 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergence of Shape Bias in Convolutional Neural Networks through Activation Sparsity
Oct 29, 2023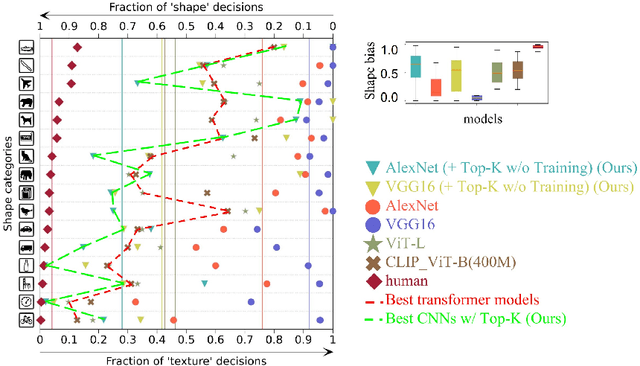



Current deep-learning models for object recognition are known to be heavily biased toward texture. In contrast, human visual systems are known to be biased toward shape and structure. What could be the design principles in human visual systems that led to this difference? How could we introduce more shape bias into the deep learning models? In this paper, we report that sparse coding, a ubiquitous principle in the brain, can in itself introduce shape bias into the network. We found that enforcing the sparse coding constraint using a non-differential Top-K operation can lead to the emergence of structural encoding in neurons in convolutional neural networks, resulting in a smooth decomposition of objects into parts and subparts and endowing the networks with shape bias. We demonstrated this emergence of shape bias and its functional benefits for different network structures with various datasets. For object recognition convolutional neural networks, the shape bias leads to greater robustness against style and pattern change distraction. For the image synthesis generative adversary networks, the emerged shape bias leads to more coherent and decomposable structures in the synthesized images. Ablation studies suggest that sparse codes tend to encode structures, whereas the more distributed codes tend to favor texture. Our code is host at the github repository: \url{https://github.com/Crazy-Jack/nips2023_shape_vs_texture}
Does resistance to Style-Transfer equal Shape Bias? Evaluating Shape Bias by Distorted Shape
Oct 11, 2023Deep learning models are known to exhibit a strong texture bias, while human tends to rely heavily on global shape for object recognition. The current benchmark for evaluating a model's shape bias is a set of style-transferred images with the assumption that resistance to the attack of style transfer is related to the development of shape sensitivity in the model. In this work, we show that networks trained with style-transfer images indeed learn to ignore style, but its shape bias arises primarily from local shapes. We provide a Distorted Shape Testbench (DiST) as an alternative measurement of global shape sensitivity. Our test includes 2400 original images from ImageNet-1K, each of which is accompanied by two images with the global shapes of the original image distorted while preserving its texture via the texture synthesis program. We found that (1) models that performed well on the previous shape bias evaluation do not fare well in the proposed DiST; (2) the widely adopted ViT models do not show significant advantages over Convolutional Neural Networks (CNNs) on this benchmark despite that ViTs rank higher on the previous shape bias tests. (3) training with DiST images bridges the significant gap between human and existing SOTA models' performance while preserving the models' accuracy on standard image classification tasks; training with DiST images and style-transferred images are complementary, and can be combined to train network together to enhance both the global and local shape sensitivity of the network. Our code will be host at: https://github.com/leelabcnbc/DiST
Learning Weakly-Supervised Contrastive Representations
Feb 18, 2022
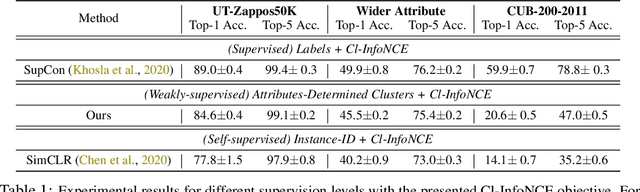

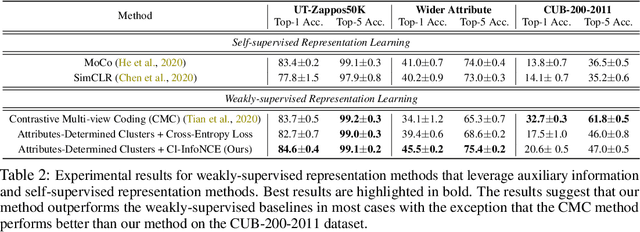
We argue that a form of the valuable information provided by the auxiliary information is its implied data clustering information. For instance, considering hashtags as auxiliary information, we can hypothesize that an Instagram image will be semantically more similar with the same hashtags. With this intuition, we present a two-stage weakly-supervised contrastive learning approach. The first stage is to cluster data according to its auxiliary information. The second stage is to learn similar representations within the same cluster and dissimilar representations for data from different clusters. Our empirical experiments suggest the following three contributions. First, compared to conventional self-supervised representations, the auxiliary-information-infused representations bring the performance closer to the supervised representations, which use direct downstream labels as supervision signals. Second, our approach performs the best in most cases, when comparing our approach with other baseline representation learning methods that also leverage auxiliary data information. Third, we show that our approach also works well with unsupervised constructed clusters (e.g., no auxiliary information), resulting in a strong unsupervised representation learning approach.
Conditional Contrastive Learning with Kernel
Feb 14, 2022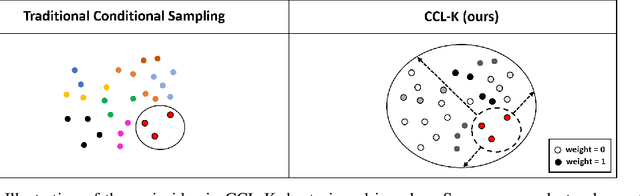



Conditional contrastive learning frameworks consider the conditional sampling procedure that constructs positive or negative data pairs conditioned on specific variables. Fair contrastive learning constructs negative pairs, for example, from the same gender (conditioning on sensitive information), which in turn reduces undesirable information from the learned representations; weakly supervised contrastive learning constructs positive pairs with similar annotative attributes (conditioning on auxiliary information), which in turn are incorporated into the representations. Although conditional contrastive learning enables many applications, the conditional sampling procedure can be challenging if we cannot obtain sufficient data pairs for some values of the conditioning variable. This paper presents Conditional Contrastive Learning with Kernel (CCL-K) that converts existing conditional contrastive objectives into alternative forms that mitigate the insufficient data problem. Instead of sampling data according to the value of the conditioning variable, CCL-K uses the Kernel Conditional Embedding Operator that samples data from all available data and assigns weights to each sampled data given the kernel similarity between the values of the conditioning variable. We conduct experiments using weakly supervised, fair, and hard negatives contrastive learning, showing CCL-K outperforms state-of-the-art baselines.
SurfGen: Adversarial 3D Shape Synthesis with Explicit Surface Discriminators
Jan 01, 2022
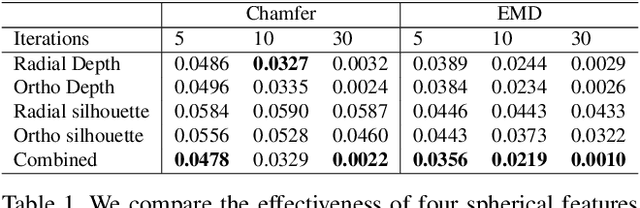

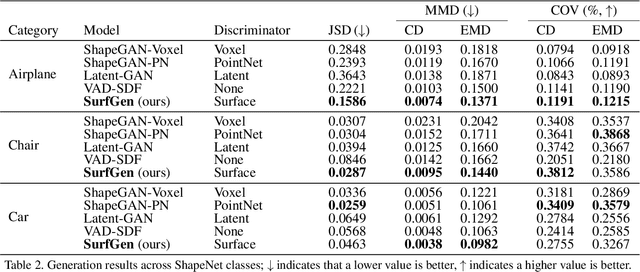
Recent advances in deep generative models have led to immense progress in 3D shape synthesis. While existing models are able to synthesize shapes represented as voxels, point-clouds, or implicit functions, these methods only indirectly enforce the plausibility of the final 3D shape surface. Here we present a 3D shape synthesis framework (SurfGen) that directly applies adversarial training to the object surface. Our approach uses a differentiable spherical projection layer to capture and represent the explicit zero isosurface of an implicit 3D generator as functions defined on the unit sphere. By processing the spherical representation of 3D object surfaces with a spherical CNN in an adversarial setting, our generator can better learn the statistics of natural shape surfaces. We evaluate our model on large-scale shape datasets, and demonstrate that the end-to-end trained model is capable of generating high fidelity 3D shapes with diverse topology.
Integrating Auxiliary Information in Self-supervised Learning
Jun 05, 2021
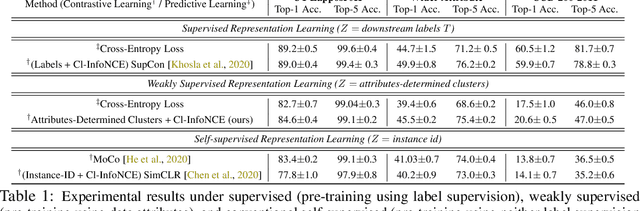
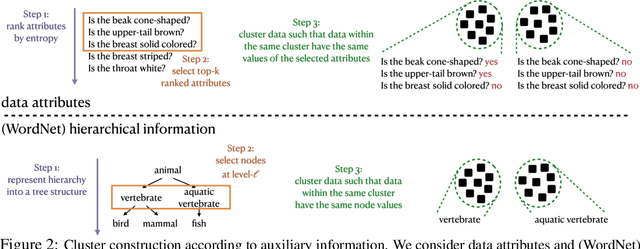
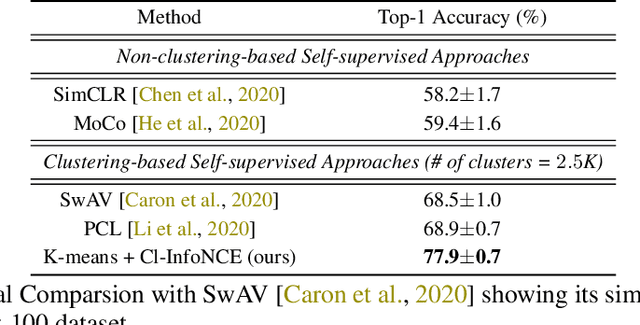
This paper presents to integrate the auxiliary information (e.g., additional attributes for data such as the hashtags for Instagram images) in the self-supervised learning process. We first observe that the auxiliary information may bring us useful information about data structures: for instance, the Instagram images with the same hashtags can be semantically similar. Hence, to leverage the structural information from the auxiliary information, we present to construct data clusters according to the auxiliary information. Then, we introduce the Clustering InfoNCE (Cl-InfoNCE) objective that learns similar representations for augmented variants of data from the same cluster and dissimilar representations for data from different clusters. Our approach contributes as follows: 1) Comparing to conventional self-supervised representations, the auxiliary-information-infused self-supervised representations bring the performance closer to the supervised representations; 2) The presented Cl-InfoNCE can also work with unsupervised constructed clusters (e.g., k-means clusters) and outperform strong clustering-based self-supervised learning approaches, such as the Prototypical Contrastive Learning (PCL) method; 3) We show that Cl-InfoNCE may be a better approach to leverage the data clustering information, by comparing it to the baseline approach - learning to predict the clustering assignments with cross-entropy loss. For analysis, we connect the goodness of the learned representations with the statistical relationships: i) the mutual information between the labels and the clusters and ii) the conditional entropy of the clusters given the labels.