 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Multi-Model Forgetting
Mar 02, 2019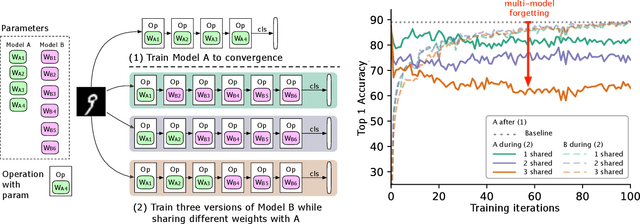
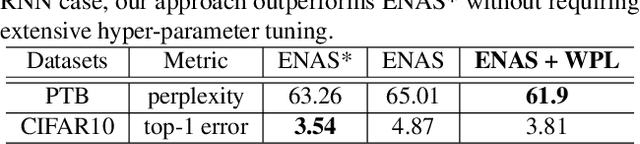
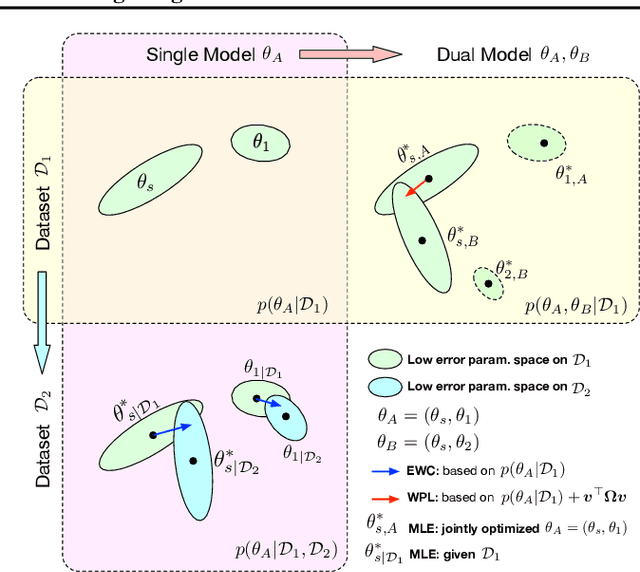
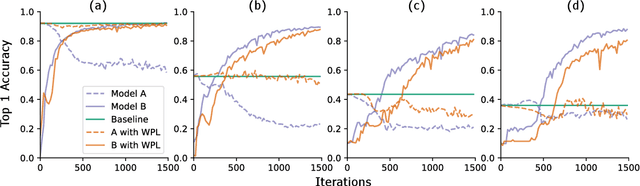
We identify a phenomenon, which we refer to as multi-model forgetting, that occurs when sequentially training multiple deep networks with partially-shared parameters; the performance of previously-trained models degrades as one optimizes a subsequent one, due to the overwriting of shared parameters. To overcome this, we introduce a statistically-justified weight plasticity loss that regularizes the learning of a model's shared parameters according to their importance for the previous models, and demonstrate its effectiveness when training two models sequentially and for neural architecture search. Adding weight plasticity in neural architecture search preserves the best models to the end of the search and yields improved results in both natural language processing and computer vision tasks.
Simple Unsupervised Keyphrase Extraction using Sentence Embeddings
Sep 05, 2018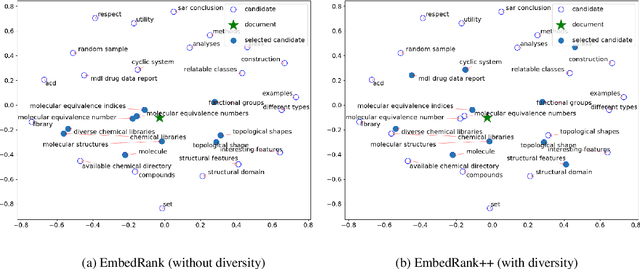

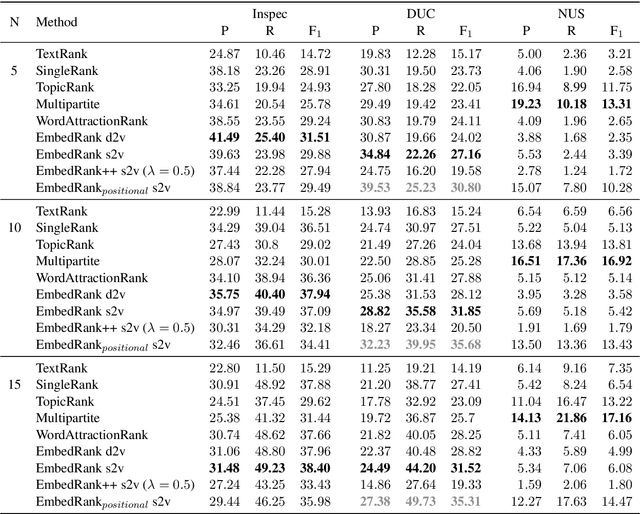
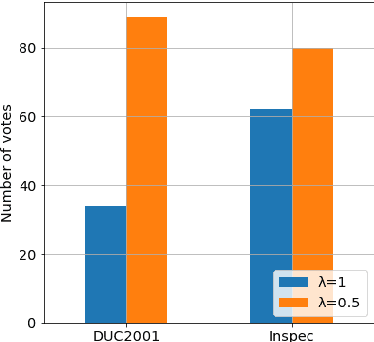
Keyphrase extraction is the task of automatically selecting a small set of phrases that best describe a given free text document. Supervised keyphrase extraction requires large amounts of labeled training data and generalizes very poorly outside the domain of the training data. At the same time, unsupervised systems have poor accuracy, and often do not generalize well, as they require the input document to belong to a larger corpus also given as input. Addressing these drawbacks, in this paper, we tackle keyphrase extraction from single documents with EmbedRank: a novel unsupervised method, that leverages sentence embeddings. EmbedRank achieves higher F-scores than graph-based state of the art systems on standard datasets and is suitable for real-time processing of large amounts of Web data. With EmbedRank, we also explicitly increase coverage and diversity among the selected keyphrases by introducing an embedding-based maximal marginal relevance (MMR) for new phrases. A user study including over 200 votes showed that, although reducing the phrases' semantic overlap leads to no gains in F-score, our high diversity selection is preferred by humans.
GitGraph - Architecture Search Space Creation through Frequent Computational Subgraph Mining
Jan 16, 2018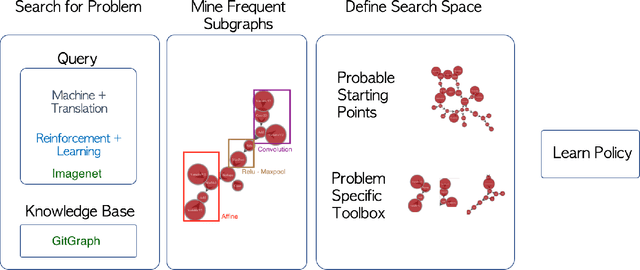
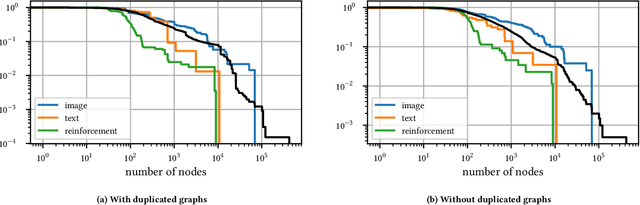
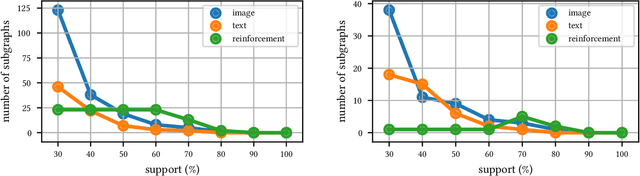
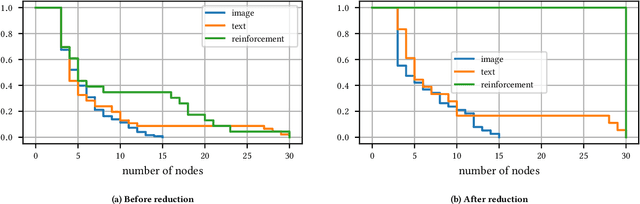
The dramatic success of deep neural networks across multiple application areas often relies on experts painstakingly designing a network architecture specific to each task. To simplify this process and make it more accessible, an emerging research effort seeks to automate the design of neural network architectures, using e.g. evolutionary algorithms or reinforcement learning or simple search in a constrained space of neural modules. Considering the typical size of the search space (e.g. $10^{10}$ candidates for a $10$-layer network) and the cost of evaluating a single candidate, current architecture search methods are very restricted. They either rely on static pre-built modules to be recombined for the task at hand, or they define a static hand-crafted framework within which they can generate new architectures from the simplest possible operations. In this paper, we relax these restrictions, by capitalizing on the collective wisdom contained in the plethora of neural networks published in online code repositories. Concretely, we (a) extract and publish GitGraph, a corpus of neural architectures and their descriptions; (b) we create problem-specific neural architecture search spaces, implemented as a textual search mechanism over GitGraph; (c) we propose a method of identifying unique common subgraphs within the architectures solving each problem (e.g., image processing, reinforcement learning), that can then serve as modules in the newly created problem specific neural search space.