 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Reaction Time to Comprehend Scenes with Foveated Scene Understanding Maps
May 19, 2025Although models exist that predict human response times (RTs) in tasks such as target search and visual discrimination, the development of image-computable predictors for scene understanding time remains an open challenge. Recent advances in vision-language models (VLMs), which can generate scene descriptions for arbitrary images, combined with the availability of quantitative metrics for comparing linguistic descriptions, offer a new opportunity to model human scene understanding. We hypothesize that the primary bottleneck in human scene understanding and the driving source of variability in response times across scenes is the interaction between the foveated nature of the human visual system and the spatial distribution of task-relevant visual information within an image. Based on this assumption, we propose a novel image-computable model that integrates foveated vision with VLMs to produce a spatially resolved map of scene understanding as a function of fixation location (Foveated Scene Understanding Map, or F-SUM), along with an aggregate F-SUM score. This metric correlates with average (N=17) human RTs (r=0.47) and number of saccades (r=0.51) required to comprehend a scene (across 277 scenes). The F-SUM score also correlates with average (N=16) human description accuracy (r=-0.56) in time-limited presentations. These correlations significantly exceed those of standard image-based metrics such as clutter, visual complexity, and scene ambiguity based on language entropy. Together, our work introduces a new image-computable metric for predicting human response times in scene understanding and demonstrates the importance of foveated visual processing in shaping comprehension difficulty.
Emergence of Shape Bias in Convolutional Neural Networks through Activation Sparsity
Oct 29, 2023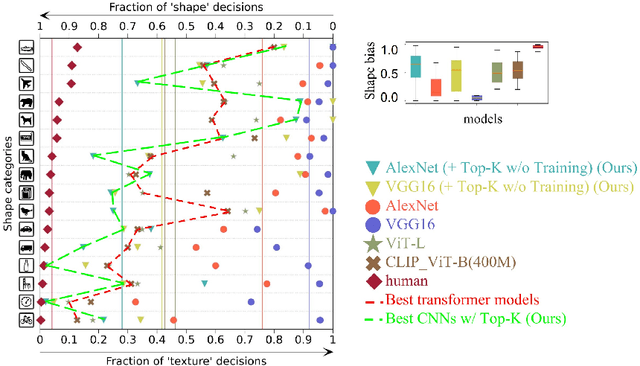



Current deep-learning models for object recognition are known to be heavily biased toward texture. In contrast, human visual systems are known to be biased toward shape and structure. What could be the design principles in human visual systems that led to this difference? How could we introduce more shape bias into the deep learning models? In this paper, we report that sparse coding, a ubiquitous principle in the brain, can in itself introduce shape bias into the network. We found that enforcing the sparse coding constraint using a non-differential Top-K operation can lead to the emergence of structural encoding in neurons in convolutional neural networks, resulting in a smooth decomposition of objects into parts and subparts and endowing the networks with shape bias. We demonstrated this emergence of shape bias and its functional benefits for different network structures with various datasets. For object recognition convolutional neural networks, the shape bias leads to greater robustness against style and pattern change distraction. For the image synthesis generative adversary networks, the emerged shape bias leads to more coherent and decomposable structures in the synthesized images. Ablation studies suggest that sparse codes tend to encode structures, whereas the more distributed codes tend to favor texture. Our code is host at the github repository: \url{https://github.com/Crazy-Jack/nips2023_shape_vs_texture}
Does resistance to Style-Transfer equal Shape Bias? Evaluating Shape Bias by Distorted Shape
Oct 11, 2023Deep learning models are known to exhibit a strong texture bias, while human tends to rely heavily on global shape for object recognition. The current benchmark for evaluating a model's shape bias is a set of style-transferred images with the assumption that resistance to the attack of style transfer is related to the development of shape sensitivity in the model. In this work, we show that networks trained with style-transfer images indeed learn to ignore style, but its shape bias arises primarily from local shapes. We provide a Distorted Shape Testbench (DiST) as an alternative measurement of global shape sensitivity. Our test includes 2400 original images from ImageNet-1K, each of which is accompanied by two images with the global shapes of the original image distorted while preserving its texture via the texture synthesis program. We found that (1) models that performed well on the previous shape bias evaluation do not fare well in the proposed DiST; (2) the widely adopted ViT models do not show significant advantages over Convolutional Neural Networks (CNNs) on this benchmark despite that ViTs rank higher on the previous shape bias tests. (3) training with DiST images bridges the significant gap between human and existing SOTA models' performance while preserving the models' accuracy on standard image classification tasks; training with DiST images and style-transferred images are complementary, and can be combined to train network together to enhance both the global and local shape sensitivity of the network. Our code will be host at: https://github.com/leelabcnbc/DiST