 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDA-Mamba: Learning Domain-Aware State Space Model for Global-Local Alignment in Domain Adaptive Object Detection
Mar 19, 2026Domain Adaptive Object Detection (DAOD) aims to transfer detectors from a labeled source domain to an unlabeled target domain. Existing DAOD methods employ multi-granularity feature alignment to learn domain-invariant representations. However, the local connectivity of their CNN-based backbone and detection head restricts alignment to local regions, failing to extract global domain-invariant features. Although transformer-based DAOD methods capture global dependencies via attention mechanisms, their quadratic computational cost hinders practical deployment. To solve this, we propose DA-Mamba, a hybrid CNN-State Space Models (SSMs) architecture that combines the efficiency of CNNs with the linear-time long-range modeling capability of State Space Models (SSMs) to capture both global and local domain-invariant features. Specifically, we introduce two novel modules: Image-Aware SSM (IA-SSM) and Object-Aware SSM (OA-SSM). IA-SSM is integrated into the backbone to enhance global domain awareness, enabling image-level global and local alignment. OA-SSM is inserted into the detection head to model spatial and semantic dependencies among objects, enhancing instance-level alignment. Comprehensive experiments demonstrate that the proposed method can efficiently improve the cross-domain performance of the object detector.
Searth Transformer: A Transformer Architecture Incorporating Earth's Geospheric Physical Priors for Global Mid-Range Weather Forecasting
Jan 14, 2026Accurate global medium-range weather forecasting is fundamental to Earth system science. Most existing Transformer-based forecasting models adopt vision-centric architectures that neglect the Earth's spherical geometry and zonal periodicity. In addition, conventional autoregressive training is computationally expensive and limits forecast horizons due to error accumulation. To address these challenges, we propose the Shifted Earth Transformer (Searth Transformer), a physics-informed architecture that incorporates zonal periodicity and meridional boundaries into window-based self-attention for physically consistent global information exchange. We further introduce a Relay Autoregressive (RAR) fine-tuning strategy that enables learning long-range atmospheric evolution under constrained memory and computational budgets. Based on these methods, we develop YanTian, a global medium-range weather forecasting model. YanTian achieves higher accuracy than the high-resolution forecast of the European Centre for Medium-Range Weather Forecasts and performs competitively with state-of-the-art AI models at one-degree resolution, while requiring roughly 200 times lower computational cost than standard autoregressive fine-tuning. Furthermore, YanTian attains a longer skillful forecast lead time for Z500 (10.3 days) than HRES (9 days). Beyond weather forecasting, this work establishes a robust algorithmic foundation for predictive modeling of complex global-scale geophysical circulation systems, offering new pathways for Earth system science.
CRB minimization for PASS Assisted ISAC
Sep 26, 2025A multiple waveguide PASS assisted integrated sensing and communication (ISAC) system is proposed, where the base station (BS) is equipped with transmitting pinching antennas (PAs) and receiving uniform linear array (ULA) antennas. The PASS-transmitting-ULA-receiving (PTUR) BS transmits the communication and sensing signals through the stretched PAs on waveguides and collects the echo sensing signals with the mounted ULA. Based on this configuration, a target sensing Cramer Rao Bound (CRB) minimization problem is formulated under communication quality-of-service (QoS) constraints, power budget constraints, and PA deployment constraints. An alternating optimization (AO) method is employed to address the formulated non-convex optimization problem. Simulation results demonstrate that the proposed PASS assisted ISAC framework achieves superior performance over benchmark schemes.
Pinching Antenna System for Integrated Sensing and Communications
Aug 27, 2025Recently, the pinching antenna system (PASS) has attracted considerable attention due to their advantages in flexible deployment and reduction of signal propagation loss. In this work, a multiple waveguide PASS assisted integrated sensing and communication (ISAC) system is proposed, where the base station (BS) is equipped with transmitting pinching antennas (PAs) and receiving uniform linear array (ULA) antennas. The full-duplex (FD) BS transmits the communication and sensing signals through the PAs on waveguides and collects the echo sensing signals with the mounted ULA. Based on this configuration, a target sensing Cramer Rao Bound (CRB) minimization problem is formulated under communication quality-of-service (QoS) constraints, power budget constraint, and PA deployment constraints. The alternating optimization (AO) method is employed to address the formulated non-convex optimization problem. In each iteration, the overall optimization problem is decomposed into a digital beamforming sub-problem and a pinching beamforming sub-problem. The sensing covariance matrix and communication beamforming matrix at the BS are optimized by solving the digital beamforming sub-problem with semidefinite relaxation (SDR). The PA deployment is updated by solving the pinching beamforming sub-problem with the successive convex approximation (SCA) method, penalty method, and element-wise optimization. Simulation results show that the proposed PASS assisted ISAC framework achieves superior performance over benchmark schemes, is less affected by stringent communication constraints compared to conventional MIMO-ISAC, and benefits further from increasing the number of waveguides and PAs per waveguide.
QiMeng-Attention: SOTA Attention Operator is generated by SOTA Attention Algorithm
Jun 14, 2025The attention operator remains a critical performance bottleneck in large language models (LLMs), particularly for long-context scenarios. While FlashAttention is the most widely used and effective GPU-aware acceleration algorithm, it must require time-consuming and hardware-specific manual implementation, limiting adaptability across GPU architectures. Existing LLMs have shown a lot of promise in code generation tasks, but struggle to generate high-performance attention code. The key challenge is it cannot comprehend the complex data flow and computation process of the attention operator and utilize low-level primitive to exploit GPU performance. To address the above challenge, we propose an LLM-friendly Thinking Language (LLM-TL) to help LLMs decouple the generation of high-level optimization logic and low-level implementation on GPU, and enhance LLMs' understanding of attention operator. Along with a 2-stage reasoning workflow, TL-Code generation and translation, the LLMs can automatically generate FlashAttention implementation on diverse GPUs, establishing a self-optimizing paradigm for generating high-performance attention operators in attention-centric algorithms. Verified on A100, RTX8000, and T4 GPUs, the performance of our methods significantly outshines that of vanilla LLMs, achieving a speed-up of up to 35.16x. Besides, our method not only surpasses human-optimized libraries (cuDNN and official library) in most scenarios but also extends support to unsupported hardware and data types, reducing development time from months to minutes compared with human experts.
Continuum-Interaction-Driven Intelligence: Human-Aligned Neural Architecture via Crystallized Reasoning and Fluid Generation
Apr 12, 2025Current AI systems based on probabilistic neural networks, such as large language models (LLMs), have demonstrated remarkable generative capabilities yet face critical challenges including hallucination, unpredictability, and misalignment with human decision-making. These issues fundamentally stem from the over-reliance on randomized (probabilistic) neural networks-oversimplified models of biological neural networks-while neglecting the role of procedural reasoning (chain-of-thought) in trustworthy decision-making. Inspired by the human cognitive duality of fluid intelligence (flexible generation) and crystallized intelligence (structured knowledge), this study proposes a dual-channel intelligent architecture that integrates probabilistic generation (LLMs) with white-box procedural reasoning (chain-of-thought) to construct interpretable, continuously learnable, and human-aligned AI systems. Concretely, this work: (1) redefines chain-of-thought as a programmable crystallized intelligence carrier, enabling dynamic knowledge evolution and decision verification through multi-turn interaction frameworks; (2) introduces a task-driven modular network design that explicitly demarcates the functional boundaries between randomized generation and procedural control to address trustworthiness in vertical-domain applications; (3) demonstrates that multi-turn interaction is a necessary condition for intelligence emergence, with dialogue depth positively correlating with the system's human-alignment degree. This research not only establishes a new paradigm for trustworthy AI deployment but also provides theoretical foundations for next-generation human-AI collaborative systems.
Crowdsource, Crawl, or Generate? Creating SEA-VL, a Multicultural Vision-Language Dataset for Southeast Asia
Mar 10, 2025



Southeast Asia (SEA) is a region of extraordinary linguistic and cultural diversity, yet it remains significantly underrepresented in vision-language (VL) research. This often results in artificial intelligence (AI) models that fail to capture SEA cultural nuances. To fill this gap, we present SEA-VL, an open-source initiative dedicated to developing high-quality, culturally relevant data for SEA languages. By involving contributors from SEA countries, SEA-VL aims to ensure better cultural relevance and diversity, fostering greater inclusivity of underrepresented languages in VL research. Beyond crowdsourcing, our initiative goes one step further in the exploration of the automatic collection of culturally relevant images through crawling and image generation. First, we find that image crawling achieves approximately ~85% cultural relevance while being more cost- and time-efficient than crowdsourcing. Second, despite the substantial progress in generative vision models, synthetic images remain unreliable in accurately reflecting SEA cultures. The generated images often fail to reflect the nuanced traditions and cultural contexts of the region. Collectively, we gather 1.28M SEA culturally-relevant images, more than 50 times larger than other existing datasets. Through SEA-VL, we aim to bridge the representation gap in SEA, fostering the development of more inclusive AI systems that authentically represent diverse cultures across SEA.
MCTS-KBQA: Monte Carlo Tree Search for Knowledge Base Question Answering
Feb 19, 2025



This study explores how to enhance the reasoning capabilities of large language models (LLMs) in knowledge base question answering (KBQA) by leveraging Monte Carlo Tree Search (MCTS). Semantic parsing-based KBQA methods are particularly challenging as these approaches require locating elements from knowledge bases and generating logical forms, demanding not only extensive annotated data but also strong reasoning capabilities. Although recent approaches leveraging LLMs as agents have demonstrated considerable potential, these studies are inherently constrained by their linear decision-making processes. To address this limitation, we propose a MCTS-based framework that enhances LLMs' reasoning capabilities through tree search methodology. We design a carefully designed step-wise reward mechanism that requires only direct prompting of open-source instruction LLMs without additional fine-tuning. Experimental results demonstrate that our approach significantly outperforms linear decision-making methods, particularly in low-resource scenarios. Additionally, we contribute new data resources to the KBQA community by annotating intermediate reasoning processes for existing question-SPARQL datasets using distant supervision. Experimental results on the extended dataset demonstrate that our method achieves comparable performance to fully supervised models while using significantly less training data.
EDGE: Efficient Data Selection for LLM Agents via Guideline Effectiveness
Feb 18, 2025



Large Language Models (LLMs) have shown remarkable capabilities as AI agents. However, existing methods for enhancing LLM-agent abilities often lack a focus on data quality, leading to inefficiencies and suboptimal results in both fine-tuning and prompt engineering. To address this issue, we introduce EDGE, a novel approach for identifying informative samples without needing golden answers. We propose the Guideline Effectiveness (GE) metric, which selects challenging samples by measuring the impact of human-provided guidelines in multi-turn interaction tasks. A low GE score indicates that the human expertise required for a sample is missing from the guideline, making the sample more informative. By selecting samples with low GE scores, we can improve the efficiency and outcomes of both prompt engineering and fine-tuning processes for LLMs. Extensive experiments validate the performance of our method. Our method achieves competitive results on the HotpotQA and WebShop and datasets, requiring 75\% and 50\% less data, respectively, while outperforming existing methods. We also provide a fresh perspective on the data quality of LLM-agent fine-tuning.
GiFT: Gibbs Fine-Tuning for Code Generation
Feb 17, 2025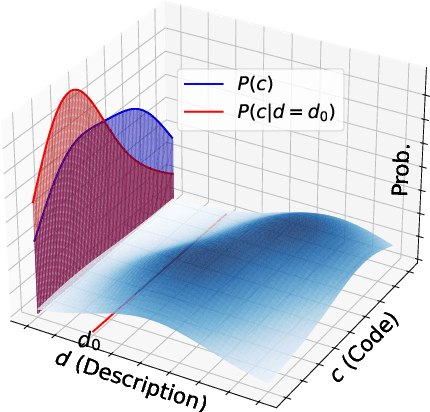



Training Large Language Models (LLMs) with synthetic data is a prevalent practice in code generation. A key approach is self-training, where LLMs are iteratively trained on self-generated correct code snippets. In this case, the self-generated codes are drawn from a conditional distribution, conditioned on a specific seed description. However, the seed description is not the only valid representation that aligns with its intended meaning. With all valid descriptions and codes forming a joint space, codes drawn from the conditional distribution would lead to an underrepresentation of the full description-code space. As such, we propose Gibbs Fine-Tuning (GiFT), a novel self-training method inspired by Gibbs sampling. GiFT allows self-generated data to be drawn from the marginal distribution of the joint space, thereby mitigating the biases inherent in conditional sampling. We provide a theoretical analysis demonstrating the potential benefits of fine-tuning LLMs with code derived from the marginal distribution. Furthermore, we propose a perplexity-based code selection method to mitigate the imbalanced long-tail distribution of the self-generated codes. Empirical evaluation of two LLMs across four datasets demonstrates that GiFT achieves superior performance, particularly on more challenging benchmarks.