 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCubic Discrete Diffusion: Discrete Visual Generation on High-Dimensional Representation Tokens
Mar 19, 2026Visual generation with discrete tokens has gained significant attention as it enables a unified token prediction paradigm shared with language models, promising seamless multimodal architectures. However, current discrete generation methods remain limited to low-dimensional latent tokens (typically 8-32 dims), sacrificing the semantic richness essential for understanding. While high-dimensional pretrained representations (768-1024 dims) could bridge this gap, their discrete generation poses fundamental challenges. In this paper, we present Cubic Discrete Diffusion (CubiD), the first discrete generation model for high-dimensional representations. CubiD performs fine-grained masking throughout the high-dimensional discrete representation -- any dimension at any position can be masked and predicted from partial observations. This enables the model to learn rich correlations both within and across spatial positions, with the number of generation steps fixed at $T$ regardless of feature dimensionality, where $T \ll hwd$. On ImageNet-256, CubiD achieves state-of-the-art discrete generation with strong scaling behavior from 900M to 3.7B parameters. Crucially, we validate that these discretized tokens preserve original representation capabilities, demonstrating that the same discrete tokens can effectively serve both understanding and generation tasks. We hope this work will inspire future research toward unified multimodal architectures. Code is available at: https://github.com/YuqingWang1029/CubiD.
Adaptive 1D Video Diffusion Autoencoder
Feb 04, 2026Recent video generation models largely rely on video autoencoders that compress pixel-space videos into latent representations. However, existing video autoencoders suffer from three major limitations: (1) fixed-rate compression that wastes tokens on simple videos, (2) inflexible CNN architectures that prevent variable-length latent modeling, and (3) deterministic decoders that struggle to recover appropriate details from compressed latents. To address these issues, we propose One-Dimensional Diffusion Video Autoencoder (One-DVA), a transformer-based framework for adaptive 1D encoding and diffusion-based decoding. The encoder employs query-based vision transformers to extract spatiotemporal features and produce latent representations, while a variable-length dropout mechanism dynamically adjusts the latent length. The decoder is a pixel-space diffusion transformer that reconstructs videos with the latents as input conditions. With a two-stage training strategy, One-DVA achieves performance comparable to 3D-CNN VAEs on reconstruction metrics at identical compression ratios. More importantly, it supports adaptive compression and thus can achieve higher compression ratios. To better support downstream latent generation, we further regularize the One-DVA latent distribution for generative modeling and fine-tune its decoder to mitigate artifacts caused by the generation process.
SJD++: Improved Speculative Jacobi Decoding for Training-free Acceleration of Discrete Auto-regressive Text-to-Image Generation
Dec 08, 2025Large autoregressive models can generate high-quality, high-resolution images but suffer from slow generation speed, because these models require hundreds to thousands of sequential forward passes for next-token prediction during inference. To accelerate autoregressive text-to-image generation, we propose Speculative Jacobi Decoding++ (SJD++), a training-free probabilistic parallel decoding algorithm. Unlike traditional next-token prediction, SJD++ performs multi-token prediction in each forward pass, drastically reducing generation steps. Specifically, it integrates the iterative multi-token prediction mechanism from Jacobi decoding, with the probabilistic drafting-and-verification mechanism from speculative sampling. More importantly, for further acceleration, SJD++ reuses high-confidence draft tokens after each verification phase instead of resampling them all. We conduct extensive experiments on several representative autoregressive text-to-image generation models and demonstrate that SJD++ achieves $2\times$ to $3\times$ inference latency reduction and $2\times$ to $7\times$ step compression, while preserving visual quality with no observable degradation.
Self-NPO: Negative Preference Optimization of Diffusion Models by Simply Learning from Itself without Explicit Preference Annotations
May 17, 2025Diffusion models have demonstrated remarkable success in various visual generation tasks, including image, video, and 3D content generation. Preference optimization (PO) is a prominent and growing area of research that aims to align these models with human preferences. While existing PO methods primarily concentrate on producing favorable outputs, they often overlook the significance of classifier-free guidance (CFG) in mitigating undesirable results. Diffusion-NPO addresses this gap by introducing negative preference optimization (NPO), training models to generate outputs opposite to human preferences and thereby steering them away from unfavorable outcomes. However, prior NPO approaches, including Diffusion-NPO, rely on costly and fragile procedures for obtaining explicit preference annotations (e.g., manual pairwise labeling or reward model training), limiting their practicality in domains where such data are scarce or difficult to acquire. In this work, we introduce Self-NPO, a Negative Preference Optimization approach that learns exclusively from the model itself, thereby eliminating the need for manual data labeling or reward model training. Moreover, our method is highly efficient and does not require exhaustive data sampling. We demonstrate that Self-NPO integrates seamlessly into widely used diffusion models, including SD1.5, SDXL, and CogVideoX, as well as models already optimized for human preferences, consistently enhancing both their generation quality and alignment with human preferences.
Personalized Text-to-Image Generation with Auto-Regressive Models
Apr 17, 2025Personalized image synthesis has emerged as a pivotal application in text-to-image generation, enabling the creation of images featuring specific subjects in diverse contexts. While diffusion models have dominated this domain, auto-regressive models, with their unified architecture for text and image modeling, remain underexplored for personalized image generation. This paper investigates the potential of optimizing auto-regressive models for personalized image synthesis, leveraging their inherent multimodal capabilities to perform this task. We propose a two-stage training strategy that combines optimization of text embeddings and fine-tuning of transformer layers. Our experiments on the auto-regressive model demonstrate that this method achieves comparable subject fidelity and prompt following to the leading diffusion-based personalization methods. The results highlight the effectiveness of auto-regressive models in personalized image generation, offering a new direction for future research in this area.
Bridging Continuous and Discrete Tokens for Autoregressive Visual Generation
Mar 20, 2025Autoregressive visual generation models typically rely on tokenizers to compress images into tokens that can be predicted sequentially. A fundamental dilemma exists in token representation: discrete tokens enable straightforward modeling with standard cross-entropy loss, but suffer from information loss and tokenizer training instability; continuous tokens better preserve visual details, but require complex distribution modeling, complicating the generation pipeline. In this paper, we propose TokenBridge, which bridges this gap by maintaining the strong representation capacity of continuous tokens while preserving the modeling simplicity of discrete tokens. To achieve this, we decouple discretization from the tokenizer training process through post-training quantization that directly obtains discrete tokens from continuous representations. Specifically, we introduce a dimension-wise quantization strategy that independently discretizes each feature dimension, paired with a lightweight autoregressive prediction mechanism that efficiently model the resulting large token space. Extensive experiments show that our approach achieves reconstruction and generation quality on par with continuous methods while using standard categorical prediction. This work demonstrates that bridging discrete and continuous paradigms can effectively harness the strengths of both approaches, providing a promising direction for high-quality visual generation with simple autoregressive modeling. Project page: https://yuqingwang1029.github.io/TokenBridge.
Analyzing Nobel Prize Literature with Large Language Models
Oct 22, 2024



This study examines the capabilities of advanced Large Language Models (LLMs), particularly the o1 model, in the context of literary analysis. The outputs of these models are compared directly to those produced by graduate-level human participants. By focusing on two Nobel Prize-winning short stories, 'Nine Chapters' by Han Kang, the 2024 laureate, and 'Friendship' by Jon Fosse, the 2023 laureate, the research explores the extent to which AI can engage with complex literary elements such as thematic analysis, intertextuality, cultural and historical contexts, linguistic and structural innovations, and character development. Given the Nobel Prize's prestige and its emphasis on cultural, historical, and linguistic richness, applying LLMs to these works provides a deeper understanding of both human and AI approaches to interpretation. The study uses qualitative and quantitative evaluations of coherence, creativity, and fidelity to the text, revealing the strengths and limitations of AI in tasks typically reserved for human expertise. While LLMs demonstrate strong analytical capabilities, particularly in structured tasks, they often fall short in emotional nuance and coherence, areas where human interpretation excels. This research underscores the potential for human-AI collaboration in the humanities, opening new opportunities in literary studies and beyond.
Accelerating Auto-regressive Text-to-Image Generation with Training-free Speculative Jacobi Decoding
Oct 02, 2024
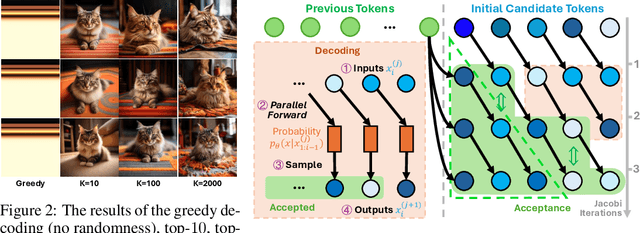
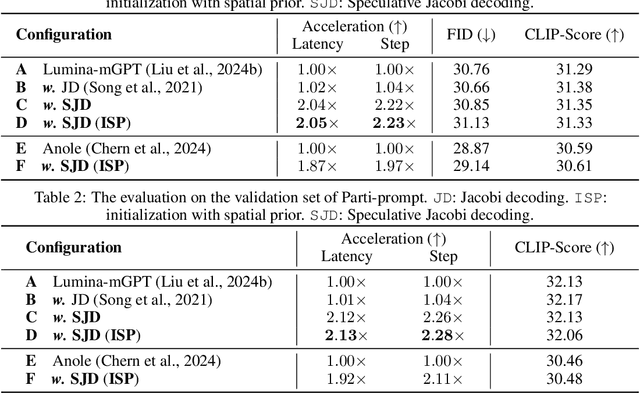
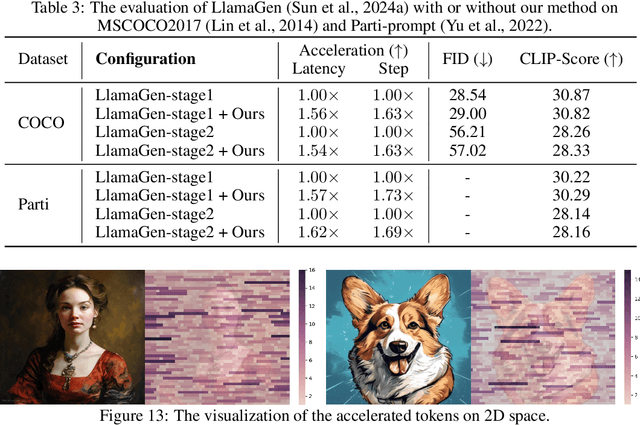
The current large auto-regressive models can generate high-quality, high-resolution images, but these models require hundreds or even thousands of steps of next-token prediction during inference, resulting in substantial time consumption. In existing studies, Jacobi decoding, an iterative parallel decoding algorithm, has been used to accelerate the auto-regressive generation and can be executed without training. However, the Jacobi decoding relies on a deterministic criterion to determine the convergence of iterations. Thus, it works for greedy decoding but is incompatible with sampling-based decoding which is crucial for visual quality and diversity in the current auto-regressive text-to-image generation. In this paper, we propose a training-free probabilistic parallel decoding algorithm, Speculative Jacobi Decoding (SJD), to accelerate auto-regressive text-to-image generation. By introducing a probabilistic convergence criterion, our SJD accelerates the inference of auto-regressive text-to-image generation while maintaining the randomness in sampling-based token decoding and allowing the model to generate diverse images. Specifically, SJD facilitates the model to predict multiple tokens at each step and accepts tokens based on the probabilistic criterion, enabling the model to generate images with fewer steps than the conventional next-token-prediction paradigm. We also investigate the token initialization strategies that leverage the spatial locality of visual data to further improve the acceleration ratio under specific scenarios. We conduct experiments for our proposed SJD on multiple auto-regressive text-to-image generation models, showing the effectiveness of model acceleration without sacrificing the visual quality.
CycleHOI: Improving Human-Object Interaction Detection with Cycle Consistency of Detection and Generation
Jul 16, 2024Recognition and generation are two fundamental tasks in computer vision, which are often investigated separately in the exiting literature. However, these two tasks are highly correlated in essence as they both require understanding the underline semantics of visual concepts. In this paper, we propose a new learning framework, coined as CycleHOI, to boost the performance of human-object interaction (HOI) detection by bridging the DETR-based detection pipeline and the pre-trained text-to-image diffusion model. Our key design is to introduce a novel cycle consistency loss for the training of HOI detector, which is able to explicitly leverage the knowledge captured in the powerful diffusion model to guide the HOI detector training. Specifically, we build an extra generation task on top of the decoded instance representations from HOI detector to enforce a detection-generation cycle consistency. Moreover, we perform feature distillation from diffusion model to detector encoder to enhance its representation power. In addition, we further utilize the generation power of diffusion model to augment the training set in both aspects of label correction and sample generation. We perform extensive experiments to verify the effectiveness and generalization power of our CycleHOI with three HOI detection frameworks on two public datasets: HICO-DET and V-COCO. The experimental results demonstrate our CycleHOI can significantly improve the performance of the state-of-the-art HOI detectors.
DiM: Diffusion Mamba for Efficient High-Resolution Image Synthesis
May 23, 2024



Diffusion models have achieved great success in image generation, with the backbone evolving from U-Net to Vision Transformers. However, the computational cost of Transformers is quadratic to the number of tokens, leading to significant challenges when dealing with high-resolution images. In this work, we propose Diffusion Mamba (DiM), which combines the efficiency of Mamba, a sequence model based on State Space Models (SSM), with the expressive power of diffusion models for efficient high-resolution image synthesis. To address the challenge that Mamba cannot generalize to 2D signals, we make several architecture designs including multi-directional scans, learnable padding tokens at the end of each row and column, and lightweight local feature enhancement. Our DiM architecture achieves inference-time efficiency for high-resolution images. In addition, to further improve training efficiency for high-resolution image generation with DiM, we investigate ``weak-to-strong'' training strategy that pretrains DiM on low-resolution images ($256\times 256$) and then finetune it on high-resolution images ($512 \times 512$). We further explore training-free upsampling strategies to enable the model to generate higher-resolution images (e.g., $1024\times 1024$ and $1536\times 1536$) without further fine-tuning. Experiments demonstrate the effectiveness and efficiency of our DiM.