 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Rapid Contextual Learning in the Visual Cortex with Fast-Weight Deep Autoencoder Networks
Aug 07, 2025Recent neurophysiological studies have revealed that the early visual cortex can rapidly learn global image context, as evidenced by a sparsification of population responses and a reduction in mean activity when exposed to familiar versus novel image contexts. This phenomenon has been attributed primarily to local recurrent interactions, rather than changes in feedforward or feedback pathways, supported by both empirical findings and circuit-level modeling. Recurrent neural circuits capable of simulating these effects have been shown to reshape the geometry of neural manifolds, enhancing robustness and invariance to irrelevant variations. In this study, we employ a Vision Transformer (ViT)-based autoencoder to investigate, from a functional perspective, how familiarity training can induce sensitivity to global context in the early layers of a deep neural network. We hypothesize that rapid learning operates via fast weights, which encode transient or short-term memory traces, and we explore the use of Low-Rank Adaptation (LoRA) to implement such fast weights within each Transformer layer. Our results show that (1) The proposed ViT-based autoencoder's self-attention circuit performs a manifold transform similar to a neural circuit model of the familiarity effect. (2) Familiarity training aligns latent representations in early layers with those in the top layer that contains global context information. (3) Familiarity training broadens the self-attention scope within the remembered image context. (4) These effects are significantly amplified by LoRA-based fast weights. Together, these findings suggest that familiarity training introduces global sensitivity to earlier layers in a hierarchical network, and that a hybrid fast-and-slow weight architecture may provide a viable computational model for studying rapid global context learning in the brain.
Incremental Learning and Self-Attention Mechanisms Improve Neural System Identification
Jun 12, 2024



Convolutional neural networks (CNNs) have been shown to be the state-of-the-art approach for modeling the transfer functions of visual cortical neurons. Cortical neurons in the primary visual cortex are are sensitive to contextual information mediated by extensive horizontal and feedback connections. Standard CNNs can integrate global spatial image information to model such contextual modulation via two mechanisms: successive rounds of convolutions and a fully connected readout layer. In this paper, we find that non-local networks or self-attention (SA) mechanisms, theoretically related to context-dependent flexible gating mechanisms observed in the primary visual cortex, improve neural response predictions over parameter-matched CNNs in two key metrics: tuning curve correlation and tuning peak. We factorize networks to determine the relative contribution of each context mechanism. This reveals that information in the local receptive field is most important for modeling the overall tuning curve, but surround information is critically necessary for characterizing the tuning peak. We find that self-attention can replace subsequent spatial-integration convolutions when learned in an incremental manner, and is further enhanced in the presence of a fully connected readout layer, suggesting that the two context mechanisms are complementary. Finally, we find that learning a receptive-field-centric model with self-attention, before incrementally learning a fully connected readout, yields a more biologically realistic model in terms of center-surround contributions.
Emergence of Shape Bias in Convolutional Neural Networks through Activation Sparsity
Oct 29, 2023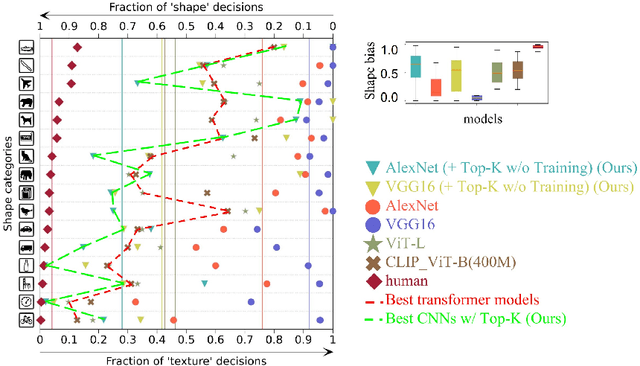



Current deep-learning models for object recognition are known to be heavily biased toward texture. In contrast, human visual systems are known to be biased toward shape and structure. What could be the design principles in human visual systems that led to this difference? How could we introduce more shape bias into the deep learning models? In this paper, we report that sparse coding, a ubiquitous principle in the brain, can in itself introduce shape bias into the network. We found that enforcing the sparse coding constraint using a non-differential Top-K operation can lead to the emergence of structural encoding in neurons in convolutional neural networks, resulting in a smooth decomposition of objects into parts and subparts and endowing the networks with shape bias. We demonstrated this emergence of shape bias and its functional benefits for different network structures with various datasets. For object recognition convolutional neural networks, the shape bias leads to greater robustness against style and pattern change distraction. For the image synthesis generative adversary networks, the emerged shape bias leads to more coherent and decomposable structures in the synthesized images. Ablation studies suggest that sparse codes tend to encode structures, whereas the more distributed codes tend to favor texture. Our code is host at the github repository: \url{https://github.com/Crazy-Jack/nips2023_shape_vs_texture}
Does resistance to Style-Transfer equal Shape Bias? Evaluating Shape Bias by Distorted Shape
Oct 11, 2023Deep learning models are known to exhibit a strong texture bias, while human tends to rely heavily on global shape for object recognition. The current benchmark for evaluating a model's shape bias is a set of style-transferred images with the assumption that resistance to the attack of style transfer is related to the development of shape sensitivity in the model. In this work, we show that networks trained with style-transfer images indeed learn to ignore style, but its shape bias arises primarily from local shapes. We provide a Distorted Shape Testbench (DiST) as an alternative measurement of global shape sensitivity. Our test includes 2400 original images from ImageNet-1K, each of which is accompanied by two images with the global shapes of the original image distorted while preserving its texture via the texture synthesis program. We found that (1) models that performed well on the previous shape bias evaluation do not fare well in the proposed DiST; (2) the widely adopted ViT models do not show significant advantages over Convolutional Neural Networks (CNNs) on this benchmark despite that ViTs rank higher on the previous shape bias tests. (3) training with DiST images bridges the significant gap between human and existing SOTA models' performance while preserving the models' accuracy on standard image classification tasks; training with DiST images and style-transferred images are complementary, and can be combined to train network together to enhance both the global and local shape sensitivity of the network. Our code will be host at: https://github.com/leelabcnbc/DiST
A calcium imaging large dataset reveals novel functional organization in macaque V4
Jul 03, 2023The topological organization and feature preferences of primate visual area V4 have been primarily studied using artificial stimuli. Here, we combined large-scale calcium imaging with deep learning methods to characterize and understand how V4 processes natural images. By fitting a deep learning model to an unprecedentedly large dataset of columnar scale cortical responses to tens of thousands of natural stimuli and using the model to identify the images preferred by each cortical pixel, we obtained a detailed V4 topographical map of natural stimulus preference. The map contains distinct functional domains preferring a variety of natural image features, ranging from surface-related features such as color and texture to shape-related features such as edge, curvature, and facial features. These predicted domains were verified by additional widefield calcium imaging and single-cell resolution two-photon imaging. Our study reveals the systematic topological organization of V4 for encoding image features in natural scenes.
Relating Human Perception of Musicality to Prediction in a Predictive Coding Model
Oct 29, 2022



We explore the use of a neural network inspired by predictive coding for modeling human music perception. This network was developed based on the computational neuroscience theory of recurrent interactions in the hierarchical visual cortex. When trained with video data using self-supervised learning, the model manifests behaviors consistent with human visual illusions. Here, we adapt this network to model the hierarchical auditory system and investigate whether it will make similar choices to humans regarding the musicality of a set of random pitch sequences. When the model is trained with a large corpus of instrumental classical music and popular melodies rendered as mel spectrograms, it exhibits greater prediction errors for random pitch sequences that are rated less musical by human subjects. We found that the prediction error depends on the amount of information regarding the subsequent note, the pitch interval, and the temporal context. Our findings suggest that predictability is correlated with human perception of musicality and that a predictive coding neural network trained on music can be used to characterize the features and motifs contributing to human perception of music.
SurfGen: Adversarial 3D Shape Synthesis with Explicit Surface Discriminators
Jan 01, 2022
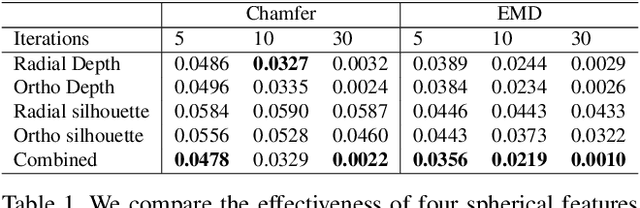

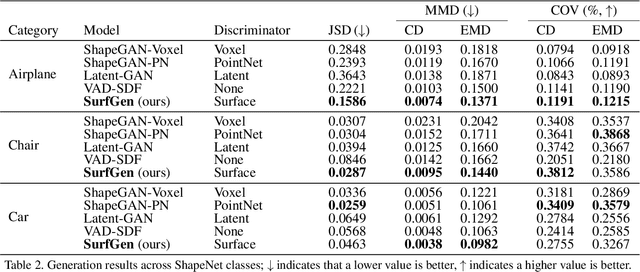
Recent advances in deep generative models have led to immense progress in 3D shape synthesis. While existing models are able to synthesize shapes represented as voxels, point-clouds, or implicit functions, these methods only indirectly enforce the plausibility of the final 3D shape surface. Here we present a 3D shape synthesis framework (SurfGen) that directly applies adversarial training to the object surface. Our approach uses a differentiable spherical projection layer to capture and represent the explicit zero isosurface of an implicit 3D generator as functions defined on the unit sphere. By processing the spherical representation of 3D object surfaces with a spherical CNN in an adversarial setting, our generator can better learn the statistics of natural shape surfaces. We evaluate our model on large-scale shape datasets, and demonstrate that the end-to-end trained model is capable of generating high fidelity 3D shapes with diverse topology.
Recurrent circuits as multi-path ensembles for modeling responses of early visual cortical neurons
Oct 02, 2021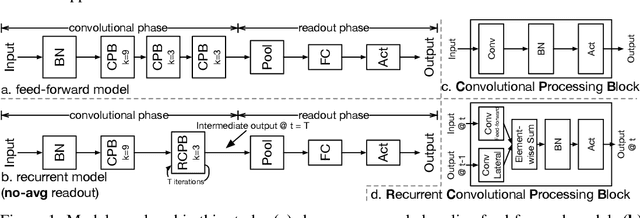

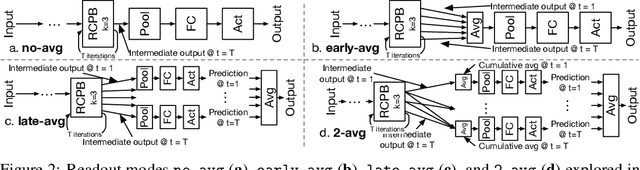
In this paper, we showed that adding within-layer recurrent connections to feed-forward neural network models could improve the performance of neural response prediction in early visual areas by up to 11 percent across different data sets and over tens of thousands of model configurations. To understand why recurrent models perform better, we propose that recurrent computation can be conceptualized as an ensemble of multiple feed-forward pathways of different lengths with shared parameters. By reformulating a recurrent model as a multi-path model and analyzing the recurrent model through its multi-path ensemble, we found that the recurrent model outperformed the corresponding feed-forward one due to the former's compact and implicit multi-path ensemble that allows approximating the complex function underlying recurrent biological circuits with efficiency. In addition, we found that the performance differences among recurrent models were highly correlated with the differences in their multi-path ensembles in terms of path lengths and path diversity; a balance of paths of different lengths in the ensemble was necessary for the model to achieve the best performance. Our studies shed light on the computational rationales and advantages of recurrent circuits for neural modeling and machine learning tasks in general.
Recurrent Feedback Improves Feedforward Representations in Deep Neural Networks
Dec 22, 2019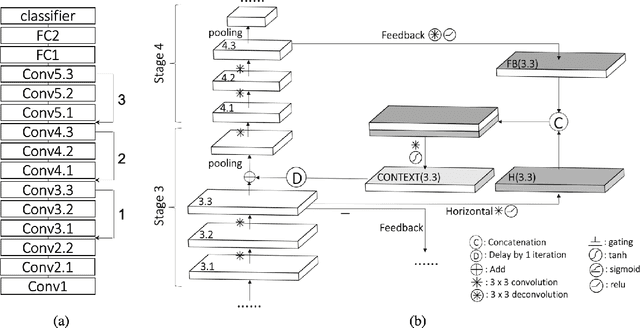


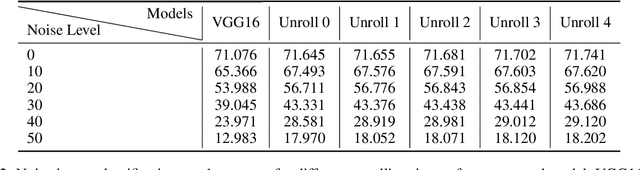
The abundant recurrent horizontal and feedback connections in the primate visual cortex are thought to play an important role in bringing global and semantic contextual information to early visual areas during perceptual inference, helping to resolve local ambiguity and fill in missing details. In this study, we find that introducing feedback loops and horizontal recurrent connections to a deep convolution neural network (VGG16) allows the network to become more robust against noise and occlusion during inference, even in the initial feedforward pass. This suggests that recurrent feedback and contextual modulation transform the feedforward representations of the network in a meaningful and interesting way. We study the population codes of neurons in the network, before and after learning with feedback, and find that learning with feedback yielded an increase in discriminability (measured by d-prime) between the different object classes in the population codes of the neurons in the feedforward path, even at the earliest layer that receives feedback. We find that recurrent feedback, by injecting top-down semantic meaning to the population activities, helps the network learn better feedforward paths to robustly map noisy image patches to the latent representations corresponding to important visual concepts of each object class, resulting in greater robustness of the network against noises and occlusion as well as better fine-grained recognition.
A Neurally-Inspired Hierarchical Prediction Network for Spatiotemporal Sequence Learning and Prediction
Jan 25, 2019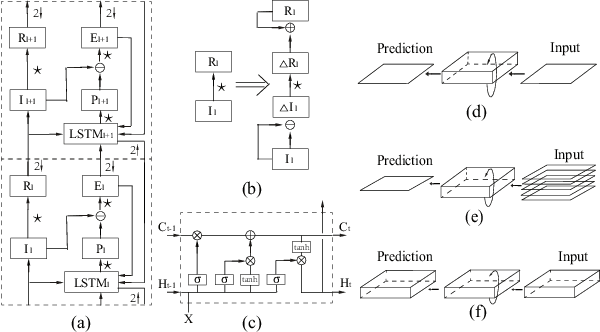
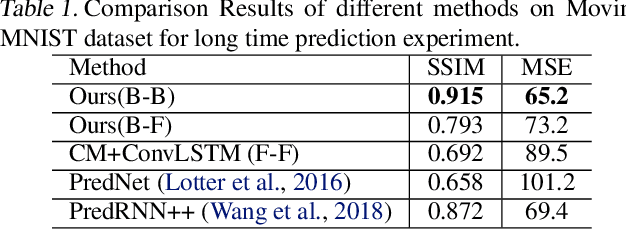
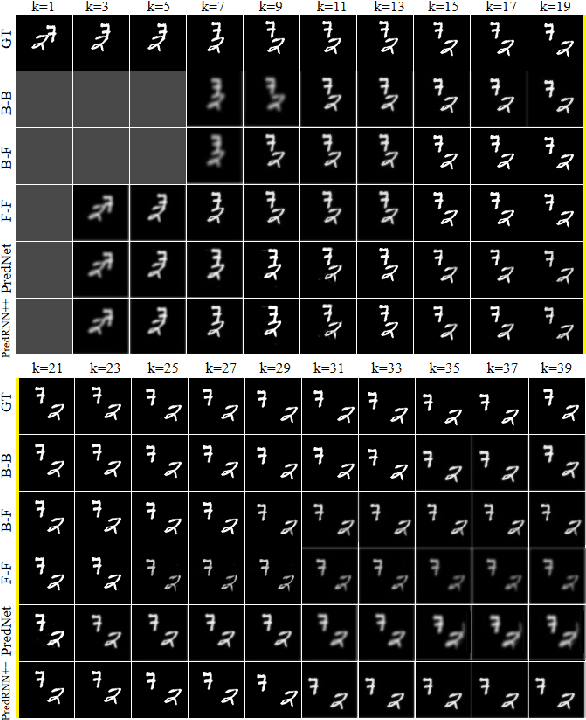

In this paper we developed a hierarchical network model, called Hierarchical Prediction Network (HPNet), to understand how spatiotemporal memories might be learned and encoded in the recurrent circuits in the visual cortical hierarchy for predicting future video frames. This neurally inspired model operates in the analysis-by-synthesis framework. It contains a feed-forward path that computes and encodes spatiotemporal features of successive complexity and a feedback path for the successive levels to project their interpretations to the level below. Within each level, the feed-forward path and the feedback path intersect in a recurrent gated circuit, instantiated in a LSTM module, to generate a prediction or explanation of the incoming signals. The network learns its internal model of the world by minimizing the errors of its prediction of the incoming signals at each level of the hierarchy. We found that hierarchical interaction in the network increases semantic clustering of global movement patterns in the population codes of the units along the hierarchy, even in the earliest module. This facilitates the learning of relationships among movement patterns, yielding state-of-the-art performance in long range video sequence predictions in the benchmark datasets. The network model automatically reproduces a variety of prediction suppression and familiarity suppression neurophysiological phenomena observed in the visual cortex, suggesting that hierarchical prediction might indeed be an important principle for representational learning in the visual cortex.