 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT2I-ReasonBench: Benchmarking Reasoning-Informed Text-to-Image Generation
Aug 24, 2025



We propose T2I-ReasonBench, a benchmark evaluating reasoning capabilities of text-to-image (T2I) models. It consists of four dimensions: Idiom Interpretation, Textual Image Design, Entity-Reasoning and Scientific-Reasoning. We propose a two-stage evaluation protocol to assess the reasoning accuracy and image quality. We benchmark various T2I generation models, and provide comprehensive analysis on their performances.
Personalized Text-to-Image Generation with Auto-Regressive Models
Apr 17, 2025Personalized image synthesis has emerged as a pivotal application in text-to-image generation, enabling the creation of images featuring specific subjects in diverse contexts. While diffusion models have dominated this domain, auto-regressive models, with their unified architecture for text and image modeling, remain underexplored for personalized image generation. This paper investigates the potential of optimizing auto-regressive models for personalized image synthesis, leveraging their inherent multimodal capabilities to perform this task. We propose a two-stage training strategy that combines optimization of text embeddings and fine-tuning of transformer layers. Our experiments on the auto-regressive model demonstrate that this method achieves comparable subject fidelity and prompt following to the leading diffusion-based personalization methods. The results highlight the effectiveness of auto-regressive models in personalized image generation, offering a new direction for future research in this area.
T2V-CompBench: A Comprehensive Benchmark for Compositional Text-to-video Generation
Jul 19, 2024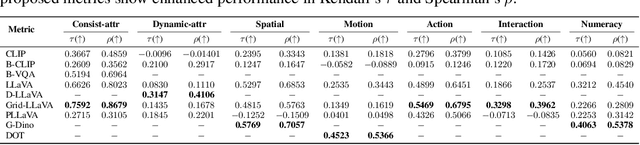
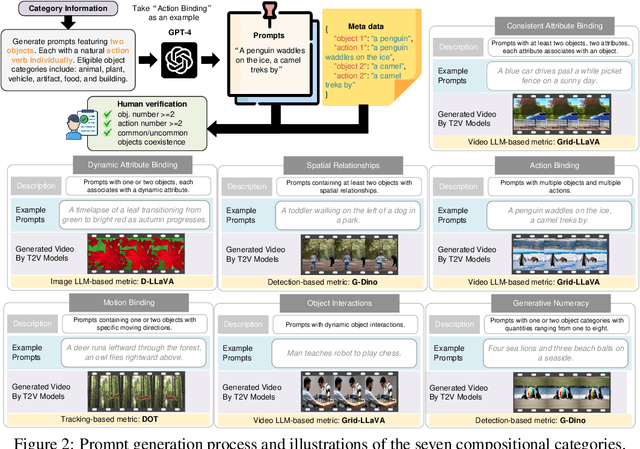
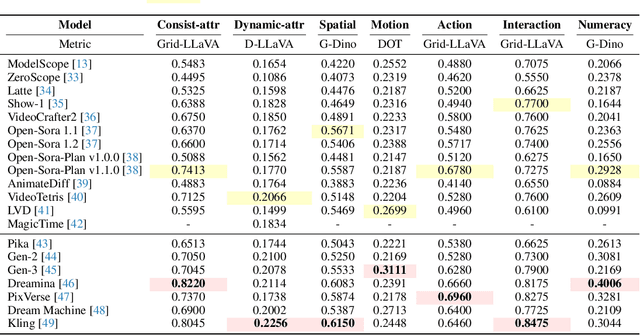

Text-to-video (T2V) generation models have advanced significantly, yet their ability to compose different objects, attributes, actions, and motions into a video remains unexplored. Previous text-to-video benchmarks also neglect this important ability for evaluation. In this work, we conduct the first systematic study on compositional text-to-video generation. We propose T2V-CompBench, the first benchmark tailored for compositional text-to-video generation. T2V-CompBench encompasses diverse aspects of compositionality, including consistent attribute binding, dynamic attribute binding, spatial relationships, motion binding, action binding, object interactions, and generative numeracy. We further carefully design evaluation metrics of MLLM-based metrics, detection-based metrics, and tracking-based metrics, which can better reflect the compositional text-to-video generation quality of seven proposed categories with 700 text prompts. The effectiveness of the proposed metrics is verified by correlation with human evaluations. We also benchmark various text-to-video generative models and conduct in-depth analysis across different models and different compositional categories. We find that compositional text-to-video generation is highly challenging for current models, and we hope that our attempt will shed light on future research in this direction.
T2I-CompBench: A Comprehensive Benchmark for Open-world Compositional Text-to-image Generation
Jul 12, 2023



Despite the stunning ability to generate high-quality images by recent text-to-image models, current approaches often struggle to effectively compose objects with different attributes and relationships into a complex and coherent scene. We propose T2I-CompBench, a comprehensive benchmark for open-world compositional text-to-image generation, consisting of 6,000 compositional text prompts from 3 categories (attribute binding, object relationships, and complex compositions) and 6 sub-categories (color binding, shape binding, texture binding, spatial relationships, non-spatial relationships, and complex compositions). We further propose several evaluation metrics specifically designed to evaluate compositional text-to-image generation. We introduce a new approach, Generative mOdel fine-tuning with Reward-driven Sample selection (GORS), to boost the compositional text-to-image generation abilities of pretrained text-to-image models. Extensive experiments and evaluations are conducted to benchmark previous methods on T2I-CompBench, and to validate the effectiveness of our proposed evaluation metrics and GORS approach. Project page is available at https://karine-h.github.io/T2I-CompBench/.