 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel-wise Vector Quantization
May 25, 2026We present Channel-wise Vector Quantization (CVQ), a novel image tokenization paradigm that replaces patch-wise tokens with channel-wise tokens. Unlike conventional vector quantization, which assigns a discrete token to each patch feature vector, CVQ quantizes each channel of the feature map. This formulation represents an image as discrete levels of visual details, rather than as a grid of spatial patches. Based on CVQ, we introduce a new visual autoregressive framework with "next-channel prediction". Instead of rendering images patch by patch in raster order, our Channel-wise Autoregressive (CAR) model predicts image channels sequentially, producing progressively enriched visual details. Specifically, it first sketches global structure and then refines fine-grained attributes, akin to a human artist's workflow. Empirically, we show that: (1) CVQ achieves 100% codebook utilization with a 16K+ codebook size without any bells and whistles, and substantially improves reconstruction quality over conventional VQ; and (2) CAR attains a DPG score of 86.7 and a GenEval score of 0.79, demonstrating strong effectiveness for text-to-image generation.
DriveCombo: Benchmarking Compositional Traffic Rule Reasoning in Autonomous Driving
Mar 02, 2026Multimodal Large Language Models (MLLMs) are rapidly becoming the intelligence brain of end-to-end autonomous driving systems. A key challenge is to assess whether MLLMs can truly understand and follow complex real-world traffic rules. However, existing benchmarks mainly focus on single-rule scenarios like traffic sign recognition, neglecting the complexity of multi-rule concurrency and conflicts in real driving. Consequently, models perform well on simple tasks but often fail or violate rules in real world complex situations. To bridge this gap, we propose DriveCombo, a text and vision-based benchmark for compositional traffic rule reasoning. Inspired by human drivers' cognitive development, we propose a systematic Five-Level Cognitive Ladder that evaluates reasoning from single-rule understanding to multi-rule integration and conflict resolution, enabling quantitative assessment across cognitive stages. We further propose a Rule2Scene Agent that maps language-based traffic rules to dynamic driving scenes through rule crafting and scene generation, enabling scene-level traffic rule visual reasoning. Evaluations of 14 mainstream MLLMs reveal performance drops as task complexity grows, particularly during rule conflicts. After splitting the dataset and fine-tuning on the training set, we further observe substantial improvements in both traffic rule reasoning and downstream planning capabilities. These results highlight the effectiveness of DriveCombo in advancing compliant and intelligent autonomous driving systems.
DeepGen 1.0: A Lightweight Unified Multimodal Model for Advancing Image Generation and Editing
Feb 13, 2026Current unified multimodal models for image generation and editing typically rely on massive parameter scales (e.g., >10B), entailing prohibitive training costs and deployment footprints. In this work, we present DeepGen 1.0, a lightweight 5B unified model that achieves comprehensive capabilities competitive with or surpassing much larger counterparts. To overcome the limitations of compact models in semantic understanding and fine-grained control, we introduce Stacked Channel Bridging (SCB), a deep alignment framework that extracts hierarchical features from multiple VLM layers and fuses them with learnable 'think tokens' to provide the generative backbone with structured, reasoning-rich guidance. We further design a data-centric training strategy spanning three progressive stages: (1) Alignment Pre-training on large-scale image-text pairs and editing triplets to synchronize VLM and DiT representations, (2) Joint Supervised Fine-tuning on a high-quality mixture of generation, editing, and reasoning tasks to foster omni-capabilities, and (3) Reinforcement Learning with MR-GRPO, which leverages a mixture of reward functions and supervision signals, resulting in substantial gains in generation quality and alignment with human preferences, while maintaining stable training progress and avoiding visual artifacts. Despite being trained on only ~50M samples, DeepGen 1.0 achieves leading performance across diverse benchmarks, surpassing the 80B HunyuanImage by 28% on WISE and the 27B Qwen-Image-Edit by 37% on UniREditBench. By open-sourcing our training code, weights, and datasets, we provide an efficient, high-performance alternative to democratize unified multimodal research.
OmniGen: Unified Multimodal Sensor Generation for Autonomous Driving
Dec 16, 2025Autonomous driving has seen remarkable advancements, largely driven by extensive real-world data collection. However, acquiring diverse and corner-case data remains costly and inefficient. Generative models have emerged as a promising solution by synthesizing realistic sensor data. However, existing approaches primarily focus on single-modality generation, leading to inefficiencies and misalignment in multimodal sensor data. To address these challenges, we propose OminiGen, which generates aligned multimodal sensor data in a unified framework. Our approach leverages a shared Bird\u2019s Eye View (BEV) space to unify multimodal features and designs a novel generalizable multimodal reconstruction method, UAE, to jointly decode LiDAR and multi-view camera data. UAE achieves multimodal sensor decoding through volume rendering, enabling accurate and flexible reconstruction. Furthermore, we incorporate a Diffusion Transformer (DiT) with a ControlNet branch to enable controllable multimodal sensor generation. Our comprehensive experiments demonstrate that OminiGen achieves desired performances in unified multimodal sensor data generation with multimodal consistency and flexible sensor adjustments.
CorrectAD: A Self-Correcting Agentic System to Improve End-to-end Planning in Autonomous Driving
Nov 17, 2025End-to-end planning methods are the de facto standard of the current autonomous driving system, while the robustness of the data-driven approaches suffers due to the notorious long-tail problem (i.e., rare but safety-critical failure cases). In this work, we explore whether recent diffusion-based video generation methods (a.k.a. world models), paired with structured 3D layouts, can enable a fully automated pipeline to self-correct such failure cases. We first introduce an agent to simulate the role of product manager, dubbed PM-Agent, which formulates data requirements to collect data similar to the failure cases. Then, we use a generative model that can simulate both data collection and annotation. However, existing generative models struggle to generate high-fidelity data conditioned on 3D layouts. To address this, we propose DriveSora, which can generate spatiotemporally consistent videos aligned with the 3D annotations requested by PM-Agent. We integrate these components into our self-correcting agentic system, CorrectAD. Importantly, our pipeline is an end-to-end model-agnostic and can be applied to improve any end-to-end planner. Evaluated on both nuScenes and a more challenging in-house dataset across multiple end-to-end planners, CorrectAD corrects 62.5% and 49.8% of failure cases, reducing collision rates by 39% and 27%, respectively.
Autoregressive Semantic Visual Reconstruction Helps VLMs Understand Better
Jun 10, 2025
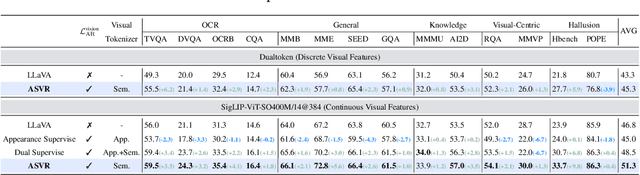
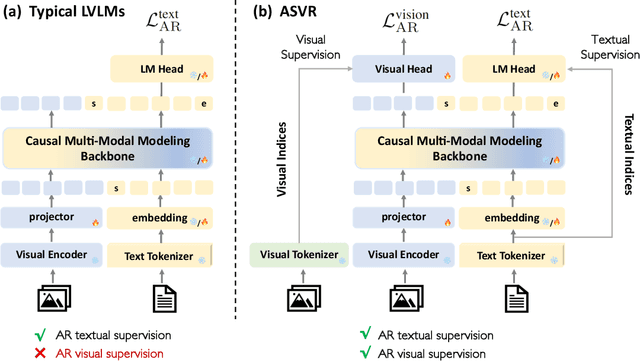
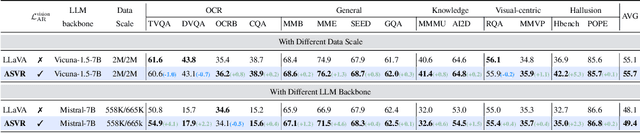
Typical large vision-language models (LVLMs) apply autoregressive supervision solely to textual sequences, without fully incorporating the visual modality into the learning process. This results in three key limitations: (1) an inability to utilize images without accompanying captions, (2) the risk that captions omit critical visual details, and (3) the challenge that certain vision-centric content cannot be adequately conveyed through text. As a result, current LVLMs often prioritize vision-to-language alignment while potentially overlooking fine-grained visual information. While some prior works have explored autoregressive image generation, effectively leveraging autoregressive visual supervision to enhance image understanding remains an open challenge. In this paper, we introduce Autoregressive Semantic Visual Reconstruction (ASVR), which enables joint learning of visual and textual modalities within a unified autoregressive framework. We show that autoregressively reconstructing the raw visual appearance of images does not enhance and may even impair multimodal understanding. In contrast, autoregressively reconstructing the semantic representation of images consistently improves comprehension. Notably, we find that even when models are given continuous image features as input, they can effectively reconstruct discrete semantic tokens, resulting in stable and consistent improvements across a wide range of multimodal understanding benchmarks. Our approach delivers significant performance gains across varying data scales (556k-2M) and types of LLM bacbones. Specifically, ASVR improves LLaVA-1.5 by 5% in average scores across 14 multimodal benchmarks. The code is available at https://github.com/AlenjandroWang/ASVR.
CVE-Bench: A Benchmark for AI Agents' Ability to Exploit Real-World Web Application Vulnerabilities
Mar 21, 2025



Large language model (LLM) agents are increasingly capable of autonomously conducting cyberattacks, posing significant threats to existing applications. This growing risk highlights the urgent need for a real-world benchmark to evaluate the ability of LLM agents to exploit web application vulnerabilities. However, existing benchmarks fall short as they are limited to abstracted Capture the Flag competitions or lack comprehensive coverage. Building a benchmark for real-world vulnerabilities involves both specialized expertise to reproduce exploits and a systematic approach to evaluating unpredictable threats. To address this challenge, we introduce CVE-Bench, a real-world cybersecurity benchmark based on critical-severity Common Vulnerabilities and Exposures. In CVE-Bench, we design a sandbox framework that enables LLM agents to exploit vulnerable web applications in scenarios that mimic real-world conditions, while also providing effective evaluation of their exploits. Our evaluation shows that the state-of-the-art agent framework can resolve up to 13% of vulnerabilities.
MiLA: Multi-view Intensive-fidelity Long-term Video Generation World Model for Autonomous Driving
Mar 20, 2025In recent years, data-driven techniques have greatly advanced autonomous driving systems, but the need for rare and diverse training data remains a challenge, requiring significant investment in equipment and labor. World models, which predict and generate future environmental states, offer a promising solution by synthesizing annotated video data for training. However, existing methods struggle to generate long, consistent videos without accumulating errors, especially in dynamic scenes. To address this, we propose MiLA, a novel framework for generating high-fidelity, long-duration videos up to one minute. MiLA utilizes a Coarse-to-Re(fine) approach to both stabilize video generation and correct distortion of dynamic objects. Additionally, we introduce a Temporal Progressive Denoising Scheduler and Joint Denoising and Correcting Flow modules to improve the quality of generated videos. Extensive experiments on the nuScenes dataset show that MiLA achieves state-of-the-art performance in video generation quality. For more information, visit the project website: https://github.com/xiaomi-mlab/mila.github.io.
DualToken: Towards Unifying Visual Understanding and Generation with Dual Visual Vocabularies
Mar 19, 2025The differing representation spaces required for visual understanding and generation pose a challenge in unifying them within the autoregressive paradigm of large language models. A vision tokenizer trained for reconstruction excels at capturing low-level perceptual details, making it well-suited for visual generation but lacking high-level semantic representations for understanding tasks. Conversely, a vision encoder trained via contrastive learning aligns well with language but struggles to decode back into the pixel space for generation tasks. To bridge this gap, we propose DualToken, a method that unifies representations for both understanding and generation within a single tokenizer. However, directly integrating reconstruction and semantic objectives in a single tokenizer creates conflicts, leading to degraded performance in both reconstruction quality and semantic performance. Instead of forcing a single codebook to handle both semantic and perceptual information, DualToken disentangles them by introducing separate codebooks for high and low-level features, effectively transforming their inherent conflict into a synergistic relationship. As a result, DualToken achieves state-of-the-art performance in both reconstruction and semantic tasks while demonstrating remarkable effectiveness in downstream MLLM understanding and generation tasks. Notably, we also show that DualToken, as a unified tokenizer, surpasses the naive combination of two distinct types vision encoders, providing superior performance within a unified MLLM.
Strategic priorities for transformative progress in advancing biology with proteomics and artificial intelligence
Feb 21, 2025

Artificial intelligence (AI) is transforming scientific research, including proteomics. Advances in mass spectrometry (MS)-based proteomics data quality, diversity, and scale, combined with groundbreaking AI techniques, are unlocking new challenges and opportunities in biological discovery. Here, we highlight key areas where AI is driving innovation, from data analysis to new biological insights. These include developing an AI-friendly ecosystem for proteomics data generation, sharing, and analysis; improving peptide and protein identification and quantification; characterizing protein-protein interactions and protein complexes; advancing spatial and perturbation proteomics; integrating multi-omics data; and ultimately enabling AI-empowered virtual cells.