 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-scale Study on Unsupervised Outlier Model Selection: Do Internal Strategies Suffice?
Paper and Code

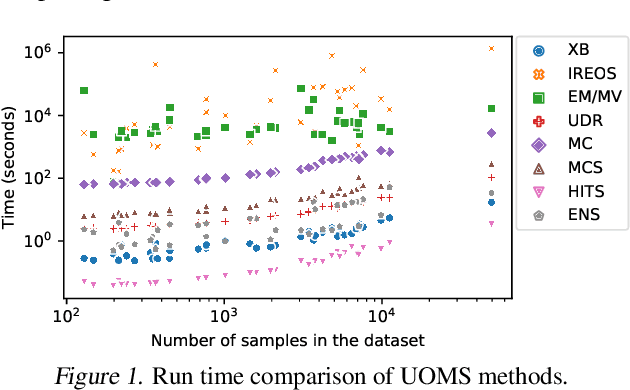
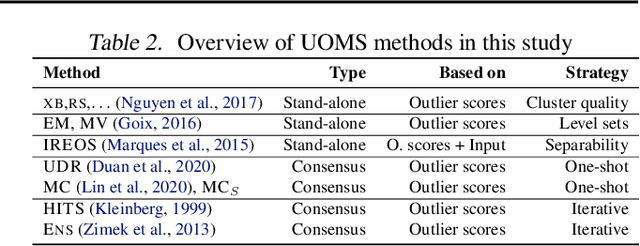
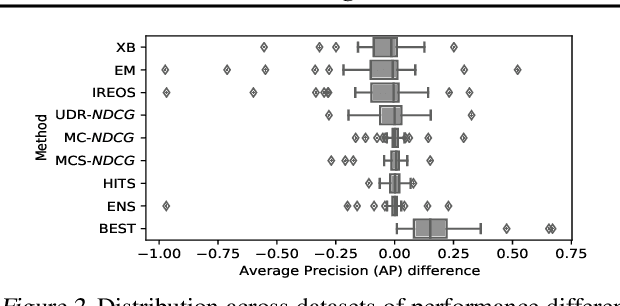
Given an unsupervised outlier detection task, how should one select a detection algorithm as well as its hyperparameters (jointly called a model)? Unsupervised model selection is notoriously difficult, in the absence of hold-out validation data with ground-truth labels. Therefore, the problem is vastly understudied. In this work, we study the feasibility of employing internal model evaluation strategies for selecting a model for outlier detection. These so-called internal strategies solely rely on the input data (without labels) and the output (outlier scores) of the candidate models. We setup (and open-source) a large testbed with 39 detection tasks and 297 candidate models comprised of 8 detectors and various hyperparameter configurations. We evaluate 7 different strategies on their ability to discriminate between models w.r.t. detection performance, without using any labels. Our study reveals room for progress -- we find that none would be practically useful, as they select models only comparable to a state-of-the-art detector (with random configuration).