 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Modern System Recipe for Situated Embodied Human-Robot Conversation with Real-Time Multimodal LLMs and Tool-Calling
Feb 04, 2026Situated embodied conversation requires robots to interleave real-time dialogue with active perception: deciding what to look at, when to look, and what to say under tight latency constraints. We present a simple, minimal system recipe that pairs a real-time multimodal language model with a small set of tool interfaces for attention and active perception. We study six home-style scenarios that require frequent attention shifts and increasing perceptual scope. Across four system variants, we evaluate turn-level tool-decision correctness against human annotations and collect subjective ratings of interaction quality. Results indicate that real-time multimodal large language models and tool use for active perception is a promising direction for practical situated embodied conversation.
Social Caption: Evaluating Social Understanding in Multimodal Models
Jan 21, 2026Social understanding abilities are crucial for multimodal large language models (MLLMs) to interpret human social interactions. We introduce Social Caption, a framework grounded in interaction theory to evaluate social understanding abilities of MLLMs along three dimensions: Social Inference (SI), the ability to make accurate inferences about interactions; Holistic Social Analysis (HSA), the ability to generate comprehensive descriptions of interactions; Directed Social Analysis (DSA), the ability to extract relevant social information from interactions. We analyze factors influencing model performance in social understanding, such as scale, architectural design, and spoken context. Experiments with MLLM judges contribute insights about scaling automated evaluation of multimodal social understanding.
Propose, Solve, Verify: Self-Play Through Formal Verification
Dec 20, 2025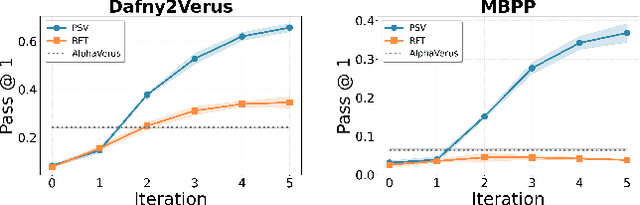
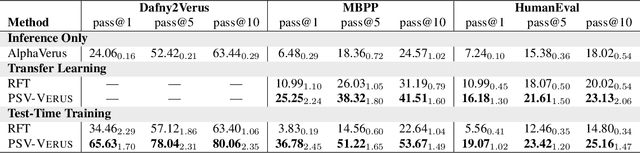
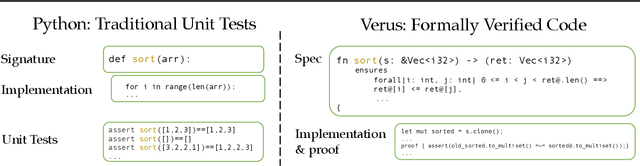

Training models through self-play alone (without any human data) has been a longstanding goal in AI, but its effectiveness for training large language models remains unclear, particularly in code generation where rewards based on unit tests are brittle and prone to error propagation. We study self-play in the verified code generation setting, where formal verification provides reliable correctness signals. We introduce Propose, Solve, Verify (PSV) a simple self-play framework where formal verification signals are used to create a proposer capable of generating challenging synthetic problems and a solver trained via expert iteration. We use PSV to train PSV-Verus, which across three benchmarks improves pass@1 by up to 9.6x over inference-only and expert-iteration baselines. We show that performance scales with the number of generated questions and training iterations, and through ablations identify formal verification and difficulty-aware proposal as essential ingredients for successful self-play.
ONLY: One-Layer Intervention Sufficiently Mitigates Hallucinations in Large Vision-Language Models
Jul 01, 2025Recent Large Vision-Language Models (LVLMs) have introduced a new paradigm for understanding and reasoning about image input through textual responses. Although they have achieved remarkable performance across a range of multi-modal tasks, they face the persistent challenge of hallucination, which introduces practical weaknesses and raises concerns about their reliable deployment in real-world applications. Existing work has explored contrastive decoding approaches to mitigate this issue, where the output of the original LVLM is compared and contrasted with that of a perturbed version. However, these methods require two or more queries that slow down LVLM response generation, making them less suitable for real-time applications. To overcome this limitation, we propose ONLY, a training-free decoding approach that requires only a single query and a one-layer intervention during decoding, enabling efficient real-time deployment. Specifically, we enhance textual outputs by selectively amplifying crucial textual information using a text-to-visual entropy ratio for each token. Extensive experimental results demonstrate that our proposed ONLY consistently outperforms state-of-the-art methods across various benchmarks while requiring minimal implementation effort and computational cost. Code is available at https://github.com/zifuwan/ONLY.
From Reproduction to Replication: Evaluating Research Agents with Progressive Code Masking
Jun 24, 2025Recent progress in autonomous code generation has fueled excitement around AI agents capable of accelerating scientific discovery by running experiments. However, there is currently no benchmark that evaluates whether such agents can implement scientific ideas when given varied amounts of code as a starting point, interpolating between reproduction (running code) and from-scratch replication (fully re-implementing and running code). We introduce AutoExperiment, a benchmark that evaluates AI agents' ability to implement and run machine learning experiments based on natural language descriptions in research papers. In each task, agents are given a research paper, a codebase with key functions masked out, and a command to run the experiment. The goal is to generate the missing code, execute the experiment in a sandboxed environment, and reproduce the results. AutoExperiment scales in difficulty by varying the number of missing functions $n$, ranging from partial reproduction to full replication. We evaluate state-of-the-art agents and find that performance degrades rapidly as $n$ increases. Agents that can dynamically interact with the environment (e.g. to debug their code) can outperform agents in fixed "agentless" harnesses, and there exists a significant gap between single-shot and multi-trial success rates (Pass@1 vs. Pass@5), motivating verifier approaches to our benchmark. Our findings highlight critical challenges in long-horizon code generation, context retrieval, and autonomous experiment execution, establishing AutoExperiment as a new benchmark for evaluating progress in AI-driven scientific experimentation. Our data and code are open-sourced at https://github.com/j1mk1m/AutoExperiment .
Aligning Dialogue Agents with Global Feedback via Large Language Model Reward Decomposition
May 21, 2025We propose a large language model based reward decomposition framework for aligning dialogue agents using only a single session-level feedback signal. We leverage the reasoning capabilities of a frozen, pretrained large language model (LLM) to infer fine-grained local implicit rewards by decomposing global, session-level feedback. Our first text-only variant prompts the LLM to perform reward decomposition using only the dialogue transcript. The second multimodal variant incorporates additional behavioral cues, such as pitch, gaze, and facial affect, expressed as natural language descriptions. These inferred turn-level rewards are distilled into a lightweight reward model, which we utilize for RL-based fine-tuning for dialogue generation. We evaluate both text-only and multimodal variants against state-of-the-art reward decomposition methods and demonstrate notable improvements in human evaluations of conversation quality, suggesting that LLMs are strong reward decomposers that obviate the need for manual reward shaping and granular human feedback.
Social Genome: Grounded Social Reasoning Abilities of Multimodal Models
Feb 21, 2025Social reasoning abilities are crucial for AI systems to effectively interpret and respond to multimodal human communication and interaction within social contexts. We introduce Social Genome, the first benchmark for fine-grained, grounded social reasoning abilities of multimodal models. Social Genome contains 272 videos of interactions and 1,486 human-annotated reasoning traces related to inferences about these interactions. These traces contain 5,777 reasoning steps that reference evidence from visual cues, verbal cues, vocal cues, and external knowledge (contextual knowledge external to videos). Social Genome is also the first modeling challenge to study external knowledge in social reasoning. Social Genome computes metrics to holistically evaluate semantic and structural qualities of model-generated social reasoning traces. We demonstrate the utility of Social Genome through experiments with state-of-the-art models, identifying performance gaps and opportunities for future research to improve the grounded social reasoning abilities of multimodal models.
AV-Flow: Transforming Text to Audio-Visual Human-like Interactions
Feb 18, 2025We introduce AV-Flow, an audio-visual generative model that animates photo-realistic 4D talking avatars given only text input. In contrast to prior work that assumes an existing speech signal, we synthesize speech and vision jointly. We demonstrate human-like speech synthesis, synchronized lip motion, lively facial expressions and head pose; all generated from just text characters. The core premise of our approach lies in the architecture of our two parallel diffusion transformers. Intermediate highway connections ensure communication between the audio and visual modalities, and thus, synchronized speech intonation and facial dynamics (e.g., eyebrow motion). Our model is trained with flow matching, leading to expressive results and fast inference. In case of dyadic conversations, AV-Flow produces an always-on avatar, that actively listens and reacts to the audio-visual input of a user. Through extensive experiments, we show that our method outperforms prior work, synthesizing natural-looking 4D talking avatars. Project page: https://aggelinacha.github.io/AV-Flow/
Self-Correcting Decoding with Generative Feedback for Mitigating Hallucinations in Large Vision-Language Models
Feb 10, 2025While recent Large Vision-Language Models (LVLMs) have shown remarkable performance in multi-modal tasks, they are prone to generating hallucinatory text responses that do not align with the given visual input, which restricts their practical applicability in real-world scenarios. In this work, inspired by the observation that the text-to-image generation process is the inverse of image-conditioned response generation in LVLMs, we explore the potential of leveraging text-to-image generative models to assist in mitigating hallucinations in LVLMs. We discover that generative models can offer valuable self-feedback for mitigating hallucinations at both the response and token levels. Building on this insight, we introduce self-correcting Decoding with Generative Feedback (DeGF), a novel training-free algorithm that incorporates feedback from text-to-image generative models into the decoding process to effectively mitigate hallucinations in LVLMs. Specifically, DeGF generates an image from the initial response produced by LVLMs, which acts as an auxiliary visual reference and provides self-feedback to verify and correct the initial response through complementary or contrastive decoding. Extensive experimental results validate the effectiveness of our approach in mitigating diverse types of hallucinations, consistently surpassing state-of-the-art methods across six benchmarks. Code is available at https://github.com/zhangce01/DeGF.
LlaMADRS: Prompting Large Language Models for Interview-Based Depression Assessment
Jan 07, 2025This study introduces LlaMADRS, a novel framework leveraging open-source Large Language Models (LLMs) to automate depression severity assessment using the Montgomery-Asberg Depression Rating Scale (MADRS). We employ a zero-shot prompting strategy with carefully designed cues to guide the model in interpreting and scoring transcribed clinical interviews. Our approach, tested on 236 real-world interviews from the Context-Adaptive Multimodal Informatics (CAMI) dataset, demonstrates strong correlations with clinician assessments. The Qwen 2.5--72b model achieves near-human level agreement across most MADRS items, with Intraclass Correlation Coefficients (ICC) closely approaching those between human raters. We provide a comprehensive analysis of model performance across different MADRS items, highlighting strengths and current limitations. Our findings suggest that LLMs, with appropriate prompting, can serve as efficient tools for mental health assessment, potentially increasing accessibility in resource-limited settings. However, challenges remain, particularly in assessing symptoms that rely on non-verbal cues, underscoring the need for multimodal approaches in future work.