 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiLA: Multi-view Intensive-fidelity Long-term Video Generation World Model for Autonomous Driving
Mar 20, 2025In recent years, data-driven techniques have greatly advanced autonomous driving systems, but the need for rare and diverse training data remains a challenge, requiring significant investment in equipment and labor. World models, which predict and generate future environmental states, offer a promising solution by synthesizing annotated video data for training. However, existing methods struggle to generate long, consistent videos without accumulating errors, especially in dynamic scenes. To address this, we propose MiLA, a novel framework for generating high-fidelity, long-duration videos up to one minute. MiLA utilizes a Coarse-to-Re(fine) approach to both stabilize video generation and correct distortion of dynamic objects. Additionally, we introduce a Temporal Progressive Denoising Scheduler and Joint Denoising and Correcting Flow modules to improve the quality of generated videos. Extensive experiments on the nuScenes dataset show that MiLA achieves state-of-the-art performance in video generation quality. For more information, visit the project website: https://github.com/xiaomi-mlab/mila.github.io.
Fully Sparse 3D Panoptic Occupancy Prediction
Dec 29, 2023Occupancy prediction plays a pivotal role in the realm of autonomous driving. Previous methods typically constructs a dense 3D volume, neglecting the inherent sparsity of the scene, which results in a high computational cost. Furthermore, these methods are limited to semantic occupancy and fail to differentiate between distinct instances. To exploit the sparsity property and ensure instance-awareness, we introduce a novel fully sparse panoptic occupancy network, termed SparseOcc. SparseOcc initially reconstructs a sparse 3D representation from visual inputs. Subsequently, it employs sparse instance queries to predict each object instance from the sparse 3D representation. These instance queries interact with 2D features via mask-guided sparse sampling, thereby circumventing the need for costly dense features or global attention. Additionally, we have established the first-ever vision-centric panoptic occupancy benchmark. SparseOcc demonstrates its efficacy on the Occ3D-nus dataset by achieving a mean Intersection over Union (mIoU) of 26.0, while maintaining a real-time inference speed of 25.4 FPS. By incorporating temporal modeling from the preceding 8 frames, SparseOcc further improves its performance, achieving 30.9 mIoU without whistles and bells. Code will be made available.
SparseBEV: High-Performance Sparse 3D Object Detection from Multi-Camera Videos
Sep 05, 2023Camera-based 3D object detection in BEV (Bird's Eye View) space has drawn great attention over the past few years. Dense detectors typically follow a two-stage pipeline by first constructing a dense BEV feature and then performing object detection in BEV space, which suffers from complex view transformations and high computation cost. On the other side, sparse detectors follow a query-based paradigm without explicit dense BEV feature construction, but achieve worse performance than the dense counterparts. In this paper, we find that the key to mitigate this performance gap is the adaptability of the detector in both BEV and image space. To achieve this goal, we propose SparseBEV, a fully sparse 3D object detector that outperforms the dense counterparts. SparseBEV contains three key designs, which are (1) scale-adaptive self attention to aggregate features with adaptive receptive field in BEV space, (2) adaptive spatio-temporal sampling to generate sampling locations under the guidance of queries, and (3) adaptive mixing to decode the sampled features with dynamic weights from the queries. On the test split of nuScenes, SparseBEV achieves the state-of-the-art performance of 67.5 NDS. On the val split, SparseBEV achieves 55.8 NDS while maintaining a real-time inference speed of 23.5 FPS. Code is available at https://github.com/MCG-NJU/SparseBEV.
StageInteractor: Query-based Object Detector with Cross-stage Interaction
Apr 11, 2023Previous object detectors make predictions based on dense grid points or numerous preset anchors. Most of these detectors are trained with one-to-many label assignment strategies. On the contrary, recent query-based object detectors depend on a sparse set of learnable queries and a series of decoder layers. The one-to-one label assignment is independently applied on each layer for the deep supervision during training. Despite the great success of query-based object detection, however, this one-to-one label assignment strategy demands the detectors to have strong fine-grained discrimination and modeling capacity. To solve the above problems, in this paper, we propose a new query-based object detector with cross-stage interaction, coined as StageInteractor. During the forward propagation, we come up with an efficient way to improve this modeling ability by reusing dynamic operators with lightweight adapters. As for the label assignment, a cross-stage label assigner is applied subsequent to the one-to-one label assignment. With this assigner, the training target class labels are gathered across stages and then reallocated to proper predictions at each decoder layer. On MS COCO benchmark, our model improves the baseline by 2.2 AP, and achieves 44.8 AP with ResNet-50 as backbone, 100 queries and 12 training epochs. With longer training time and 300 queries, StageInteractor achieves 51.1 AP and 52.2 AP with ResNeXt-101-DCN and Swin-S, respectively.
LinK: Linear Kernel for LiDAR-based 3D Perception
Mar 28, 2023Extending the success of 2D Large Kernel to 3D perception is challenging due to: 1. the cubically-increasing overhead in processing 3D data; 2. the optimization difficulties from data scarcity and sparsity. Previous work has taken the first step to scale up the kernel size from 3x3x3 to 7x7x7 by introducing block-shared weights. However, to reduce the feature variations within a block, it only employs modest block size and fails to achieve larger kernels like the 21x21x21. To address this issue, we propose a new method, called LinK, to achieve a wider-range perception receptive field in a convolution-like manner with two core designs. The first is to replace the static kernel matrix with a linear kernel generator, which adaptively provides weights only for non-empty voxels. The second is to reuse the pre-computed aggregation results in the overlapped blocks to reduce computation complexity. The proposed method successfully enables each voxel to perceive context within a range of 21x21x21. Extensive experiments on two basic perception tasks, 3D object detection and 3D semantic segmentation, demonstrate the effectiveness of our method. Notably, we rank 1st on the public leaderboard of the 3D detection benchmark of nuScenes (LiDAR track), by simply incorporating a LinK-based backbone into the basic detector, CenterPoint. We also boost the strong segmentation baseline's mIoU with 2.7% in the SemanticKITTI test set. Code is available at https://github.com/MCG-NJU/LinK.
Learning Optical Flow and Scene Flow with Bidirectional Camera-LiDAR Fusion
Mar 21, 2023In this paper, we study the problem of jointly estimating the optical flow and scene flow from synchronized 2D and 3D data. Previous methods either employ a complex pipeline that splits the joint task into independent stages, or fuse 2D and 3D information in an ``early-fusion'' or ``late-fusion'' manner. Such one-size-fits-all approaches suffer from a dilemma of failing to fully utilize the characteristic of each modality or to maximize the inter-modality complementarity. To address the problem, we propose a novel end-to-end framework, which consists of 2D and 3D branches with multiple bidirectional fusion connections between them in specific layers. Different from previous work, we apply a point-based 3D branch to extract the LiDAR features, as it preserves the geometric structure of point clouds. To fuse dense image features and sparse point features, we propose a learnable operator named bidirectional camera-LiDAR fusion module (Bi-CLFM). We instantiate two types of the bidirectional fusion pipeline, one based on the pyramidal coarse-to-fine architecture (dubbed CamLiPWC), and the other one based on the recurrent all-pairs field transforms (dubbed CamLiRAFT). On FlyingThings3D, both CamLiPWC and CamLiRAFT surpass all existing methods and achieve up to a 47.9\% reduction in 3D end-point-error from the best published result. Our best-performing model, CamLiRAFT, achieves an error of 4.26\% on the KITTI Scene Flow benchmark, ranking 1st among all submissions with much fewer parameters. Besides, our methods have strong generalization performance and the ability to handle non-rigid motion. Code is available at https://github.com/MCG-NJU/CamLiFlow.
CamLiFlow: Bidirectional Camera-LiDAR Fusion for Joint Optical Flow and Scene Flow Estimation
Nov 20, 2021


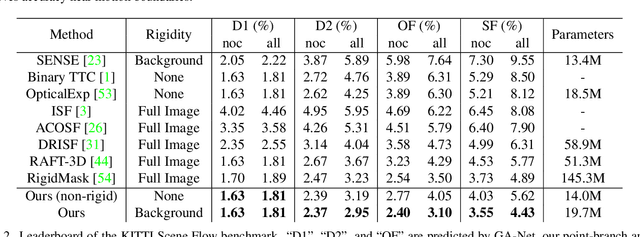
In this paper, we study the problem of jointly estimating the optical flow and scene flow from synchronized 2D and 3D data. Previous methods either employ a complex pipeline which splits the joint task into independent stages, or fuse 2D and 3D information in an ``early-fusion'' or ``late-fusion'' manner. Such one-size-fits-all approaches suffer from a dilemma of failing to fully utilize the characteristic of each modality or to maximize the inter-modality complementarity. To address the problem, we propose a novel end-to-end framework, called CamLiFlow. It consists of 2D and 3D branches with multiple bidirectional connections between them in specific layers. Different from previous work, we apply a point-based 3D branch to better extract the geometric features and design a symmetric learnable operator to fuse dense image features and sparse point features. We also propose a transformation for point clouds to solve the non-linear issue of 3D-2D projection. Experiments show that CamLiFlow achieves better performance with fewer parameters. Our method ranks 1st on the KITTI Scene Flow benchmark, outperforming the previous art with 1/7 parameters. Code will be made available.