 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEM: Scaling Transformers with Embedding Modules
Jan 15, 2026Fine-grained sparsity promises higher parametric capacity without proportional per-token compute, but often suffers from training instability, load balancing, and communication overhead. We introduce STEM (Scaling Transformers with Embedding Modules), a static, token-indexed approach that replaces the FFN up-projection with a layer-local embedding lookup while keeping the gate and down-projection dense. This removes runtime routing, enables CPU offload with asynchronous prefetch, and decouples capacity from both per-token FLOPs and cross-device communication. Empirically, STEM trains stably despite extreme sparsity. It improves downstream performance over dense baselines while reducing per-token FLOPs and parameter accesses (eliminating roughly one-third of FFN parameters). STEM learns embedding spaces with large angular spread which enhances its knowledge storage capacity. More interestingly, this enhanced knowledge capacity comes with better interpretability. The token-indexed nature of STEM embeddings allows simple ways to perform knowledge editing and knowledge injection in an interpretable manner without any intervention in the input text or additional computation. In addition, STEM strengthens long-context performance: as sequence length grows, more distinct parameters are activated, yielding practical test-time capacity scaling. Across 350M and 1B model scales, STEM delivers up to ~3--4% accuracy improvements overall, with notable gains on knowledge and reasoning-heavy benchmarks (ARC-Challenge, OpenBookQA, GSM8K, MMLU). Overall, STEM is an effective way of scaling parametric memory while providing better interpretability, better training stability and improved efficiency.
Scalable LLM Math Reasoning Acceleration with Low-rank Distillation
May 08, 2025Due to long generations, large language model (LLM) math reasoning demands significant computational resources and time. While many existing efficient inference methods have been developed with excellent performance preservation on language tasks, they often severely degrade math performance. In this paper, we propose Caprese, a low-cost distillation method to recover lost capabilities from deploying efficient inference methods, focused primarily in feedforward blocks. With original weights unperturbed, roughly 1% of additional parameters, and only 20K synthetic training samples, we are able to recover much if not all of the math capabilities lost from efficient inference for thinking LLMs and without harm to language tasks for instruct LLMs. Moreover, Caprese slashes the number of active parameters (~2B cut for Gemma 2 9B and Llama 3.1 8B) and integrates cleanly into existing model layers to reduce latency (>11% reduction to generate 2048 tokens with Qwen 2.5 14B) while encouraging response brevity.
Towards Low-bit Communication for Tensor Parallel LLM Inference
Nov 12, 2024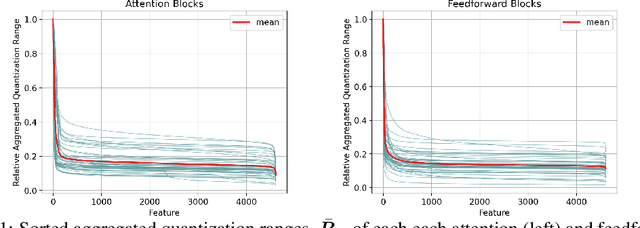
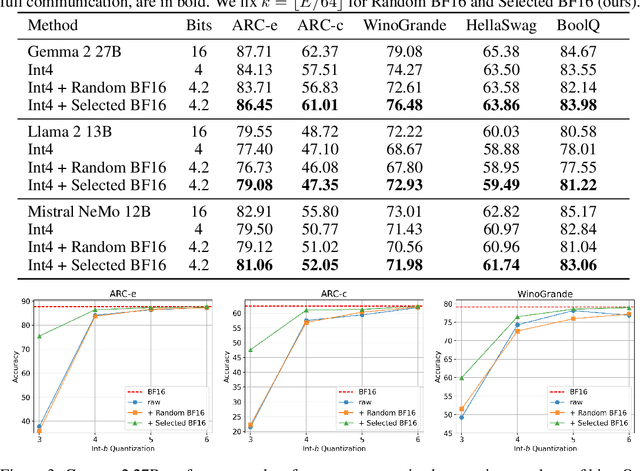

Tensor parallelism provides an effective way to increase server large language model (LLM) inference efficiency despite adding an additional communication cost. However, as server LLMs continue to scale in size, they will need to be distributed across more devices, magnifying the communication cost. One way to approach this problem is with quantization, but current methods for LLMs tend to avoid quantizing the features that tensor parallelism needs to communicate. Taking advantage of consistent outliers in communicated features, we introduce a quantization method that reduces communicated values on average from 16 bits to 4.2 bits while preserving nearly all of the original performance. For instance, our method maintains around 98.0% and 99.5% of Gemma 2 27B's and Llama 2 13B's original performance, respectively, averaged across all tasks we evaluated on.
ShadowKV: KV Cache in Shadows for High-Throughput Long-Context LLM Inference
Oct 28, 2024With the widespread deployment of long-context large language models (LLMs), there has been a growing demand for efficient support of high-throughput inference. However, as the key-value (KV) cache expands with the sequence length, the increasing memory footprint and the need to access it for each token generation both result in low throughput when serving long-context LLMs. While various dynamic sparse attention methods have been proposed to speed up inference while maintaining generation quality, they either fail to sufficiently reduce GPU memory consumption or introduce significant decoding latency by offloading the KV cache to the CPU. We present ShadowKV, a high-throughput long-context LLM inference system that stores the low-rank key cache and offloads the value cache to reduce the memory footprint for larger batch sizes and longer sequences. To minimize decoding latency, ShadowKV employs an accurate KV selection strategy that reconstructs minimal sparse KV pairs on-the-fly. By evaluating ShadowKV on a broad range of benchmarks, including RULER, LongBench, and Needle In A Haystack, and models like Llama-3.1-8B, Llama-3-8B-1M, GLM-4-9B-1M, Yi-9B-200K, Phi-3-Mini-128K, and Qwen2-7B-128K, we demonstrate that it can support up to 6$\times$ larger batch sizes and boost throughput by up to 3.04$\times$ on an A100 GPU without sacrificing accuracy, even surpassing the performance achievable with infinite batch size under the assumption of infinite GPU memory. The code is available at https://github.com/bytedance/ShadowKV.
Leveraging Multimodal Diffusion Models to Accelerate Imaging with Side Information
Oct 07, 2024



Diffusion models have found phenomenal success as expressive priors for solving inverse problems, but their extension beyond natural images to more structured scientific domains remains limited. Motivated by applications in materials science, we aim to reduce the number of measurements required from an expensive imaging modality of interest, by leveraging side information from an auxiliary modality that is much cheaper to obtain. To deal with the non-differentiable and black-box nature of the forward model, we propose a framework to train a multimodal diffusion model over the joint modalities, turning inverse problems with black-box forward models into simple linear inpainting problems. Numerically, we demonstrate the feasibility of training diffusion models over materials imagery data, and show that our approach achieves superior image reconstruction by leveraging the available side information, requiring significantly less amount of data from the expensive microscopy modality.
Prompt-prompted Mixture of Experts for Efficient LLM Generation
Apr 05, 2024



With the development of transformer-based large language models (LLMs), they have been applied to many fields due to their remarkable utility, but this comes at a considerable computational cost at deployment. Fortunately, some methods such as pruning or constructing a mixture of experts (MoE) aim at exploiting sparsity in transformer feedforward (FF) blocks to gain boosts in speed and reduction in memory requirements. However, these techniques can be very costly and inflexible in practice, as they often require training or are restricted to specific types of architectures. To address this, we introduce GRIFFIN, a novel training-free MoE that selects unique FF experts at the sequence level for efficient generation across a plethora of LLMs with different non-ReLU activation functions. This is possible due to a critical observation that many trained LLMs naturally produce highly structured FF activation patterns within a sequence, which we call flocking. Despite our method's simplicity, we show with 50% of the FF parameters, GRIFFIN maintains the original model's performance with little to no degradation on a variety of classification and generation tasks, all while improving latency (e.g. 1.25$\times$ speed-up in Llama 2 13B on an NVIDIA L40). Code is available at https://github.com/hdong920/GRIFFIN.
Get More with LESS: Synthesizing Recurrence with KV Cache Compression for Efficient LLM Inference
Feb 14, 2024



Many computational factors limit broader deployment of large language models. In this paper, we focus on a memory bottleneck imposed by the key-value (KV) cache, a computational shortcut that requires storing previous KV pairs during decoding. While existing KV cache methods approach this problem by pruning or evicting large swaths of relatively less important KV pairs to dramatically reduce the memory footprint of the cache, they can have limited success in tasks that require recollecting a majority of previous tokens. To alleviate this issue, we propose LESS, a simple integration of a (nearly free) constant sized cache with eviction-based cache methods, such that all tokens can be queried at later decoding steps. Its ability to retain information throughout time shows merit on a variety of tasks where we demonstrate LESS can help reduce the performance gap from caching everything, sometimes even matching it, all while being efficient.
A Lightweight Transformer for Faster and Robust EBSD Data Collection
Aug 18, 2023Three dimensional electron back-scattered diffraction (EBSD) microscopy is a critical tool in many applications in materials science, yet its data quality can fluctuate greatly during the arduous collection process, particularly via serial-sectioning. Fortunately, 3D EBSD data is inherently sequential, opening up the opportunity to use transformers, state-of-the-art deep learning architectures that have made breakthroughs in a plethora of domains, for data processing and recovery. To be more robust to errors and accelerate this 3D EBSD data collection, we introduce a two step method that recovers missing slices in an 3D EBSD volume, using an efficient transformer model and a projection algorithm to process the transformer's outputs. Overcoming the computational and practical hurdles of deep learning with scarce high dimensional data, we train this model using only synthetic 3D EBSD data with self-supervision and obtain superior recovery accuracy on real 3D EBSD data, compared to existing methods.
Deep Unfolded Tensor Robust PCA with Self-supervised Learning
Dec 21, 2022Tensor robust principal component analysis (RPCA), which seeks to separate a low-rank tensor from its sparse corruptions, has been crucial in data science and machine learning where tensor structures are becoming more prevalent. While powerful, existing tensor RPCA algorithms can be difficult to use in practice, as their performance can be sensitive to the choice of additional hyperparameters, which are not straightforward to tune. In this paper, we describe a fast and simple self-supervised model for tensor RPCA using deep unfolding by only learning four hyperparameters. Despite its simplicity, our model expunges the need for ground truth labels while maintaining competitive or even greater performance compared to supervised deep unfolding. Furthermore, our model is capable of operating in extreme data-starved scenarios. We demonstrate these claims on a mix of synthetic data and real-world tasks, comparing performance against previously studied supervised deep unfolding methods and Bayesian optimization baselines.
Fast and Provable Tensor Robust Principal Component Analysis via Scaled Gradient Descent
Jun 18, 2022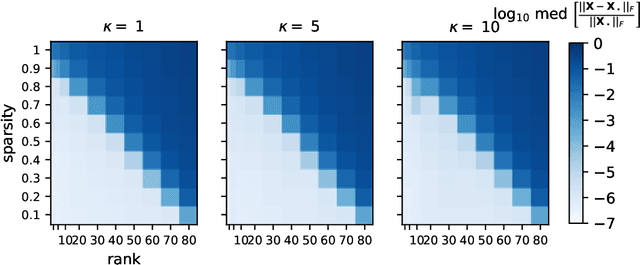
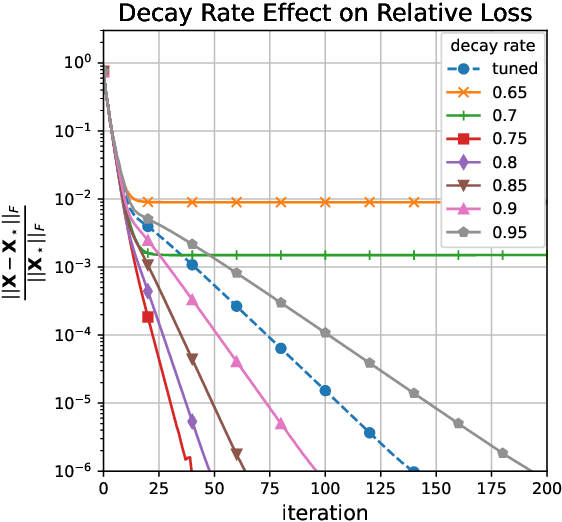


An increasing number of data science and machine learning problems rely on computation with tensors, which better capture the multi-way relationships and interactions of data than matrices. When tapping into this critical advantage, a key challenge is to develop computationally efficient and provably correct algorithms for extracting useful information from tensor data that are simultaneously robust to corruptions and ill-conditioning. This paper tackles tensor robust principal component analysis (RPCA), which aims to recover a low-rank tensor from its observations contaminated by sparse corruptions, under the Tucker decomposition. To minimize the computation and memory footprints, we propose to directly recover the low-dimensional tensor factors -- starting from a tailored spectral initialization -- via scaled gradient descent (ScaledGD), coupled with an iteration-varying thresholding operation to adaptively remove the impact of corruptions. Theoretically, we establish that the proposed algorithm converges linearly to the true low-rank tensor at a constant rate that is independent with its condition number, as long as the level of corruptions is not too large. Empirically, we demonstrate that the proposed algorithm achieves better and more scalable performance than state-of-the-art matrix and tensor RPCA algorithms through synthetic experiments and real-world applications.