 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Diffusion to Mutually Enhance Polarized Light and Low Resolution EBSD Data
Apr 24, 2026In spite of the utility of 3-D electron back-scattered diffraction (EBSD) microscopy, the data collection process can be time-consuming with serial-sectioning. Hence, it is natural to look at other modalities, such as polarized light (PL) data, to accelerate EBSD data collection, supplemented with shared information. Complementarily, features in chaotic PL data could even be enriched with a handful of EBSD measurements. To inherently learn the complex dynamics between EBSD and PL to solve these inverse problems, we use an unconditional multimodal diffusion model, motivated by progress in diffusion models for inverse problems. Although trained solely on synthetic data once, our model has strong generalizable capabilities on real data which can be low-resolution, noisy, corrupted, and misregistered. With inference-time scaling, we show gains in performance on a variety of objectives including grain boundary prediction, super-resolution, and denoising. With our model, we demonstrate that there is little difference from full resolution performance with only 25% (1/4 the resolution) of EBSD data and corrupted PL data.
Feynman: Knowledge-Infused Diagramming Agent for Scalable Visual Designs
Mar 13, 2026Visual design is an essential application of state-of-the-art multi-modal AI systems. Improving these systems requires high-quality vision-language data at scale. Despite the abundance of internet image and text data, knowledge-rich and well-aligned image-text pairs are rare. In this paper, we present a scalable diagram generation pipeline built with our agent, Feynman. To create diagrams, Feynman first enumerates domain-specific knowledge components (''ideas'') and performs code planning based on the ideas. Given the plan, Feynman translates ideas into simple declarative programs and iterates to receives feedback and visually refine diagrams. Finally, the declarative programs are rendered by the Penrose diagramming system. The optimization-based rendering of Penrose preserves the visual semantics while injecting fresh randomness into the layout, thereby producing diagrams with visual consistency and diversity. As a result, Feynman can author diagrams along with grounded captions with very little cost and time. Using Feynman, we synthesized a dataset with more than 100k well-aligned diagram-caption pairs. We also curate a visual-language benchmark, Diagramma, from freshly generated data. Diagramma can be used for evaluating the visual reasoning capabilities of vision-language models. We plan to release the dataset, benchmark, and the full agent pipeline as an open-source project.
On the Learning Dynamics of RLVR at the Edge of Competence
Feb 16, 2026Reinforcement learning with verifiable rewards (RLVR) has been a main driver of recent breakthroughs in large reasoning models. Yet it remains a mystery how rewards based solely on final outcomes can help overcome the long-horizon barrier to extended reasoning. To understand this, we develop a theory of the training dynamics of RL for transformers on compositional reasoning tasks. Our theory characterizes how the effectiveness of RLVR is governed by the smoothness of the difficulty spectrum. When data contains abrupt discontinuities in difficulty, learning undergoes grokking-type phase transitions, producing prolonged plateaus before progress recurs. In contrast, a smooth difficulty spectrum leads to a relay effect: persistent gradient signals on easier problems elevate the model's capabilities to the point where harder ones become tractable, resulting in steady and continuous improvement. Our theory explains how RLVR can improve performance at the edge of competence, and suggests that appropriately designed data mixtures can yield scalable gains. As a technical contribution, our analysis develops and adapts tools from Fourier analysis on finite groups to our setting. We validate the predicted mechanisms empirically via synthetic experiments.
Sample Complexity of Average-Reward Q-Learning: From Single-agent to Federated Reinforcement Learning
Jan 20, 2026Average-reward reinforcement learning offers a principled framework for long-term decision-making by maximizing the mean reward per time step. Although Q-learning is a widely used model-free algorithm with established sample complexity in discounted and finite-horizon Markov decision processes (MDPs), its theoretical guarantees for average-reward settings remain limited. This work studies a simple but effective Q-learning algorithm for average-reward MDPs with finite state and action spaces under the weakly communicating assumption, covering both single-agent and federated scenarios. For the single-agent case, we show that Q-learning with carefully chosen parameters achieves sample complexity $\widetilde{O}\left(\frac{|\mathcal{S}||\mathcal{A}|\|h^{\star}\|_{\mathsf{sp}}^3}{\varepsilon^3}\right)$, where $\|h^{\star}\|_{\mathsf{sp}}$ is the span norm of the bias function, improving previous results by at least a factor of $\frac{\|h^{\star}\|_{\mathsf{sp}}^2}{\varepsilon^2}$. In the federated setting with $M$ agents, we prove that collaboration reduces the per-agent sample complexity to $\widetilde{O}\left(\frac{|\mathcal{S}||\mathcal{A}|\|h^{\star}\|_{\mathsf{sp}}^3}{M\varepsilon^3}\right)$, with only $\widetilde{O}\left(\frac{\|h^{\star}\|_{\mathsf{sp}}}{\varepsilon}\right)$ communication rounds required. These results establish the first federated Q-learning algorithm for average-reward MDPs, with provable efficiency in both sample and communication complexity.
Preconditioning Benefits of Spectral Orthogonalization in Muon
Jan 20, 2026The Muon optimizer, a matrix-structured algorithm that leverages spectral orthogonalization of gradients, is a milestone in the pretraining of large language models. However, the underlying mechanisms of Muon -- particularly the role of gradient orthogonalization -- remain poorly understood, with very few works providing end-to-end analyses that rigorously explain its advantages in concrete applications. We take a step by studying the effectiveness of a simplified variant of Muon through two case studies: matrix factorization, and in-context learning of linear transformers. For both problems, we prove that simplified Muon converges linearly with iteration complexities independent of the relevant condition number, provably outperforming gradient descent and Adam. Our analysis reveals that the Muon dynamics decouple into a collection of independent scalar sequences in the spectral domain, each exhibiting similar convergence behavior. Our theory formalizes the preconditioning effect induced by spectral orthogonalization, offering insight into Muon's effectiveness in these matrix optimization problems and potentially beyond.
Polynomial Convergence of Riemannian Diffusion Models
Jan 05, 2026Diffusion models have demonstrated remarkable empirical success in the recent years and are considered one of the state-of-the-art generative models in modern AI. These models consist of a forward process, which gradually diffuses the data distribution to a noise distribution spanning the whole space, and a backward process, which inverts this transformation to recover the data distribution from noise. Most of the existing literature assumes that the underlying space is Euclidean. However, in many practical applications, the data are constrained to lie on a submanifold of Euclidean space. Addressing this setting, De Bortoli et al. (2022) introduced Riemannian diffusion models and proved that using an exponentially small step size yields a small sampling error in the Wasserstein distance, provided the data distribution is smooth and strictly positive, and the score estimate is $L_\infty$-accurate. In this paper, we greatly strengthen this theory by establishing that, under $L_2$-accurate score estimate, a {\em polynomially small stepsize} suffices to guarantee small sampling error in the total variation distance, without requiring smoothness or positivity of the data distribution. Our analysis only requires mild and standard curvature assumptions on the underlying manifold. The main ingredients in our analysis are Li-Yau estimate for the log-gradient of heat kernel, and Minakshisundaram-Pleijel parametrix expansion of the perturbed heat equation. Our approach opens the door to a sharper analysis of diffusion models on non-Euclidean spaces.
Transformers Provably Learn Chain-of-Thought Reasoning with Length Generalization
Nov 10, 2025The ability to reason lies at the core of artificial intelligence (AI), and challenging problems usually call for deeper and longer reasoning to tackle. A crucial question about AI reasoning is whether models can extrapolate learned reasoning patterns to solve harder tasks with longer chain-of-thought (CoT). In this work, we present a theoretical analysis of transformers learning on synthetic state-tracking tasks with gradient descent. We mathematically prove how the algebraic structure of state-tracking problems governs the degree of extrapolation of the learned CoT. Specifically, our theory characterizes the length generalization of transformers through the mechanism of attention concentration, linking the retrieval robustness of the attention layer to the state-tracking task structure of long-context reasoning. Moreover, for transformers with limited reasoning length, we prove that a recursive self-training scheme can progressively extend the range of solvable problem lengths. To our knowledge, we provide the first optimization guarantee that constant-depth transformers provably learn $\mathsf{NC}^1$-complete problems with CoT, significantly going beyond prior art confined in $\mathsf{TC}^0$, unless the widely held conjecture $\mathsf{TC}^0 \neq \mathsf{NC}^1$ fails. Finally, we present a broad set of experiments supporting our theoretical results, confirming the length generalization behaviors and the mechanism of attention concentration.
Multi-head Transformers Provably Learn Symbolic Multi-step Reasoning via Gradient Descent
Aug 11, 2025Transformers have demonstrated remarkable capabilities in multi-step reasoning tasks. However, understandings of the underlying mechanisms by which they acquire these abilities through training remain limited, particularly from a theoretical standpoint. This work investigates how transformers learn to solve symbolic multi-step reasoning problems through chain-of-thought processes, focusing on path-finding in trees. We analyze two intertwined tasks: a backward reasoning task, where the model outputs a path from a goal node to the root, and a more complex forward reasoning task, where the model implements two-stage reasoning by first identifying the goal-to-root path and then reversing it to produce the root-to-goal path. Our theoretical analysis, grounded in the dynamics of gradient descent, shows that trained one-layer transformers can provably solve both tasks with generalization guarantees to unseen trees. In particular, our multi-phase training dynamics for forward reasoning elucidate how different attention heads learn to specialize and coordinate autonomously to solve the two subtasks in a single autoregressive path. These results provide a mechanistic explanation of how trained transformers can implement sequential algorithmic procedures. Moreover, they offer insights into the emergence of reasoning abilities, suggesting that when tasks are structured to take intermediate chain-of-thought steps, even shallow multi-head transformers can effectively solve problems that would otherwise require deeper architectures.
Scalable LLM Math Reasoning Acceleration with Low-rank Distillation
May 08, 2025Due to long generations, large language model (LLM) math reasoning demands significant computational resources and time. While many existing efficient inference methods have been developed with excellent performance preservation on language tasks, they often severely degrade math performance. In this paper, we propose Caprese, a low-cost distillation method to recover lost capabilities from deploying efficient inference methods, focused primarily in feedforward blocks. With original weights unperturbed, roughly 1% of additional parameters, and only 20K synthetic training samples, we are able to recover much if not all of the math capabilities lost from efficient inference for thinking LLMs and without harm to language tasks for instruct LLMs. Moreover, Caprese slashes the number of active parameters (~2B cut for Gemma 2 9B and Llama 3.1 8B) and integrates cleanly into existing model layers to reduce latency (>11% reduction to generate 2048 tokens with Qwen 2.5 14B) while encouraging response brevity.
LoRe: Personalizing LLMs via Low-Rank Reward Modeling
Apr 20, 2025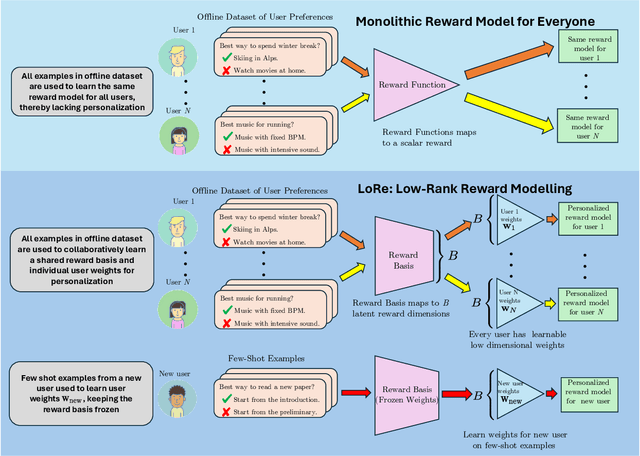
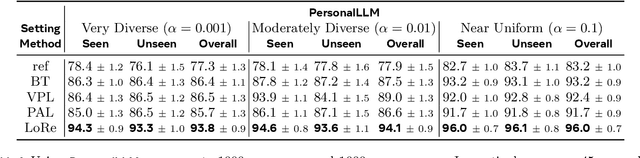
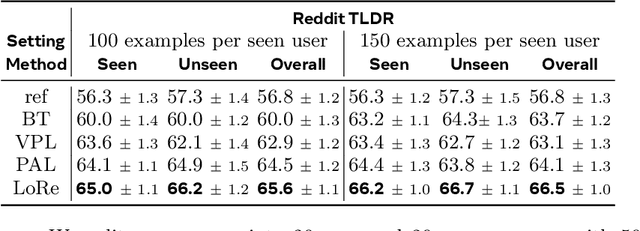
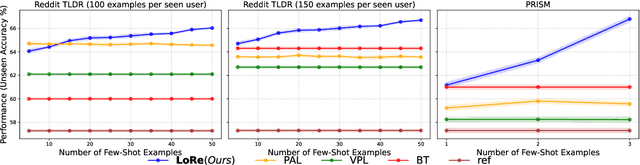
Personalizing large language models (LLMs) to accommodate diverse user preferences is essential for enhancing alignment and user satisfaction. Traditional reinforcement learning from human feedback (RLHF) approaches often rely on monolithic value representations, limiting their ability to adapt to individual preferences. We introduce a novel framework that leverages low-rank preference modeling to efficiently learn and generalize user-specific reward functions. By representing reward functions in a low-dimensional subspace and modeling individual preferences as weighted combinations of shared basis functions, our approach avoids rigid user categorization while enabling scalability and few-shot adaptation. We validate our method on multiple preference datasets, demonstrating superior generalization to unseen users and improved accuracy in preference prediction tasks.