 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph2Video: Leveraging Video Models to Model Dynamic Graph Evolution
Mar 09, 2026Dynamic graphs are common in real-world systems such as social media, recommender systems, and traffic networks. Existing dynamic graph models for link prediction often fall short in capturing the complexity of temporal evolution. They tend to overlook fine-grained variations in temporal interaction order, struggle with dependencies that span long time horizons, and offer limited capability to model pair-specific relational dynamics. To address these challenges, we propose \textbf{Graph2Video}, a video-inspired framework that views the temporal neighborhood of a target link as a sequence of "graph frames". By stacking temporally ordered subgraph frames into a "graph video", Graph2Video leverages the inductive biases of video foundation models to capture both fine-grained local variations and long-range temporal dynamics. It generates a link-level embedding that serves as a lightweight and plug-and-play link-centric memory unit. This embedding integrates seamlessly into existing dynamic graph encoders, effectively addressing the limitations of prior approaches. Extensive experiments on benchmark datasets show that Graph2Video outperforms state-of-the-art baselines on the link prediction task in most cases. The results highlight the potential of borrowing spatio-temporal modeling techniques from computer vision as a promising and effective approach for advancing dynamic graph learning.
Non-Uniform Noise-to-Signal Ratio in the REINFORCE Policy-Gradient Estimator
Feb 01, 2026Policy-gradient methods are widely used in reinforcement learning, yet training often becomes unstable or slows down as learning progresses. We study this phenomenon through the noise-to-signal ratio (NSR) of a policy-gradient estimator, defined as the estimator variance (noise) normalized by the squared norm of the true gradient (signal). Our main result is that, for (i) finite-horizon linear systems with Gaussian policies and linear state-feedback, and (ii) finite-horizon polynomial systems with Gaussian policies and polynomial feedback, the NSR of the REINFORCE estimator can be characterized exactly-either in closed form or via numerical moment-evaluation algorithms-without approximation. For general nonlinear dynamics and expressive policies (including neural policies), we further derive a general upper bound on the variance. These characterizations enable a direct examination of how NSR varies across policy parameters and how it evolves along optimization trajectories (e.g. SGD and Adam). Across a range of examples, we find that the NSR landscape is highly non-uniform and typically increases as the policy approaches an optimum; in some regimes it blows up, which can trigger training instability and policy collapse.
Sparse Variable Projection in Robotic Perception: Exploiting Separable Structure for Efficient Nonlinear Optimization
Dec 08, 2025Robotic perception often requires solving large nonlinear least-squares (NLS) problems. While sparsity has been well-exploited to scale solvers, a complementary and underexploited structure is \emph{separability} -- where some variables (e.g., visual landmarks) appear linearly in the residuals and, for any estimate of the remaining variables (e.g., poses), have a closed-form solution. Variable projection (VarPro) methods are a family of techniques that exploit this structure by analytically eliminating the linear variables and presenting a reduced problem in the remaining variables that has favorable properties. However, VarPro has seen limited use in robotic perception; a major challenge arises from gauge symmetries (e.g., cost invariance to global shifts and rotations), which are common in perception and induce specific computational challenges in standard VarPro approaches. We present a VarPro scheme designed for problems with gauge symmetries that jointly exploits separability and sparsity. Our method can be applied as a one-time preprocessing step to construct a \emph{matrix-free Schur complement operator}. This operator allows efficient evaluation of costs, gradients, and Hessian-vector products of the reduced problem and readily integrates with standard iterative NLS solvers. We provide precise conditions under which our method applies, and describe extensions when these conditions are only partially met. Across synthetic and real benchmarks in SLAM, SNL, and SfM, our approach achieves up to \textbf{2$\times$--35$\times$ faster runtimes} than state-of-the-art methods while maintaining accuracy. We release an open-source C++ implementation and all datasets from our experiments.
Enhancing LLM-Based Short Answer Grading with Retrieval-Augmented Generation
Apr 07, 2025



Short answer assessment is a vital component of science education, allowing evaluation of students' complex three-dimensional understanding. Large language models (LLMs) that possess human-like ability in linguistic tasks are increasingly popular in assisting human graders to reduce their workload. However, LLMs' limitations in domain knowledge restrict their understanding in task-specific requirements and hinder their ability to achieve satisfactory performance. Retrieval-augmented generation (RAG) emerges as a promising solution by enabling LLMs to access relevant domain-specific knowledge during assessment. In this work, we propose an adaptive RAG framework for automated grading that dynamically retrieves and incorporates domain-specific knowledge based on the question and student answer context. Our approach combines semantic search and curated educational sources to retrieve valuable reference materials. Experimental results in a science education dataset demonstrate that our system achieves an improvement in grading accuracy compared to baseline LLM approaches. The findings suggest that RAG-enhanced grading systems can serve as reliable support with efficient performance gains.
Language Guided Concept Bottleneck Models for Interpretable Continual Learning
Mar 30, 2025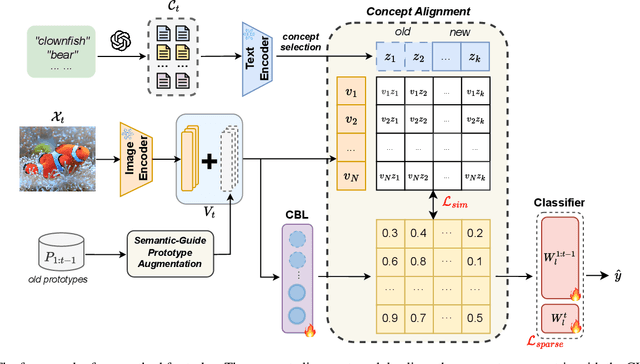
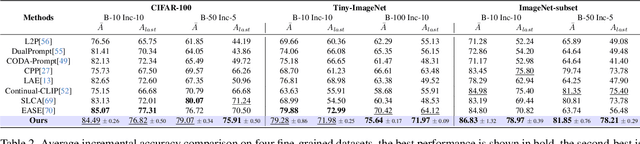
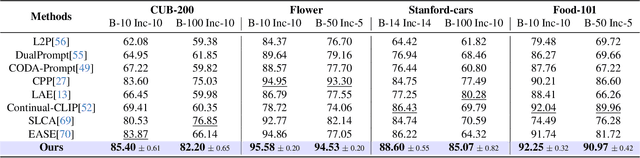
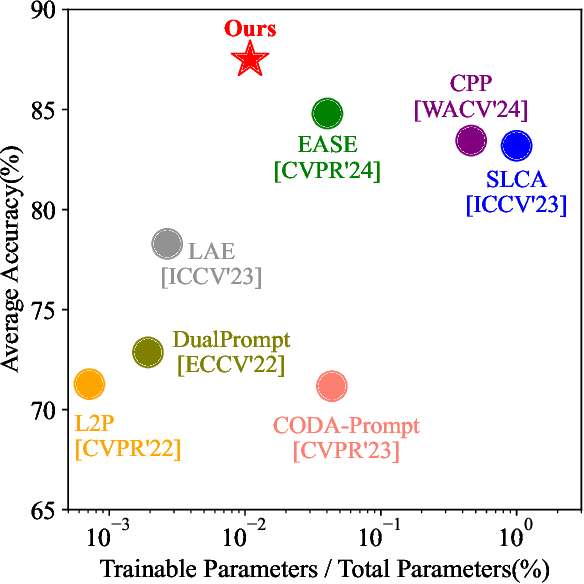
Continual learning (CL) aims to enable learning systems to acquire new knowledge constantly without forgetting previously learned information. CL faces the challenge of mitigating catastrophic forgetting while maintaining interpretability across tasks. Most existing CL methods focus primarily on preserving learned knowledge to improve model performance. However, as new information is introduced, the interpretability of the learning process becomes crucial for understanding the evolving decision-making process, yet it is rarely explored. In this paper, we introduce a novel framework that integrates language-guided Concept Bottleneck Models (CBMs) to address both challenges. Our approach leverages the Concept Bottleneck Layer, aligning semantic consistency with CLIP models to learn human-understandable concepts that can generalize across tasks. By focusing on interpretable concepts, our method not only enhances the models ability to retain knowledge over time but also provides transparent decision-making insights. We demonstrate the effectiveness of our approach by achieving superior performance on several datasets, outperforming state-of-the-art methods with an improvement of up to 3.06% in final average accuracy on ImageNet-subset. Additionally, we offer concept visualizations for model predictions, further advancing the understanding of interpretable continual learning.
Empowering GraphRAG with Knowledge Filtering and Integration
Mar 18, 2025In recent years, large language models (LLMs) have revolutionized the field of natural language processing. However, they often suffer from knowledge gaps and hallucinations. Graph retrieval-augmented generation (GraphRAG) enhances LLM reasoning by integrating structured knowledge from external graphs. However, we identify two key challenges that plague GraphRAG:(1) Retrieving noisy and irrelevant information can degrade performance and (2)Excessive reliance on external knowledge suppresses the model's intrinsic reasoning. To address these issues, we propose GraphRAG-FI (Filtering and Integration), consisting of GraphRAG-Filtering and GraphRAG-Integration. GraphRAG-Filtering employs a two-stage filtering mechanism to refine retrieved information. GraphRAG-Integration employs a logits-based selection strategy to balance external knowledge from GraphRAG with the LLM's intrinsic reasoning,reducing over-reliance on retrievals. Experiments on knowledge graph QA tasks demonstrate that GraphRAG-FI significantly improves reasoning performance across multiple backbone models, establishing a more reliable and effective GraphRAG framework.
Mixture of Structural-and-Textual Retrieval over Text-rich Graph Knowledge Bases
Feb 27, 2025Text-rich Graph Knowledge Bases (TG-KBs) have become increasingly crucial for answering queries by providing textual and structural knowledge. However, current retrieval methods often retrieve these two types of knowledge in isolation without considering their mutual reinforcement and some hybrid methods even bypass structural retrieval entirely after neighboring aggregation. To fill in this gap, we propose a Mixture of Structural-and-Textual Retrieval (MoR) to retrieve these two types of knowledge via a Planning-Reasoning-Organizing framework. In the Planning stage, MoR generates textual planning graphs delineating the logic for answering queries. Following planning graphs, in the Reasoning stage, MoR interweaves structural traversal and textual matching to obtain candidates from TG-KBs. In the Organizing stage, MoR further reranks fetched candidates based on their structural trajectory. Extensive experiments demonstrate the superiority of MoR in harmonizing structural and textual retrieval with insights, including uneven retrieving performance across different query logics and the benefits of integrating structural trajectories for candidate reranking. Our code is available at https://github.com/Yoega/MoR.
Unveiling Mode Connectivity in Graph Neural Networks
Feb 18, 2025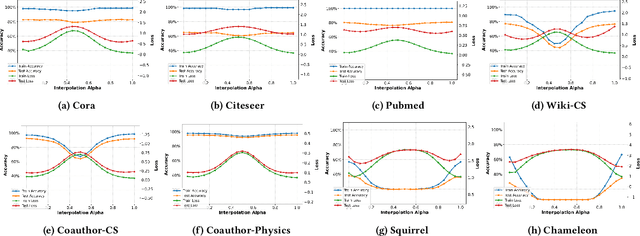
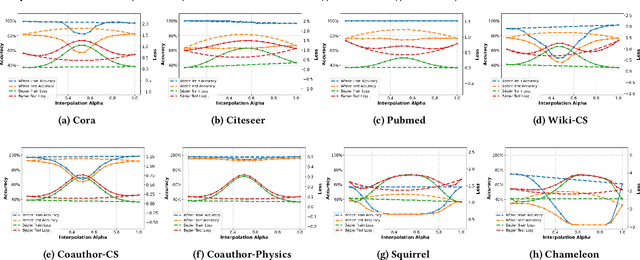
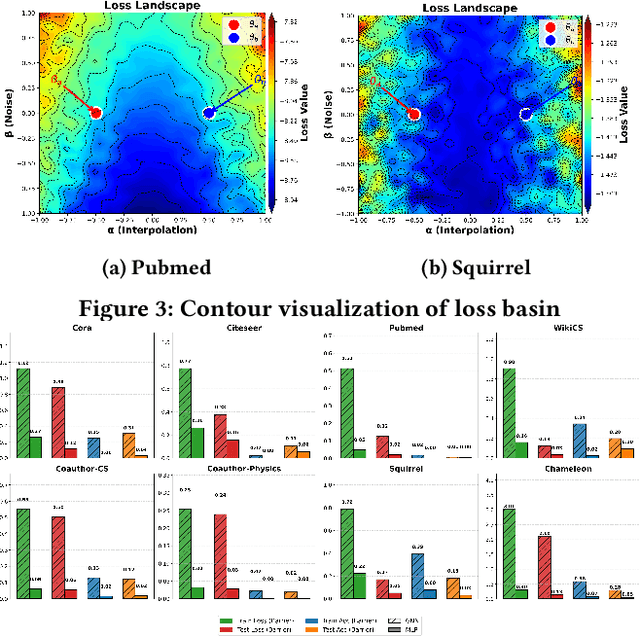
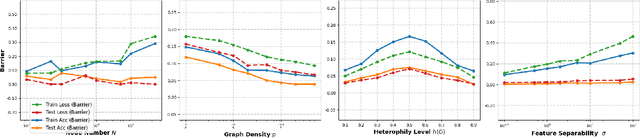
A fundamental challenge in understanding graph neural networks (GNNs) lies in characterizing their optimization dynamics and loss landscape geometry, critical for improving interpretability and robustness. While mode connectivity, a lens for analyzing geometric properties of loss landscapes has proven insightful for other deep learning architectures, its implications for GNNs remain unexplored. This work presents the first investigation of mode connectivity in GNNs. We uncover that GNNs exhibit distinct non-linear mode connectivity, diverging from patterns observed in fully-connected networks or CNNs. Crucially, we demonstrate that graph structure, rather than model architecture, dominates this behavior, with graph properties like homophily correlating with mode connectivity patterns. We further establish a link between mode connectivity and generalization, proposing a generalization bound based on loss barriers and revealing its utility as a diagnostic tool. Our findings further bridge theoretical insights with practical implications: they rationalize domain alignment strategies in graph learning and provide a foundation for refining GNN training paradigms.
RAG vs. GraphRAG: A Systematic Evaluation and Key Insights
Feb 17, 2025Retrieval-Augmented Generation (RAG) enhances the performance of LLMs across various tasks by retrieving relevant information from external sources, particularly on text-based data. For structured data, such as knowledge graphs, GraphRAG has been widely used to retrieve relevant information. However, recent studies have revealed that structuring implicit knowledge from text into graphs can benefit certain tasks, extending the application of GraphRAG from graph data to general text-based data. Despite their successful extensions, most applications of GraphRAG for text data have been designed for specific tasks and datasets, lacking a systematic evaluation and comparison between RAG and GraphRAG on widely used text-based benchmarks. In this paper, we systematically evaluate RAG and GraphRAG on well-established benchmark tasks, such as Question Answering and Query-based Summarization. Our results highlight the distinct strengths of RAG and GraphRAG across different tasks and evaluation perspectives. Inspired by these observations, we investigate strategies to integrate their strengths to improve downstream tasks. Additionally, we provide an in-depth discussion of the shortcomings of current GraphRAG approaches and outline directions for future research.
Building Rome with Convex Optimization
Feb 10, 2025



Global bundle adjustment is made easy by depth prediction and convex optimization. We (i) propose a scaled bundle adjustment (SBA) formulation that lifts 2D keypoint measurements to 3D with learned depth, (ii) design an empirically tight convex semidfinite program (SDP) relaxation that solves SBA to certfiable global optimality, (iii) solve the SDP relaxations at extreme scale with Burer-Monteiro factorization and a CUDA-based trust-region Riemannian optimizer (dubbed XM), (iv) build a structure from motion (SfM) pipeline with XM as the optimization engine and show that XM-SfM dominates or compares favorably with existing SfM pipelines in terms of reconstruction quality while being faster, more scalable, and initialization-free.