 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEAR-KGQA: Clarification-Enhanced Ambiguity Resolution for Knowledge Graph Question Answering
Apr 13, 2025This study addresses the challenge of ambiguity in knowledge graph question answering (KGQA). While recent KGQA systems have made significant progress, particularly with the integration of large language models (LLMs), they typically assume user queries are unambiguous, which is an assumption that rarely holds in real-world applications. To address these limitations, we propose a novel framework that dynamically handles both entity ambiguity (e.g., distinguishing between entities with similar names) and intent ambiguity (e.g., clarifying different interpretations of user queries) through interactive clarification. Our approach employs a Bayesian inference mechanism to quantify query ambiguity and guide LLMs in determining when and how to request clarification from users within a multi-turn dialogue framework. We further develop a two-agent interaction framework where an LLM-based user simulator enables iterative refinement of logical forms through simulated user feedback. Experimental results on the WebQSP and CWQ dataset demonstrate that our method significantly improves performance by effectively resolving semantic ambiguities. Additionally, we contribute a refined dataset of disambiguated queries, derived from interaction histories, to facilitate future research in this direction.
MCTS-KBQA: Monte Carlo Tree Search for Knowledge Base Question Answering
Feb 19, 2025



This study explores how to enhance the reasoning capabilities of large language models (LLMs) in knowledge base question answering (KBQA) by leveraging Monte Carlo Tree Search (MCTS). Semantic parsing-based KBQA methods are particularly challenging as these approaches require locating elements from knowledge bases and generating logical forms, demanding not only extensive annotated data but also strong reasoning capabilities. Although recent approaches leveraging LLMs as agents have demonstrated considerable potential, these studies are inherently constrained by their linear decision-making processes. To address this limitation, we propose a MCTS-based framework that enhances LLMs' reasoning capabilities through tree search methodology. We design a carefully designed step-wise reward mechanism that requires only direct prompting of open-source instruction LLMs without additional fine-tuning. Experimental results demonstrate that our approach significantly outperforms linear decision-making methods, particularly in low-resource scenarios. Additionally, we contribute new data resources to the KBQA community by annotating intermediate reasoning processes for existing question-SPARQL datasets using distant supervision. Experimental results on the extended dataset demonstrate that our method achieves comparable performance to fully supervised models while using significantly less training data.
EDGE: Efficient Data Selection for LLM Agents via Guideline Effectiveness
Feb 18, 2025



Large Language Models (LLMs) have shown remarkable capabilities as AI agents. However, existing methods for enhancing LLM-agent abilities often lack a focus on data quality, leading to inefficiencies and suboptimal results in both fine-tuning and prompt engineering. To address this issue, we introduce EDGE, a novel approach for identifying informative samples without needing golden answers. We propose the Guideline Effectiveness (GE) metric, which selects challenging samples by measuring the impact of human-provided guidelines in multi-turn interaction tasks. A low GE score indicates that the human expertise required for a sample is missing from the guideline, making the sample more informative. By selecting samples with low GE scores, we can improve the efficiency and outcomes of both prompt engineering and fine-tuning processes for LLMs. Extensive experiments validate the performance of our method. Our method achieves competitive results on the HotpotQA and WebShop and datasets, requiring 75\% and 50\% less data, respectively, while outperforming existing methods. We also provide a fresh perspective on the data quality of LLM-agent fine-tuning.
Interactive-T2S: Multi-Turn Interactions for Text-to-SQL with Large Language Models
Aug 09, 2024
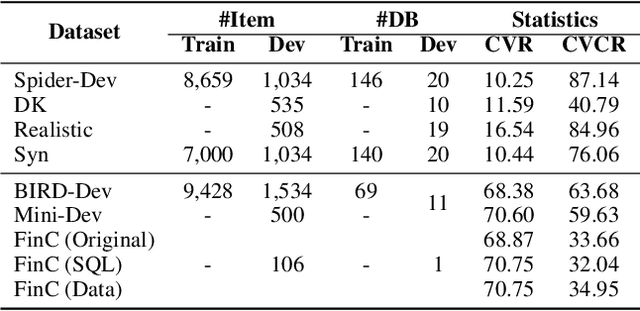
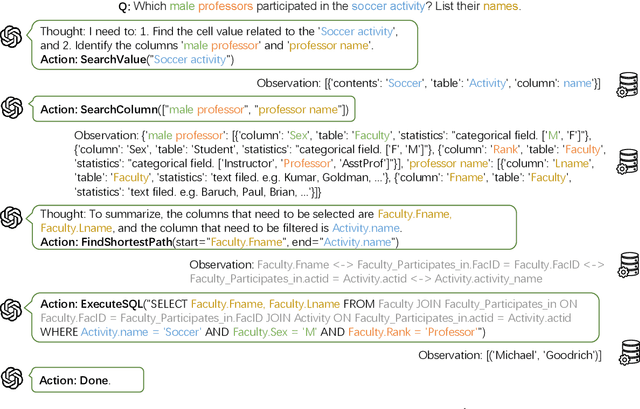
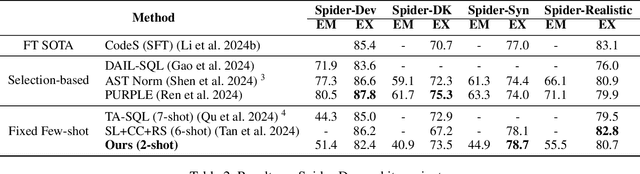
This study explores text-to-SQL parsing by leveraging the powerful reasoning capabilities of large language models (LLMs). Despite recent advancements, existing LLM-based methods have not adequately addressed scalability, leading to inefficiencies when processing wide tables. Furthermore, current interaction-based approaches either lack a step-by-step, interpretable SQL generation process or fail to provide an efficient and universally applicable interaction design. To address these challenges, we introduce Interactive-T2S, a framework that generates SQL queries through direct interactions with databases. This framework includes four general tools that facilitate proactive and efficient information retrieval by the LLM. Additionally, we have developed detailed exemplars to demonstrate the step-wise reasoning processes within our framework. Our experiments on the BIRD-Dev dataset, employing a setting without oracle knowledge, reveal that our method achieves state-of-the-art results with only two exemplars, underscoring the effectiveness and robustness of our framework.
Interactive-KBQA: Multi-Turn Interactions for Knowledge Base Question Answering with Large Language Models
Feb 23, 2024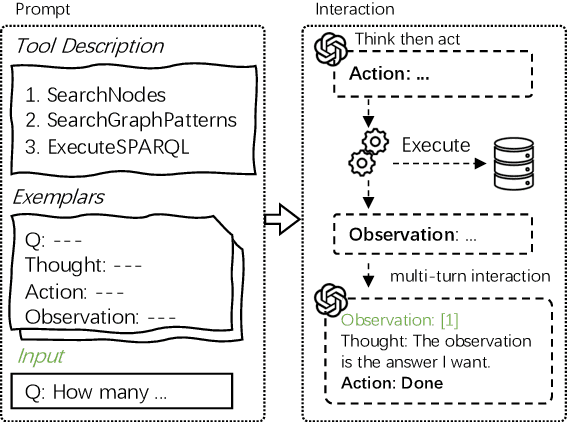
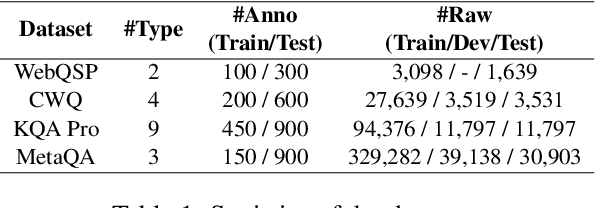
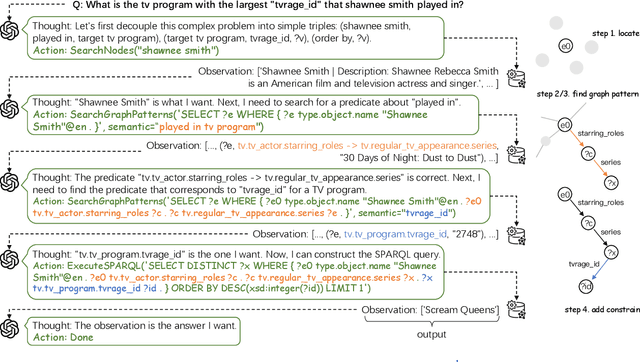
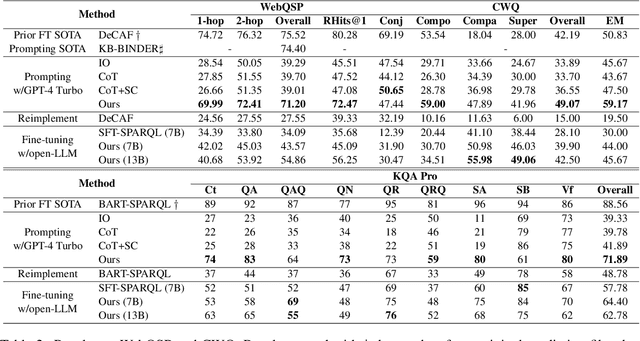
This study explores the realm of knowledge-base question answering (KBQA). KBQA is considered a challenging task, particularly in parsing intricate questions into executable logical forms. Traditional semantic parsing (SP)-based methods require extensive data annotations, which result in significant costs. Recently, the advent of few-shot in-context learning, powered by large language models (LLMs), has showcased promising capabilities. Yet, fully leveraging LLMs to parse questions into logical forms in low-resource scenarios poses a substantial challenge. To tackle these hurdles, we introduce Interactive-KBQA, a framework designed to generate logical forms through direct interaction with knowledge bases (KBs). Within this framework, we have developed three generic APIs for KB interaction. For each category of complex question, we devised exemplars to guide LLMs through the reasoning processes. Our method achieves competitive results on the WebQuestionsSP, ComplexWebQuestions, KQA Pro, and MetaQA datasets with a minimal number of examples (shots). Importantly, our approach supports manual intervention, allowing for the iterative refinement of LLM outputs. By annotating a dataset with step-wise reasoning processes, we showcase our model's adaptability and highlight its potential for contributing significant enhancements to the field.
AutoQGS: Auto-Prompt for Low-Resource Knowledge-based Question Generation from SPARQL
Aug 26, 2022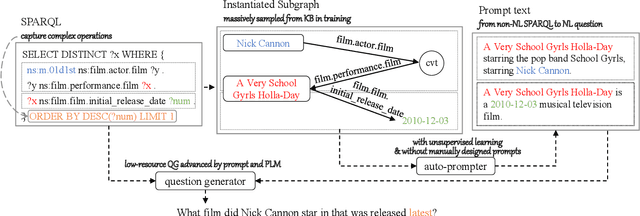
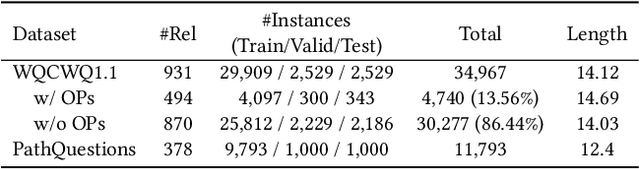
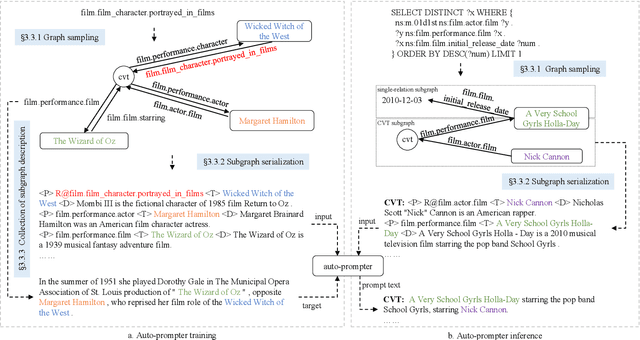
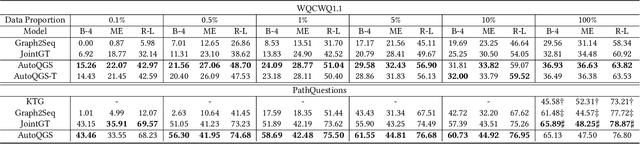
This study investigates the task of knowledge-based question generation (KBQG). Conventional KBQG works generated questions from fact triples in the knowledge graph, which could not express complex operations like aggregation and comparison in SPARQL. Moreover, due to the costly annotation of large-scale SPARQL-question pairs, KBQG from SPARQL under low-resource scenarios urgently needs to be explored. Recently, since the generative pre-trained language models (PLMs) typically trained in natural language (NL)-to-NL paradigm have been proven effective for low-resource generation, e.g., T5 and BART, how to effectively utilize them to generate NL-question from non-NL SPARQL is challenging. To address these challenges, AutoQGS, an auto-prompt approach for low-resource KBQG from SPARQL, is proposed. Firstly, we put forward to generate questions directly from SPARQL for the KBQG task to handle complex operations. Secondly, we propose an auto-prompter trained on large-scale unsupervised data to rephrase SPARQL into NL description, smoothing the low-resource transformation from non-NL SPARQL to NL question with PLMs. Experimental results on the WebQuestionsSP, ComlexWebQuestions 1.1, and PathQuestions show that our model achieves state-of-the-art performance, especially in low-resource settings. Furthermore, a corpus of 330k factoid complex question-SPARQL pairs is generated for further KBQG research.
Fine-tuning Multi-hop Question Answering with Hierarchical Graph Network
Apr 20, 2020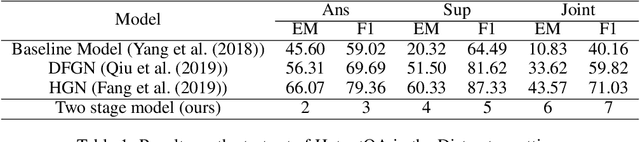
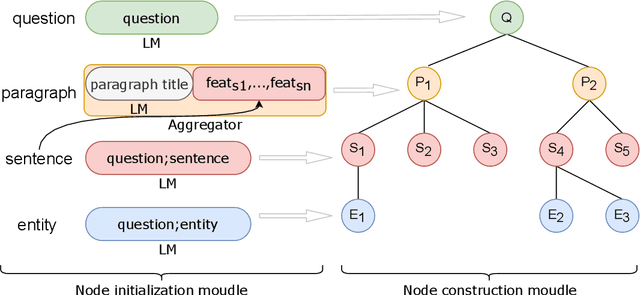
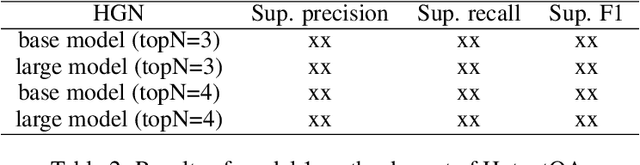
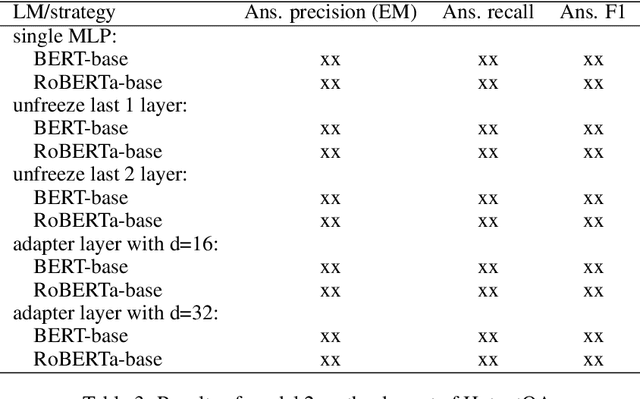
In this paper, we present a two stage model for multi-hop question answering. The first stage is a hierarchical graph network, which is used to reason over multi-hop question and is capable to capture different levels of granularity using the nature structure(i.e., paragraphs, questions, sentences and entities) of documents. The reasoning process is convert to node classify task(i.e., paragraph nodes and sentences nodes). The second stage is a language model fine-tuning task. In a word, stage one use graph neural network to select and concatenate support sentences as one paragraph, and stage two find the answer span in language model fine-tuning paradigm.