 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCineScene: Implicit 3D as Effective Scene Representation for Cinematic Video Generation
Feb 06, 2026Cinematic video production requires control over scene-subject composition and camera movement, but live-action shooting remains costly due to the need for constructing physical sets. To address this, we introduce the task of cinematic video generation with decoupled scene context: given multiple images of a static environment, the goal is to synthesize high-quality videos featuring dynamic subject while preserving the underlying scene consistency and following a user-specified camera trajectory. We present CineScene, a framework that leverages implicit 3D-aware scene representation for cinematic video generation. Our key innovation is a novel context conditioning mechanism that injects 3D-aware features in an implicit way: By encoding scene images into visual representations through VGGT, CineScene injects spatial priors into a pretrained text-to-video generation model by additional context concatenation, enabling camera-controlled video synthesis with consistent scenes and dynamic subjects. To further enhance the model's robustness, we introduce a simple yet effective random-shuffling strategy for the input scene images during training. To address the lack of training data, we construct a scene-decoupled dataset with Unreal Engine 5, containing paired videos of scenes with and without dynamic subjects, panoramic images representing the underlying static scene, along with their camera trajectories. Experiments show that CineScene achieves state-of-the-art performance in scene-consistent cinematic video generation, handling large camera movements and demonstrating generalization across diverse environments.
FilMaster: Bridging Cinematic Principles and Generative AI for Automated Film Generation
Jun 23, 2025AI-driven content creation has shown potential in film production. However, existing film generation systems struggle to implement cinematic principles and thus fail to generate professional-quality films, particularly lacking diverse camera language and cinematic rhythm. This results in templated visuals and unengaging narratives. To address this, we introduce FilMaster, an end-to-end AI system that integrates real-world cinematic principles for professional-grade film generation, yielding editable, industry-standard outputs. FilMaster is built on two key principles: (1) learning cinematography from extensive real-world film data and (2) emulating professional, audience-centric post-production workflows. Inspired by these principles, FilMaster incorporates two stages: a Reference-Guided Generation Stage which transforms user input to video clips, and a Generative Post-Production Stage which transforms raw footage into audiovisual outputs by orchestrating visual and auditory elements for cinematic rhythm. Our generation stage highlights a Multi-shot Synergized RAG Camera Language Design module to guide the AI in generating professional camera language by retrieving reference clips from a vast corpus of 440,000 film clips. Our post-production stage emulates professional workflows by designing an Audience-Centric Cinematic Rhythm Control module, including Rough Cut and Fine Cut processes informed by simulated audience feedback, for effective integration of audiovisual elements to achieve engaging content. The system is empowered by generative AI models like (M)LLMs and video generation models. Furthermore, we introduce FilmEval, a comprehensive benchmark for evaluating AI-generated films. Extensive experiments show FilMaster's superior performance in camera language design and cinematic rhythm control, advancing generative AI in professional filmmaking.
GenMAC: Compositional Text-to-Video Generation with Multi-Agent Collaboration
Dec 05, 2024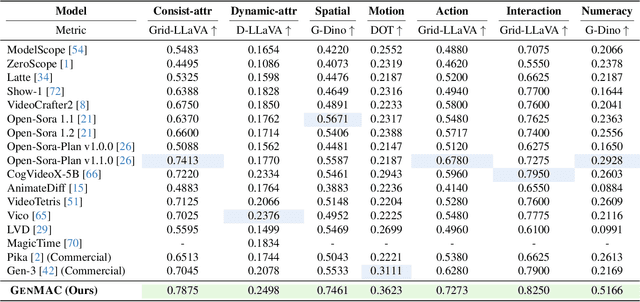
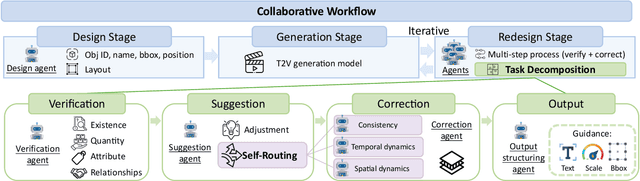
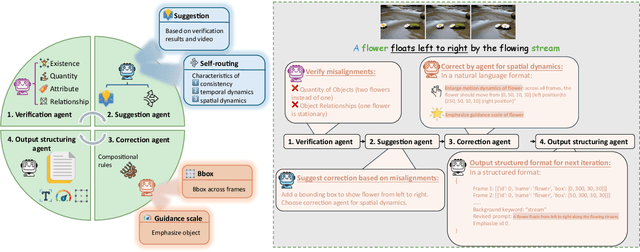

Text-to-video generation models have shown significant progress in the recent years. However, they still struggle with generating complex dynamic scenes based on compositional text prompts, such as attribute binding for multiple objects, temporal dynamics associated with different objects, and interactions between objects. Our key motivation is that complex tasks can be decomposed into simpler ones, each handled by a role-specialized MLLM agent. Multiple agents can collaborate together to achieve collective intelligence for complex goals. We propose GenMAC, an iterative, multi-agent framework that enables compositional text-to-video generation. The collaborative workflow includes three stages: Design, Generation, and Redesign, with an iterative loop between the Generation and Redesign stages to progressively verify and refine the generated videos. The Redesign stage is the most challenging stage that aims to verify the generated videos, suggest corrections, and redesign the text prompts, frame-wise layouts, and guidance scales for the next iteration of generation. To avoid hallucination of a single MLLM agent, we decompose this stage to four sequentially-executed MLLM-based agents: verification agent, suggestion agent, correction agent, and output structuring agent. Furthermore, to tackle diverse scenarios of compositional text-to-video generation, we design a self-routing mechanism to adaptively select the proper correction agent from a collection of correction agents each specialized for one scenario. Extensive experiments demonstrate the effectiveness of GenMAC, achieving state-of-the art performance in compositional text-to-video generation.
T2V-CompBench: A Comprehensive Benchmark for Compositional Text-to-video Generation
Jul 19, 2024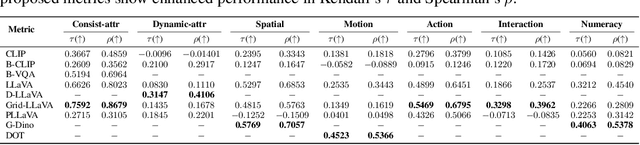
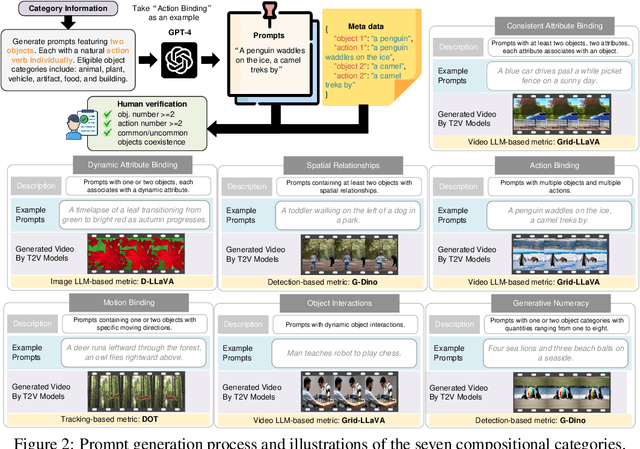
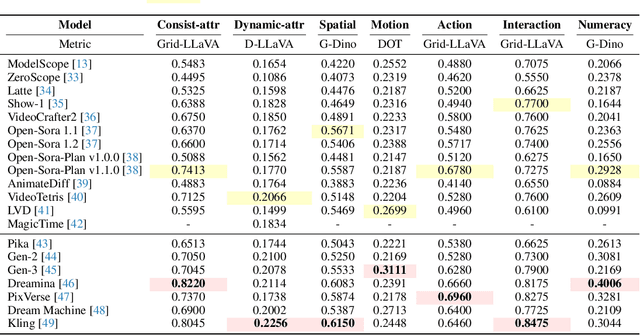

Text-to-video (T2V) generation models have advanced significantly, yet their ability to compose different objects, attributes, actions, and motions into a video remains unexplored. Previous text-to-video benchmarks also neglect this important ability for evaluation. In this work, we conduct the first systematic study on compositional text-to-video generation. We propose T2V-CompBench, the first benchmark tailored for compositional text-to-video generation. T2V-CompBench encompasses diverse aspects of compositionality, including consistent attribute binding, dynamic attribute binding, spatial relationships, motion binding, action binding, object interactions, and generative numeracy. We further carefully design evaluation metrics of MLLM-based metrics, detection-based metrics, and tracking-based metrics, which can better reflect the compositional text-to-video generation quality of seven proposed categories with 700 text prompts. The effectiveness of the proposed metrics is verified by correlation with human evaluations. We also benchmark various text-to-video generative models and conduct in-depth analysis across different models and different compositional categories. We find that compositional text-to-video generation is highly challenging for current models, and we hope that our attempt will shed light on future research in this direction.
T2I-CompBench: A Comprehensive Benchmark for Open-world Compositional Text-to-image Generation
Jul 12, 2023



Despite the stunning ability to generate high-quality images by recent text-to-image models, current approaches often struggle to effectively compose objects with different attributes and relationships into a complex and coherent scene. We propose T2I-CompBench, a comprehensive benchmark for open-world compositional text-to-image generation, consisting of 6,000 compositional text prompts from 3 categories (attribute binding, object relationships, and complex compositions) and 6 sub-categories (color binding, shape binding, texture binding, spatial relationships, non-spatial relationships, and complex compositions). We further propose several evaluation metrics specifically designed to evaluate compositional text-to-image generation. We introduce a new approach, Generative mOdel fine-tuning with Reward-driven Sample selection (GORS), to boost the compositional text-to-image generation abilities of pretrained text-to-image models. Extensive experiments and evaluations are conducted to benchmark previous methods on T2I-CompBench, and to validate the effectiveness of our proposed evaluation metrics and GORS approach. Project page is available at https://karine-h.github.io/T2I-CompBench/.