 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Conversational Behavior Reasoning Capabilities in Full-Duplex Speech
Dec 25, 2025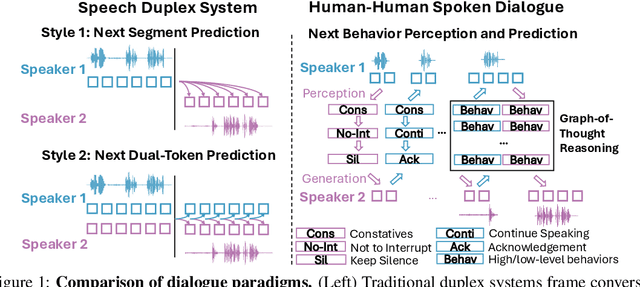

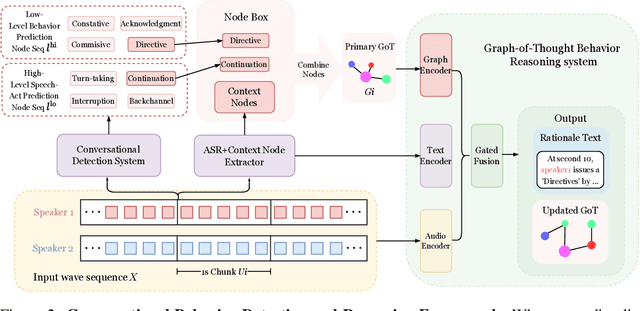

Human conversation is organized by an implicit chain of thoughts that manifests as timed speech acts. Capturing this causal pathway is key to building natural full-duplex interactive systems. We introduce a framework that enables reasoning over conversational behaviors by modeling this process as causal inference within a Graph-of-Thoughts (GoT). Our approach formalizes the intent-to-action pathway with a hierarchical labeling scheme, predicting high-level communicative intents and low-level speech acts to learn their causal and temporal dependencies. To train this system, we develop a hybrid corpus that pairs controllable, event-rich simulations with human-annotated rationales and real conversational speech. The GoT framework structures streaming predictions as an evolving graph, enabling a multimodal transformer to forecast the next speech act, generate concise justifications for its decisions, and dynamically refine its reasoning. Experiments on both synthetic and real duplex dialogues show that the framework delivers robust behavior detection, produces interpretable reasoning chains, and establishes a foundation for benchmarking conversational reasoning in full duplex spoken dialogue systems.
ONLY: One-Layer Intervention Sufficiently Mitigates Hallucinations in Large Vision-Language Models
Jul 01, 2025Recent Large Vision-Language Models (LVLMs) have introduced a new paradigm for understanding and reasoning about image input through textual responses. Although they have achieved remarkable performance across a range of multi-modal tasks, they face the persistent challenge of hallucination, which introduces practical weaknesses and raises concerns about their reliable deployment in real-world applications. Existing work has explored contrastive decoding approaches to mitigate this issue, where the output of the original LVLM is compared and contrasted with that of a perturbed version. However, these methods require two or more queries that slow down LVLM response generation, making them less suitable for real-time applications. To overcome this limitation, we propose ONLY, a training-free decoding approach that requires only a single query and a one-layer intervention during decoding, enabling efficient real-time deployment. Specifically, we enhance textual outputs by selectively amplifying crucial textual information using a text-to-visual entropy ratio for each token. Extensive experimental results demonstrate that our proposed ONLY consistently outperforms state-of-the-art methods across various benchmarks while requiring minimal implementation effort and computational cost. Code is available at https://github.com/zifuwan/ONLY.
Self-Correcting Decoding with Generative Feedback for Mitigating Hallucinations in Large Vision-Language Models
Feb 10, 2025While recent Large Vision-Language Models (LVLMs) have shown remarkable performance in multi-modal tasks, they are prone to generating hallucinatory text responses that do not align with the given visual input, which restricts their practical applicability in real-world scenarios. In this work, inspired by the observation that the text-to-image generation process is the inverse of image-conditioned response generation in LVLMs, we explore the potential of leveraging text-to-image generative models to assist in mitigating hallucinations in LVLMs. We discover that generative models can offer valuable self-feedback for mitigating hallucinations at both the response and token levels. Building on this insight, we introduce self-correcting Decoding with Generative Feedback (DeGF), a novel training-free algorithm that incorporates feedback from text-to-image generative models into the decoding process to effectively mitigate hallucinations in LVLMs. Specifically, DeGF generates an image from the initial response produced by LVLMs, which acts as an auxiliary visual reference and provides self-feedback to verify and correct the initial response through complementary or contrastive decoding. Extensive experimental results validate the effectiveness of our approach in mitigating diverse types of hallucinations, consistently surpassing state-of-the-art methods across six benchmarks. Code is available at https://github.com/zhangce01/DeGF.
Understanding Masked Autoencoders via Hierarchical Latent Variable Models
Jun 08, 2023Masked autoencoder (MAE), a simple and effective self-supervised learning framework based on the reconstruction of masked image regions, has recently achieved prominent success in a variety of vision tasks. Despite the emergence of intriguing empirical observations on MAE, a theoretically principled understanding is still lacking. In this work, we formally characterize and justify existing empirical insights and provide theoretical guarantees of MAE. We formulate the underlying data-generating process as a hierarchical latent variable model and show that under reasonable assumptions, MAE provably identifies a set of latent variables in the hierarchical model, explaining why MAE can extract high-level information from pixels. Further, we show how key hyperparameters in MAE (the masking ratio and the patch size) determine which true latent variables to be recovered, therefore influencing the level of semantic information in the representation. Specifically, extremely large or small masking ratios inevitably lead to low-level representations. Our theory offers coherent explanations of existing empirical observations and provides insights for potential empirical improvements and fundamental limitations of the masking-reconstruction paradigm. We conduct extensive experiments to validate our theoretical insights.
Conditional Contrastive Learning with Kernel
Feb 14, 2022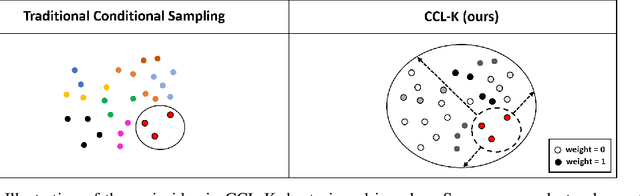



Conditional contrastive learning frameworks consider the conditional sampling procedure that constructs positive or negative data pairs conditioned on specific variables. Fair contrastive learning constructs negative pairs, for example, from the same gender (conditioning on sensitive information), which in turn reduces undesirable information from the learned representations; weakly supervised contrastive learning constructs positive pairs with similar annotative attributes (conditioning on auxiliary information), which in turn are incorporated into the representations. Although conditional contrastive learning enables many applications, the conditional sampling procedure can be challenging if we cannot obtain sufficient data pairs for some values of the conditioning variable. This paper presents Conditional Contrastive Learning with Kernel (CCL-K) that converts existing conditional contrastive objectives into alternative forms that mitigate the insufficient data problem. Instead of sampling data according to the value of the conditioning variable, CCL-K uses the Kernel Conditional Embedding Operator that samples data from all available data and assigns weights to each sampled data given the kernel similarity between the values of the conditioning variable. We conduct experiments using weakly supervised, fair, and hard negatives contrastive learning, showing CCL-K outperforms state-of-the-art baselines.
Conditional Contrastive Learning: Removing Undesirable Information in Self-Supervised Representations
Jun 05, 2021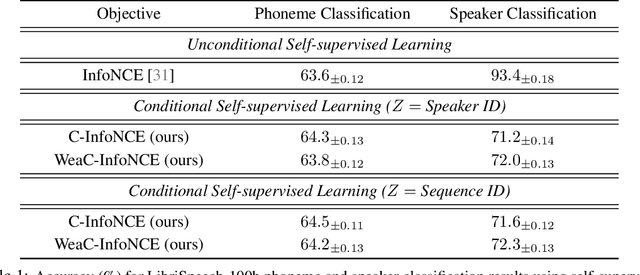
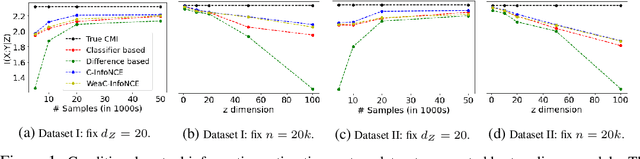
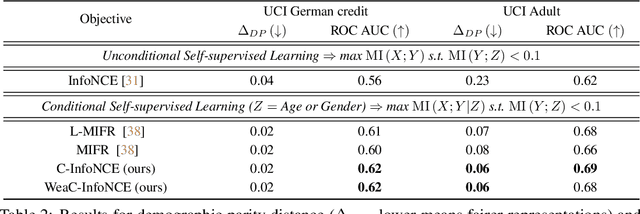

Self-supervised learning is a form of unsupervised learning that leverages rich information in data to learn representations. However, data sometimes contains certain information that may be undesirable for downstream tasks. For instance, gender information may lead to biased decisions on many gender-irrelevant tasks. In this paper, we develop conditional contrastive learning to remove undesirable information in self-supervised representations. To remove the effect of the undesirable variable, our proposed approach conditions on the undesirable variable (i.e., by fixing the variations of it) during the contrastive learning process. In particular, inspired by the contrastive objective InfoNCE, we introduce Conditional InfoNCE (C-InfoNCE), and its computationally efficient variant, Weak-Conditional InfoNCE (WeaC-InfoNCE), for conditional contrastive learning. We demonstrate empirically that our methods can successfully learn self-supervised representations for downstream tasks while removing a great level of information related to the undesirable variables. We study three scenarios, each with a different type of undesirable variables: task-irrelevant meta-information for self-supervised speech representation learning, sensitive attributes for fair representation learning, and domain specification for multi-domain visual representation learning.
A Large-scale Study on Unsupervised Outlier Model Selection: Do Internal Strategies Suffice?
Apr 12, 2021
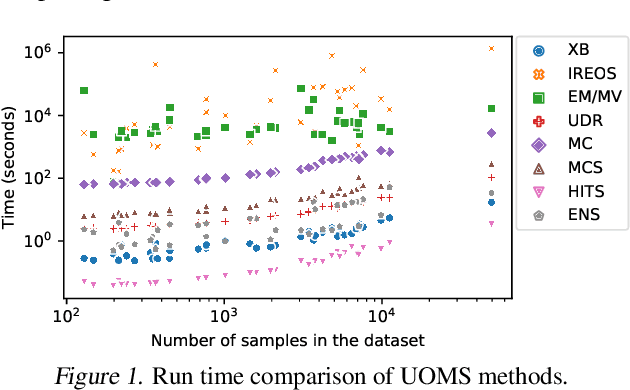
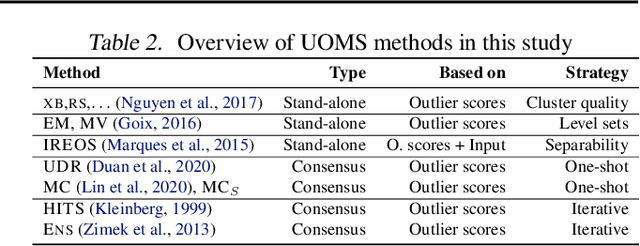
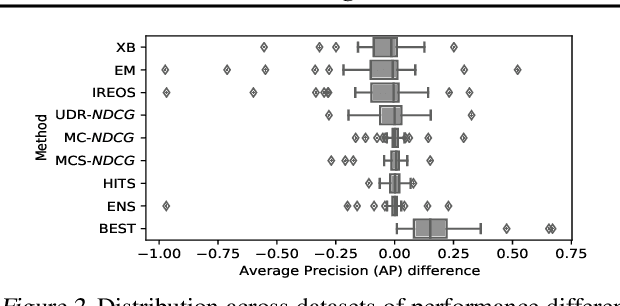
Given an unsupervised outlier detection task, how should one select a detection algorithm as well as its hyperparameters (jointly called a model)? Unsupervised model selection is notoriously difficult, in the absence of hold-out validation data with ground-truth labels. Therefore, the problem is vastly understudied. In this work, we study the feasibility of employing internal model evaluation strategies for selecting a model for outlier detection. These so-called internal strategies solely rely on the input data (without labels) and the output (outlier scores) of the candidate models. We setup (and open-source) a large testbed with 39 detection tasks and 297 candidate models comprised of 8 detectors and various hyperparameter configurations. We evaluate 7 different strategies on their ability to discriminate between models w.r.t. detection performance, without using any labels. Our study reveals room for progress -- we find that none would be practically useful, as they select models only comparable to a state-of-the-art detector (with random configuration).
Self-supervised Representation Learning with Relative Predictive Coding
Apr 12, 2021
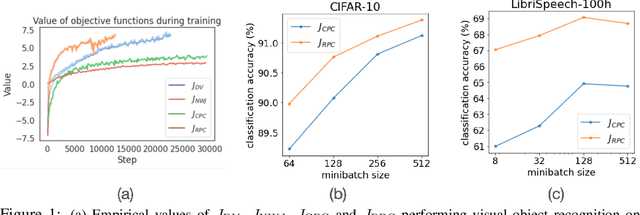
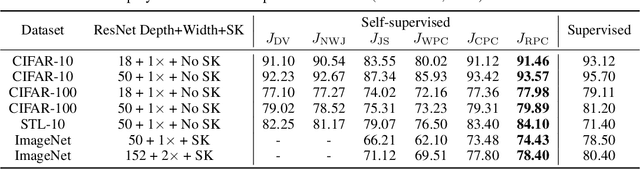
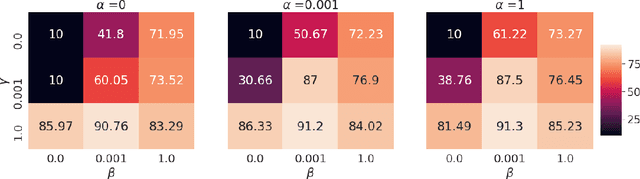
This paper introduces Relative Predictive Coding (RPC), a new contrastive representation learning objective that maintains a good balance among training stability, minibatch size sensitivity, and downstream task performance. The key to the success of RPC is two-fold. First, RPC introduces the relative parameters to regularize the objective for boundedness and low variance. Second, RPC contains no logarithm and exponential score functions, which are the main cause of training instability in prior contrastive objectives. We empirically verify the effectiveness of RPC on benchmark vision and speech self-supervised learning tasks. Lastly, we relate RPC with mutual information (MI) estimation, showing RPC can be used to estimate MI with low variance.
Interpretable Multimodal Routing for Human Multimodal Language
Apr 29, 2020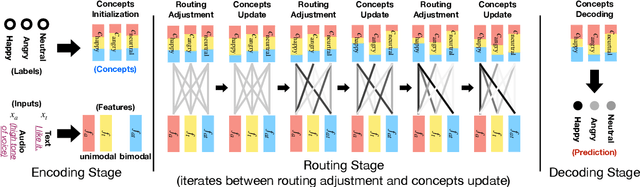
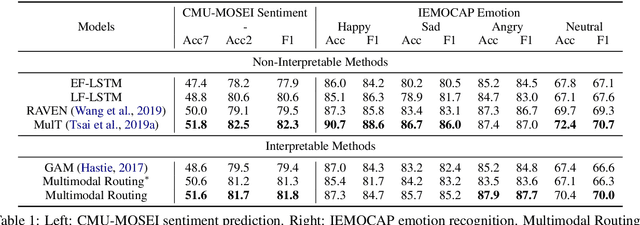
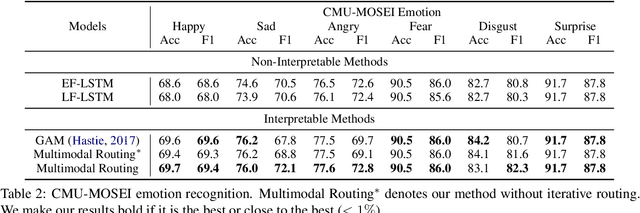

The human language has heterogeneous sources of information, including tones of voice, facial gestures, and spoken language. Recent advances introduced computational models to combine these multimodal sources and yielded strong performance on human-centric tasks. Nevertheless, most of the models are often black-box, which comes with the price of lacking interpretability. In this paper, we propose Multimodal Routing to separate the contributions to the prediction from each modality and the interactions between modalities. At the heart of our method is a routing mechanism that represents each prediction as a concept, i.e., a vector in a Euclidean space. The concept assumes a linear aggregation from the contributions of multimodal features. Then, the routing procedure iteratively 1) associates a feature and a concept by checking how this concept agrees with this feature and 2) updates the concept based on the associations. In our experiments, we provide both global and local interpretation using Multimodal Routing on sentiment analysis and emotion prediction, without loss of performance compared to state-of-the-art methods. For example, we observe that our model relies mostly on the text modality for neutral sentiment predictions, the acoustic modality for extremely negative predictions, and the text-acoustic bimodal interaction for extremely positive predictions.
Complex Transformer: A Framework for Modeling Complex-Valued Sequence
Oct 22, 2019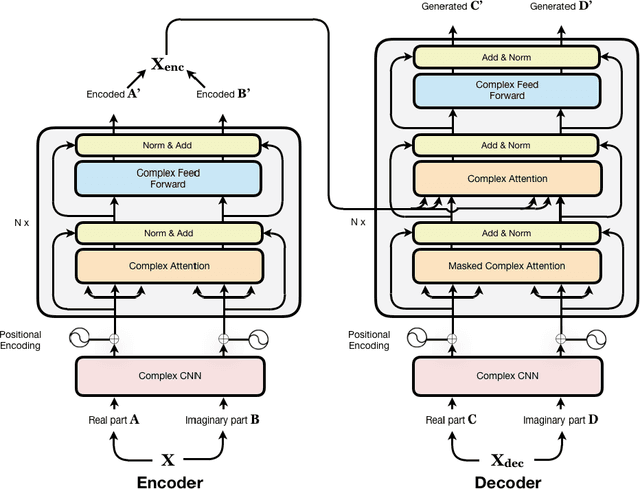
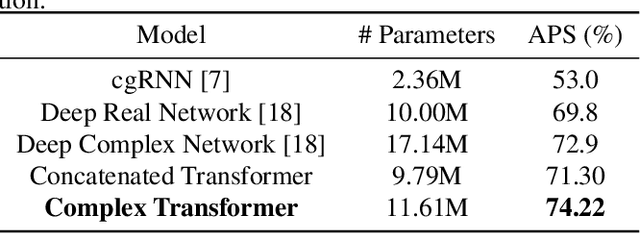
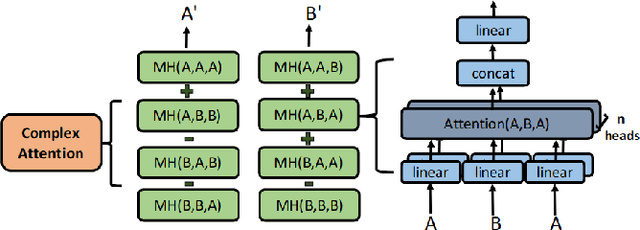

While deep learning has received a surge of interest in a variety of fields in recent years, major deep learning models barely use complex numbers. However, speech, signal and audio data are naturally complex-valued after Fourier Transform, and studies have shown a potentially richer representation of complex nets. In this paper, we propose a Complex Transformer, which incorporates the transformer model as a backbone for sequence modeling; we also develop attention and encoder-decoder network operating for complex input. The model achieves state-of-the-art performance on the MusicNet dataset and an In-phase Quadrature (IQ) signal dataset.