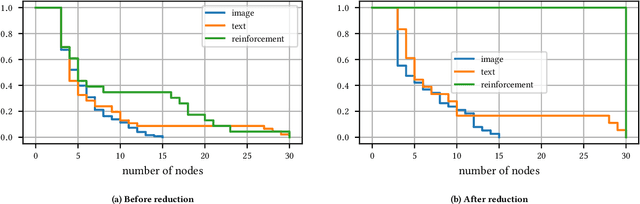
The dramatic success of deep neural networks across multiple application areas often relies on experts painstakingly designing a network architecture specific to each task. To simplify this process and make it more accessible, an emerging research effort seeks to automate the design of neural network architectures, using e.g. evolutionary algorithms or reinforcement learning or simple search in a constrained space of neural modules. Considering the typical size of the search space (e.g. $10^{10}$ candidates for a $10$-layer network) and the cost of evaluating a single candidate, current architecture search methods are very restricted. They either rely on static pre-built modules to be recombined for the task at hand, or they define a static hand-crafted framework within which they can generate new architectures from the simplest possible operations. In this paper, we relax these restrictions, by capitalizing on the collective wisdom contained in the plethora of neural networks published in online code repositories. Concretely, we (a) extract and publish GitGraph, a corpus of neural architectures and their descriptions; (b) we create problem-specific neural architecture search spaces, implemented as a textual search mechanism over GitGraph; (c) we propose a method of identifying unique common subgraphs within the architectures solving each problem (e.g., image processing, reinforcement learning), that can then serve as modules in the newly created problem specific neural search space.
Dataset Construction via Attention for Aspect Term Extraction with Distant Supervision
Sep 26, 2017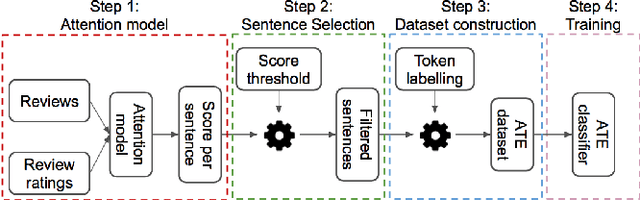
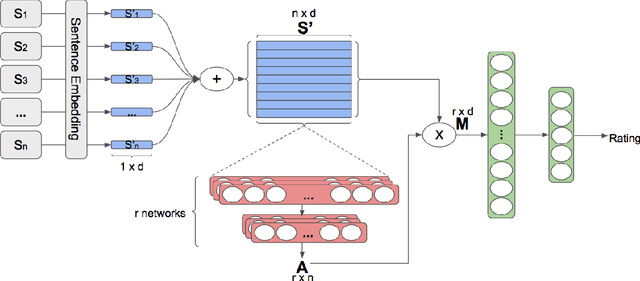
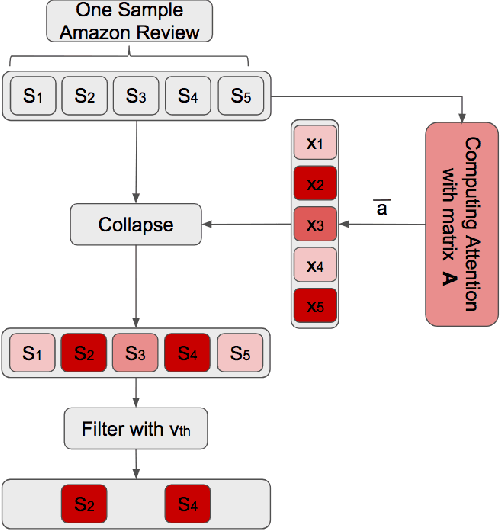
Aspect Term Extraction (ATE) detects opinionated aspect terms in sentences or text spans, with the end goal of performing aspect-based sentiment analysis. The small amount of available datasets for supervised ATE and the fact that they cover only a few domains raise the need for exploiting other data sources in new and creative ways. Publicly available review corpora contain a plethora of opinionated aspect terms and cover a larger domain spectrum. In this paper, we first propose a method for using such review corpora for creating a new dataset for ATE. Our method relies on an attention mechanism to select sentences that have a high likelihood of containing actual opinionated aspects. We thus improve the quality of the extracted aspects. We then use the constructed dataset to train a model and perform ATE with distant supervision. By evaluating on human annotated datasets, we prove that our method achieves a significantly improved performance over various unsupervised and supervised baselines. Finally, we prove that sentence selection matters when it comes to creating new datasets for ATE. Specifically, we show that, using a set of selected sentences leads to higher ATE performance compared to using the whole sentence set.
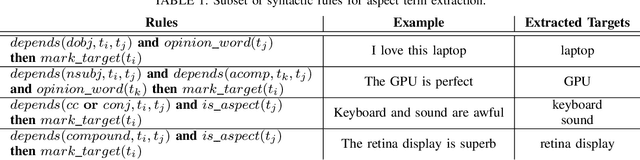
Unsupervised Aspect Term Extraction with B-LSTM & CRF using Automatically Labelled Datasets
Sep 15, 2017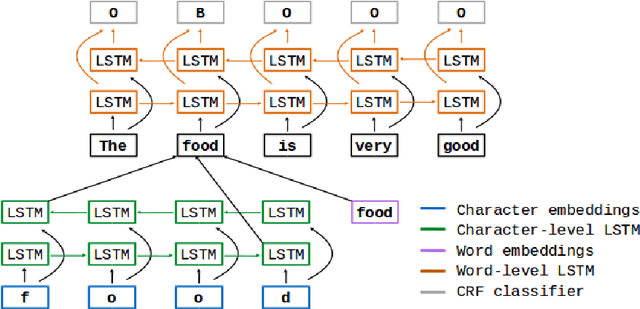
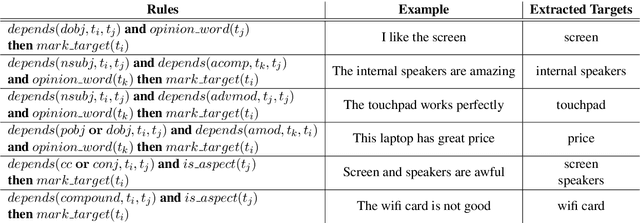
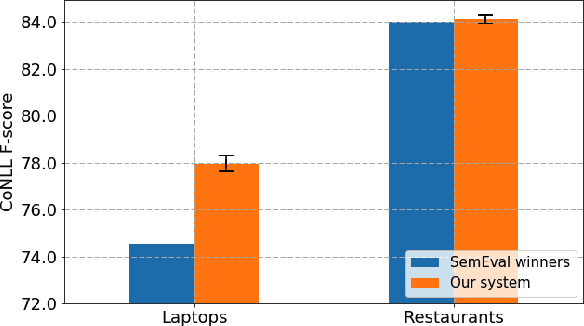
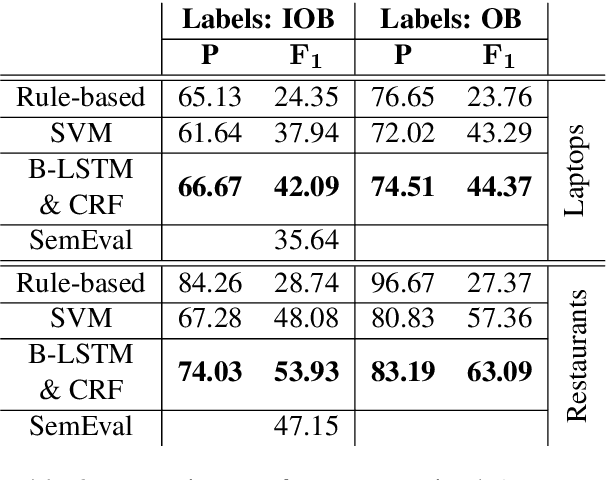
Aspect Term Extraction (ATE) identifies opinionated aspect terms in texts and is one of the tasks in the SemEval Aspect Based Sentiment Analysis (ABSA) contest. The small amount of available datasets for supervised ATE and the costly human annotation for aspect term labelling give rise to the need for unsupervised ATE. In this paper, we introduce an architecture that achieves top-ranking performance for supervised ATE. Moreover, it can be used efficiently as feature extractor and classifier for unsupervised ATE. Our second contribution is a method to automatically construct datasets for ATE. We train a classifier on our automatically labelled datasets and evaluate it on the human annotated SemEval ABSA test sets. Compared to a strong rule-based baseline, we obtain a dramatically higher F-score and attain precision values above 80%. Our unsupervised method beats the supervised ABSA baseline from SemEval, while preserving high precision scores.