 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyberJurors: A Multi-Agent Simulation Task for E-Commerce Disputes Verdict
May 27, 2026E-commerce platforms have begun recruiting crowdsourced jurors to adjudicate massive volumes of transaction disputes. Unlike formal legal judgment, E-commerce dispute verdicts require grounding pivotal clues from redundant, multi-round, multimodal evidence and making decisions under flexible platform-specific conventions. These characteristics render existing methods insufficient for this scenario. To bridge this gap, we introduce a pioneering task, E-commerce Dispute Verdicts (EDV), and present VerdictBench, a multimodal benchmark comprising 6,000 real-world cases designed to reflect crowdsourced jury decisions. Building upon this, we propose CyberJurors, a multi-agent framework to clarify the dispute logic and regulate the verdict process. At the individual level, Individual Verdict Chain-of-Thought decomposes the EDV task into four structured reasoning stages, enabling fine-grained clue perception and clarifying causal logic between pivotal clues and the dispute focus. At the collective level, Jury Consensus Verdict simulates multi-round discussion and voting among jurors, while incorporating verdict precedents to mitigate cognitive biases toward either disputant. Experiments on VerdictBench show that CyberJurors outperforms state-of-the-art LLMs, MLLMs, and court simulators, while achieving stronger alignment with real-world jury voting patterns. Code and dataset are available at https://github.com/YanhuiS/CyberJurors and https://huggingface.co/datasets/piggi/VerdictBench.
EMS: Multi-Agent Voting via Efficient Majority-then-Stopping
Apr 03, 2026Majority voting is the standard for aggregating multi-agent responses into a final decision. However, traditional methods typically require all agents to complete their reasoning before aggregation begins, leading to significant computational overhead, as many responses become redundant once a majority consensus is achieved. In this work, we formulate the multi-agent voting as a reliability-aware agent scheduling problem, and propose an Efficient Majority-then-Stopping (EMS) to improve reasoning efficiency. EMS prioritizes agents based on task-aware reliability and terminates the reasoning pipeline the moment a majority is achieved from the following three critical components. Specifically, we introduce Agent Confidence Modeling (ACM) to estimate agent reliability using historical performance and semantic similarity, Adaptive Incremental Voting (AIV) to sequentially select agents with early stopping, and Individual Confidence Updating (ICU) to dynamically update the reliability of each contributing agent. Extensive evaluations across six benchmarks demonstrate that EMS consistently reduces the average number of invoked agents by 32%.
DA-Mamba: Learning Domain-Aware State Space Model for Global-Local Alignment in Domain Adaptive Object Detection
Mar 19, 2026Domain Adaptive Object Detection (DAOD) aims to transfer detectors from a labeled source domain to an unlabeled target domain. Existing DAOD methods employ multi-granularity feature alignment to learn domain-invariant representations. However, the local connectivity of their CNN-based backbone and detection head restricts alignment to local regions, failing to extract global domain-invariant features. Although transformer-based DAOD methods capture global dependencies via attention mechanisms, their quadratic computational cost hinders practical deployment. To solve this, we propose DA-Mamba, a hybrid CNN-State Space Models (SSMs) architecture that combines the efficiency of CNNs with the linear-time long-range modeling capability of State Space Models (SSMs) to capture both global and local domain-invariant features. Specifically, we introduce two novel modules: Image-Aware SSM (IA-SSM) and Object-Aware SSM (OA-SSM). IA-SSM is integrated into the backbone to enhance global domain awareness, enabling image-level global and local alignment. OA-SSM is inserted into the detection head to model spatial and semantic dependencies among objects, enhancing instance-level alignment. Comprehensive experiments demonstrate that the proposed method can efficiently improve the cross-domain performance of the object detector.
GUI-Eyes: Tool-Augmented Perception for Visual Grounding in GUI Agents
Jan 14, 2026Recent advances in vision-language models (VLMs) and reinforcement learning (RL) have driven progress in GUI automation. However, most existing methods rely on static, one-shot visual inputs and passive perception, lacking the ability to adaptively determine when, whether, and how to observe the interface. We present GUI-Eyes, a reinforcement learning framework for active visual perception in GUI tasks. To acquire more informative observations, the agent learns to make strategic decisions on both whether and how to invoke visual tools, such as cropping or zooming, within a two-stage reasoning process. To support this behavior, we introduce a progressive perception strategy that decomposes decision-making into coarse exploration and fine-grained grounding, coordinated by a two-level policy. In addition, we design a spatially continuous reward function tailored to tool usage, which integrates both location proximity and region overlap to provide dense supervision and alleviate the reward sparsity common in GUI environments. On the ScreenSpot-Pro benchmark, GUI-Eyes-3B achieves 44.8% grounding accuracy using only 3k labeled samples, significantly outperforming both supervised and RL-based baselines. These results highlight that tool-aware active perception, enabled by staged policy reasoning and fine-grained reward feedback, is critical for building robust and data-efficient GUI agents.
Locality Preserving Markovian Transition for Instance Retrieval
Jun 05, 2025Diffusion-based re-ranking methods are effective in modeling the data manifolds through similarity propagation in affinity graphs. However, positive signals tend to diminish over several steps away from the source, reducing discriminative power beyond local regions. To address this issue, we introduce the Locality Preserving Markovian Transition (LPMT) framework, which employs a long-term thermodynamic transition process with multiple states for accurate manifold distance measurement. The proposed LPMT first integrates diffusion processes across separate graphs using Bidirectional Collaborative Diffusion (BCD) to establish strong similarity relationships. Afterwards, Locality State Embedding (LSE) encodes each instance into a distribution for enhanced local consistency. These distributions are interconnected via the Thermodynamic Markovian Transition (TMT) process, enabling efficient global retrieval while maintaining local effectiveness. Experimental results across diverse tasks confirm the effectiveness of LPMT for instance retrieval.
Language Guided Concept Bottleneck Models for Interpretable Continual Learning
Mar 30, 2025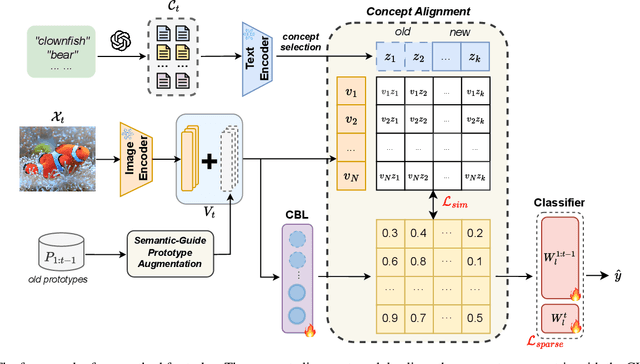
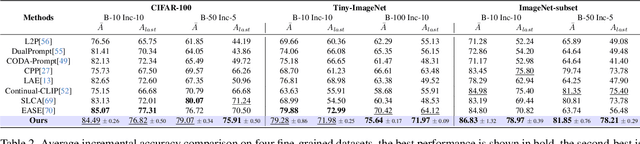
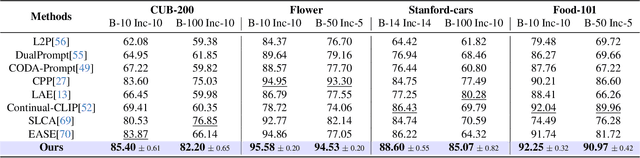
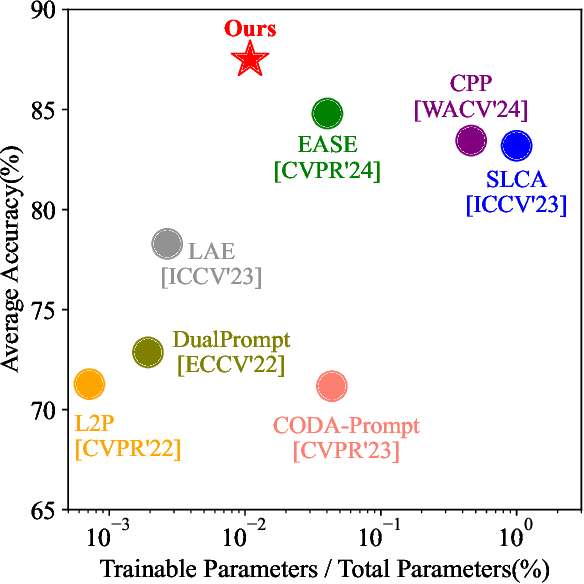
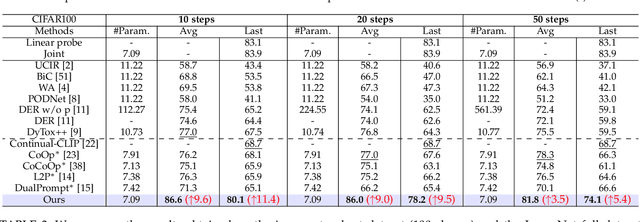
Continual learning (CL) aims to enable learning systems to acquire new knowledge constantly without forgetting previously learned information. CL faces the challenge of mitigating catastrophic forgetting while maintaining interpretability across tasks. Most existing CL methods focus primarily on preserving learned knowledge to improve model performance. However, as new information is introduced, the interpretability of the learning process becomes crucial for understanding the evolving decision-making process, yet it is rarely explored. In this paper, we introduce a novel framework that integrates language-guided Concept Bottleneck Models (CBMs) to address both challenges. Our approach leverages the Concept Bottleneck Layer, aligning semantic consistency with CLIP models to learn human-understandable concepts that can generalize across tasks. By focusing on interpretable concepts, our method not only enhances the models ability to retain knowledge over time but also provides transparent decision-making insights. We demonstrate the effectiveness of our approach by achieving superior performance on several datasets, outperforming state-of-the-art methods with an improvement of up to 3.06% in final average accuracy on ImageNet-subset. Additionally, we offer concept visualizations for model predictions, further advancing the understanding of interpretable continual learning.
DA-Ada: Learning Domain-Aware Adapter for Domain Adaptive Object Detection
Oct 11, 2024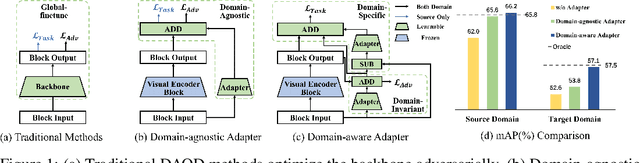
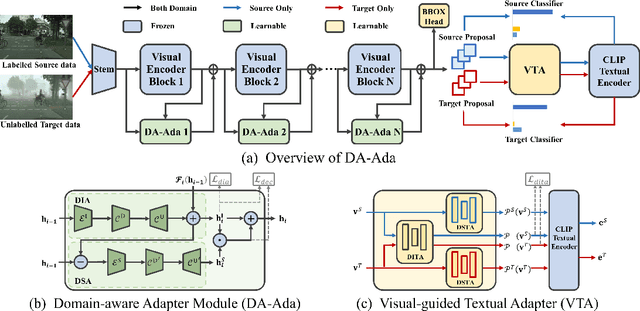
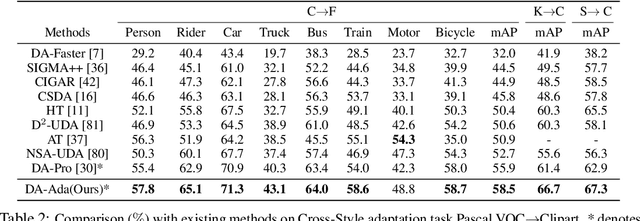
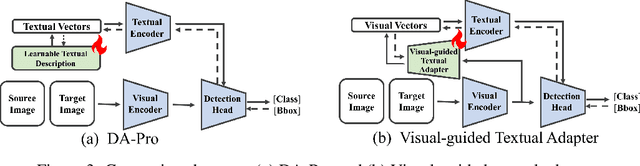
Domain adaptive object detection (DAOD) aims to generalize detectors trained on an annotated source domain to an unlabelled target domain. As the visual-language models (VLMs) can provide essential general knowledge on unseen images, freezing the visual encoder and inserting a domain-agnostic adapter can learn domain-invariant knowledge for DAOD. However, the domain-agnostic adapter is inevitably biased to the source domain. It discards some beneficial knowledge discriminative on the unlabelled domain, i.e., domain-specific knowledge of the target domain. To solve the issue, we propose a novel Domain-Aware Adapter (DA-Ada) tailored for the DAOD task. The key point is exploiting domain-specific knowledge between the essential general knowledge and domain-invariant knowledge. DA-Ada consists of the Domain-Invariant Adapter (DIA) for learning domain-invariant knowledge and the Domain-Specific Adapter (DSA) for injecting the domain-specific knowledge from the information discarded by the visual encoder. Comprehensive experiments over multiple DAOD tasks show that DA-Ada can efficiently infer a domain-aware visual encoder for boosting domain adaptive object detection. Our code is available at https://github.com/Therock90421/DA-Ada.
Exploiting the Semantic Knowledge of Pre-trained Text-Encoders for Continual Learning
Aug 02, 2024


Deep neural networks (DNNs) excel on fixed datasets but struggle with incremental and shifting data in real-world scenarios. Continual learning addresses this challenge by allowing models to learn from new data while retaining previously learned knowledge. Existing methods mainly rely on visual features, often neglecting the rich semantic information encoded in text. The semantic knowledge available in the label information of the images, offers important semantic information that can be related with previously acquired knowledge of semantic classes. Consequently, effectively leveraging this information throughout continual learning is expected to be beneficial. To address this, we propose integrating semantic guidance within and across tasks by capturing semantic similarity using text embeddings. We start from a pre-trained CLIP model, employ the \emph{Semantically-guided Representation Learning (SG-RL)} module for a soft-assignment towards all current task classes, and use the Semantically-guided Knowledge Distillation (SG-KD) module for enhanced knowledge transfer. Experimental results demonstrate the superiority of our method on general and fine-grained datasets. Our code can be found in https://github.com/aprilsveryown/semantically-guided-continual-learning.
Prompt-based Visual Alignment for Zero-shot Policy Transfer
Jun 05, 2024



Overfitting in RL has become one of the main obstacles to applications in reinforcement learning(RL). Existing methods do not provide explicit semantic constrain for the feature extractor, hindering the agent from learning a unified cross-domain representation and resulting in performance degradation on unseen domains. Besides, abundant data from multiple domains are needed. To address these issues, in this work, we propose prompt-based visual alignment (PVA), a robust framework to mitigate the detrimental domain bias in the image for zero-shot policy transfer. Inspired that Visual-Language Model (VLM) can serve as a bridge to connect both text space and image space, we leverage the semantic information contained in a text sequence as an explicit constraint to train a visual aligner. Thus, the visual aligner can map images from multiple domains to a unified domain and achieve good generalization performance. To better depict semantic information, prompt tuning is applied to learn a sequence of learnable tokens. With explicit constraints of semantic information, PVA can learn unified cross-domain representation under limited access to cross-domain data and achieves great zero-shot generalization ability in unseen domains. We verify PVA on a vision-based autonomous driving task with CARLA simulator. Experiments show that the agent generalizes well on unseen domains under limited access to multi-domain data.
Cluster-Aware Similarity Diffusion for Instance Retrieval
Jun 04, 2024


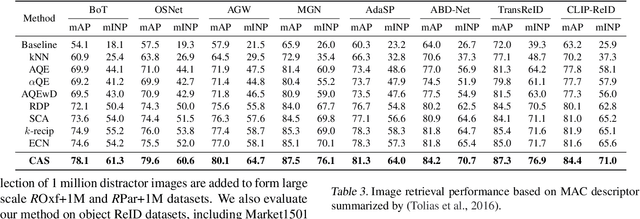
Diffusion-based re-ranking is a common method used for retrieving instances by performing similarity propagation in a nearest neighbor graph. However, existing techniques that construct the affinity graph based on pairwise instances can lead to the propagation of misinformation from outliers and other manifolds, resulting in inaccurate results. To overcome this issue, we propose a novel Cluster-Aware Similarity (CAS) diffusion for instance retrieval. The primary concept of CAS is to conduct similarity diffusion within local clusters, which can reduce the influence from other manifolds explicitly. To obtain a symmetrical and smooth similarity matrix, our Bidirectional Similarity Diffusion strategy introduces an inverse constraint term to the optimization objective of local cluster diffusion. Additionally, we have optimized a Neighbor-guided Similarity Smoothing approach to ensure similarity consistency among the local neighbors of each instance. Evaluations in instance retrieval and object re-identification validate the effectiveness of the proposed CAS, our code is publicly available.