 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElo-Evolve: A Co-evolutionary Framework for Language Model Alignment
Feb 14, 2026Current alignment methods for Large Language Models (LLMs) rely on compressing vast amounts of human preference data into static, absolute reward functions, leading to data scarcity, noise sensitivity, and training instability. We introduce Elo-Evolve, a co-evolutionary framework that redefines alignment as dynamic multi-agent competition within an adaptive opponent pool. Our approach makes two key innovations: (1) eliminating Bradley-Terry model dependencies by learning directly from binary win/loss outcomes in pairwise competitions, and (2) implementing Elo-orchestrated opponent selection that provides automatic curriculum learning through temperature-controlled sampling. We ground our approach in PAC learning theory, demonstrating that pairwise comparison achieves superior sample complexity and empirically validate a 4.5x noise reduction compared to absolute scoring approaches. Experimentally, we train a Qwen2.5-7B model using our framework with opponents including Qwen2.5-14B, Qwen2.5-32B, and Qwen3-8B models. Results demonstrate a clear performance hierarchy: point-based methods < static pairwise training < Elo-Evolve across Alpaca Eval 2.0 and MT-Bench, validating the progressive benefits of pairwise comparison and dynamic opponent selection for LLM alignment.
GVPO: Group Variance Policy Optimization for Large Language Model Post-Training
Apr 28, 2025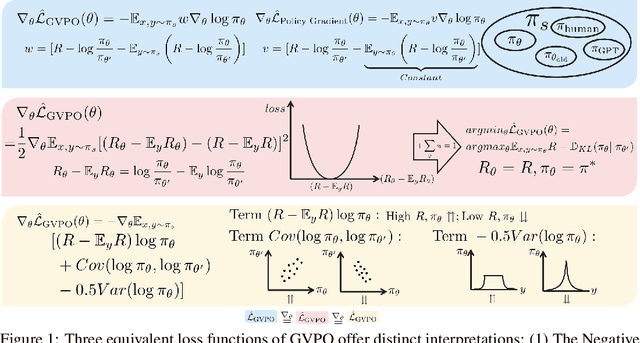
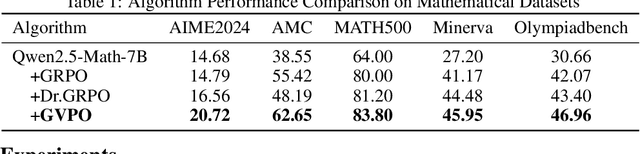

Post-training plays a crucial role in refining and aligning large language models to meet specific tasks and human preferences. While recent advancements in post-training techniques, such as Group Relative Policy Optimization (GRPO), leverage increased sampling with relative reward scoring to achieve superior performance, these methods often suffer from training instability that limits their practical adoption. To address this challenge, we present Group Variance Policy Optimization (GVPO). GVPO incorporates the analytical solution to KL-constrained reward maximization directly into its gradient weights, ensuring alignment with the optimal policy. The method provides intuitive physical interpretations: its gradient mirrors the mean squared error between the central distance of implicit rewards and that of actual rewards. GVPO offers two key advantages: (1) it guarantees a unique optimal solution, exactly the KL-constrained reward maximization objective, (2) it supports flexible sampling distributions that avoids on-policy and importance sampling limitations. By unifying theoretical guarantees with practical adaptability, GVPO establishes a new paradigm for reliable and versatile LLM post-training.
Energy-Based Preference Model Offers Better Offline Alignment than the Bradley-Terry Preference Model
Dec 18, 2024



Since the debut of DPO, it has been shown that aligning a target LLM with human preferences via the KL-constrained RLHF loss is mathematically equivalent to a special kind of reward modeling task. Concretely, the task requires: 1) using the target LLM to parameterize the reward model, and 2) tuning the reward model so that it has a 1:1 linear relationship with the true reward. However, we identify a significant issue: the DPO loss might have multiple minimizers, of which only one satisfies the required linearity condition. The problem arises from a well-known issue of the underlying Bradley-Terry preference model: it does not always have a unique maximum likelihood estimator (MLE). Consequently,the minimizer of the RLHF loss might be unattainable because it is merely one among many minimizers of the DPO loss. As a better alternative, we propose an energy-based model (EBM) that always has a unique MLE, inherently satisfying the linearity requirement. To approximate the MLE in practice, we propose a contrastive loss named Energy Preference Alignment (EPA), wherein each positive sample is contrasted against one or more strong negatives as well as many free weak negatives. Theoretical properties of our EBM enable the approximation error of EPA to almost surely vanish when a sufficient number of negatives are used. Empirically, we demonstrate that EPA consistently delivers better performance on open benchmarks compared to DPO, thereby showing the superiority of our EBM.
Preference-Oriented Supervised Fine-Tuning: Favoring Target Model Over Aligned Large Language Models
Dec 17, 2024



Alignment, endowing a pre-trained Large language model (LLM) with the ability to follow instructions, is crucial for its real-world applications. Conventional supervised fine-tuning (SFT) methods formalize it as causal language modeling typically with a cross-entropy objective, requiring a large amount of high-quality instruction-response pairs. However, the quality of widely used SFT datasets can not be guaranteed due to the high cost and intensive labor for the creation and maintenance in practice. To overcome the limitations associated with the quality of SFT datasets, we introduce a novel \textbf{p}reference-\textbf{o}riented supervised \textbf{f}ine-\textbf{t}uning approach, namely PoFT. The intuition is to boost SFT by imposing a particular preference: \textit{favoring the target model over aligned LLMs on the same SFT data.} This preference encourages the target model to predict a higher likelihood than that predicted by the aligned LLMs, incorporating assessment information on data quality (i.e., predicted likelihood by the aligned LLMs) into the training process. Extensive experiments are conducted, and the results validate the effectiveness of the proposed method. PoFT achieves stable and consistent improvements over the SFT baselines across different training datasets and base models. Moreover, we prove that PoFT can be integrated with existing SFT data filtering methods to achieve better performance, and further improved by following preference optimization procedures, such as DPO.
BoRA: Bi-dimensional Weight-Decomposed Low-Rank Adaptation
Dec 09, 2024



In recent years, Parameter-Efficient Fine-Tuning (PEFT) methods like Low-Rank Adaptation (LoRA) have significantly enhanced the adaptability of large-scale pre-trained models. Weight-Decomposed Low-Rank Adaptation (DoRA) improves upon LoRA by separating the magnitude and direction components of the weight matrix, leading to superior performance. However, DoRA's improvements are limited to the vertical dimension, resulting in an asymmetrical pattern between horizontal and vertical dimensions. This paper introduces BoRA, an innovative extension of LoRA and DoRA, characterized by symmetrical properties across horizontal and vertical dimensions. Our approach optimizes the weight matrix symmetrically by adjusting both column-wise and row-wise magnitudes. Extensive experiments demonstrate that BoRA surpasses state-of-the-art PEFT methods, including LoRA and DoRA, achieving superior results across various benchmarks.
Interactive-T2S: Multi-Turn Interactions for Text-to-SQL with Large Language Models
Aug 09, 2024
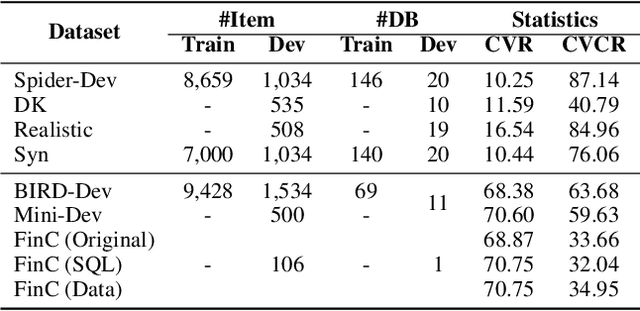
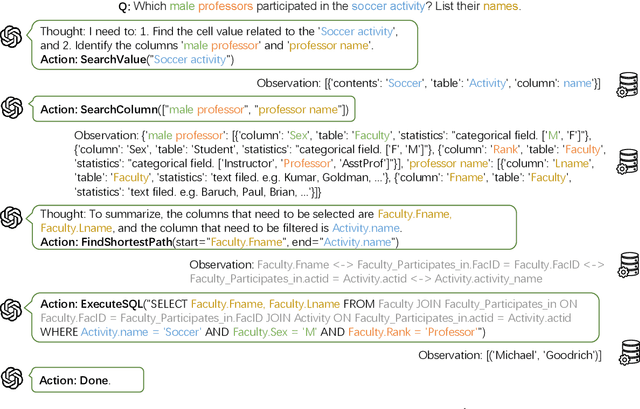
This study explores text-to-SQL parsing by leveraging the powerful reasoning capabilities of large language models (LLMs). Despite recent advancements, existing LLM-based methods have not adequately addressed scalability, leading to inefficiencies when processing wide tables. Furthermore, current interaction-based approaches either lack a step-by-step, interpretable SQL generation process or fail to provide an efficient and universally applicable interaction design. To address these challenges, we introduce Interactive-T2S, a framework that generates SQL queries through direct interactions with databases. This framework includes four general tools that facilitate proactive and efficient information retrieval by the LLM. Additionally, we have developed detailed exemplars to demonstrate the step-wise reasoning processes within our framework. Our experiments on the BIRD-Dev dataset, employing a setting without oracle knowledge, reveal that our method achieves state-of-the-art results with only two exemplars, underscoring the effectiveness and robustness of our framework.
A calcium imaging large dataset reveals novel functional organization in macaque V4
Jul 03, 2023The topological organization and feature preferences of primate visual area V4 have been primarily studied using artificial stimuli. Here, we combined large-scale calcium imaging with deep learning methods to characterize and understand how V4 processes natural images. By fitting a deep learning model to an unprecedentedly large dataset of columnar scale cortical responses to tens of thousands of natural stimuli and using the model to identify the images preferred by each cortical pixel, we obtained a detailed V4 topographical map of natural stimulus preference. The map contains distinct functional domains preferring a variety of natural image features, ranging from surface-related features such as color and texture to shape-related features such as edge, curvature, and facial features. These predicted domains were verified by additional widefield calcium imaging and single-cell resolution two-photon imaging. Our study reveals the systematic topological organization of V4 for encoding image features in natural scenes.
Uncertainty Sentence Sampling by Virtual Adversarial Perturbation
Oct 27, 2022
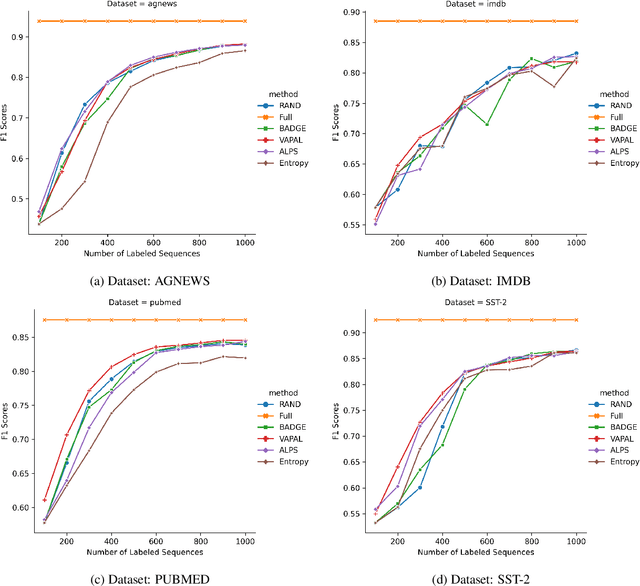
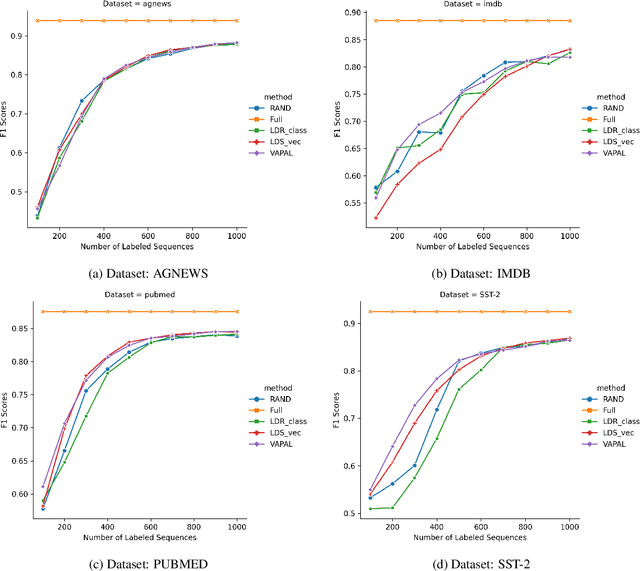
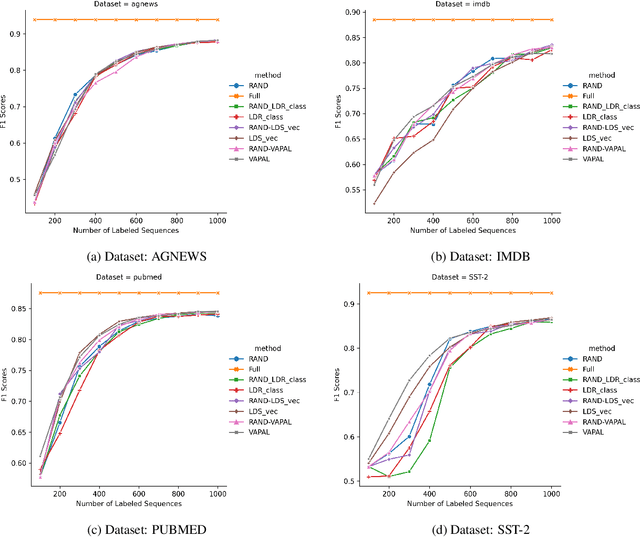
Active learning for sentence understanding attempts to reduce the annotation cost by identifying the most informative examples. Common methods for active learning use either uncertainty or diversity sampling in the pool-based scenario. In this work, to incorporate both predictive uncertainty and sample diversity, we propose Virtual Adversarial Perturbation for Active Learning (VAPAL) , an uncertainty-diversity combination framework, using virtual adversarial perturbation (Miyato et al., 2019) as model uncertainty representation. VAPAL consistently performs equally well or even better than the strong baselines on four sentence understanding datasets: AGNEWS, IMDB, PUBMED, and SST-2, offering a potential option for active learning on sentence understanding tasks.