 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinite-Time Convergence and Sample Complexity of Actor-Critic Multi-Objective Reinforcement Learning
May 05, 2024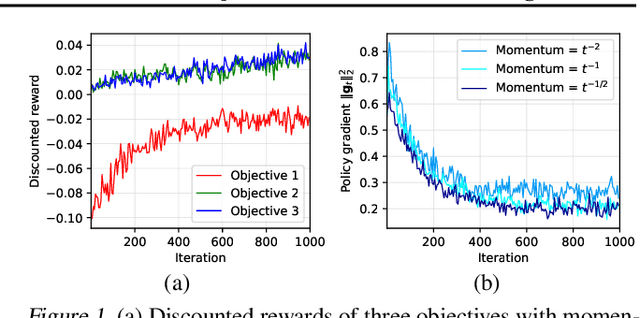
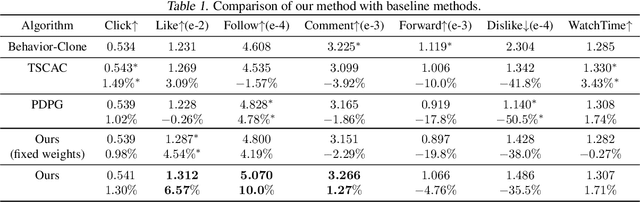
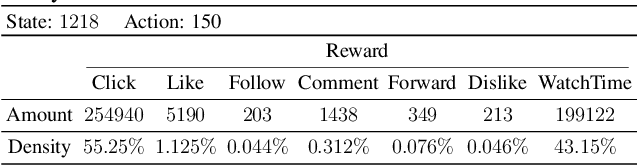
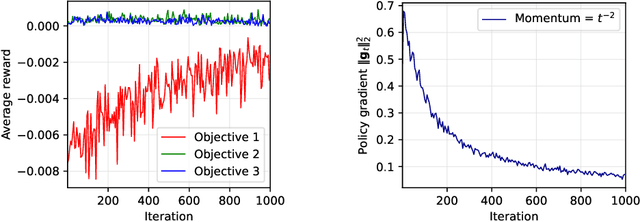
Reinforcement learning with multiple, potentially conflicting objectives is pervasive in real-world applications, while this problem remains theoretically under-explored. This paper tackles the multi-objective reinforcement learning (MORL) problem and introduces an innovative actor-critic algorithm named MOAC which finds a policy by iteratively making trade-offs among conflicting reward signals. Notably, we provide the first analysis of finite-time Pareto-stationary convergence and corresponding sample complexity in both discounted and average reward settings. Our approach has two salient features: (a) MOAC mitigates the cumulative estimation bias resulting from finding an optimal common gradient descent direction out of stochastic samples. This enables provable convergence rate and sample complexity guarantees independent of the number of objectives; (b) With proper momentum coefficient, MOAC initializes the weights of individual policy gradients using samples from the environment, instead of manual initialization. This enhances the practicality and robustness of our algorithm. Finally, experiments conducted on a real-world dataset validate the effectiveness of our proposed method.
Provably Accelerating Ill-Conditioned Low-rank Estimation via Scaled Gradient Descent, Even with Overparameterization
Oct 09, 2023



Many problems encountered in science and engineering can be formulated as estimating a low-rank object (e.g., matrices and tensors) from incomplete, and possibly corrupted, linear measurements. Through the lens of matrix and tensor factorization, one of the most popular approaches is to employ simple iterative algorithms such as gradient descent (GD) to recover the low-rank factors directly, which allow for small memory and computation footprints. However, the convergence rate of GD depends linearly, and sometimes even quadratically, on the condition number of the low-rank object, and therefore, GD slows down painstakingly when the problem is ill-conditioned. This chapter introduces a new algorithmic approach, dubbed scaled gradient descent (ScaledGD), that provably converges linearly at a constant rate independent of the condition number of the low-rank object, while maintaining the low per-iteration cost of gradient descent for a variety of tasks including sensing, robust principal component analysis and completion. In addition, ScaledGD continues to admit fast global convergence to the minimax-optimal solution, again almost independent of the condition number, from a small random initialization when the rank is over-specified in the presence of Gaussian noise. In total, ScaledGD highlights the power of appropriate preconditioning in accelerating nonconvex statistical estimation, where the iteration-varying preconditioners promote desirable invariance properties of the trajectory with respect to the symmetry in low-rank factorization without hurting generalization.
Fast and Provable Tensor Robust Principal Component Analysis via Scaled Gradient Descent
Jun 18, 2022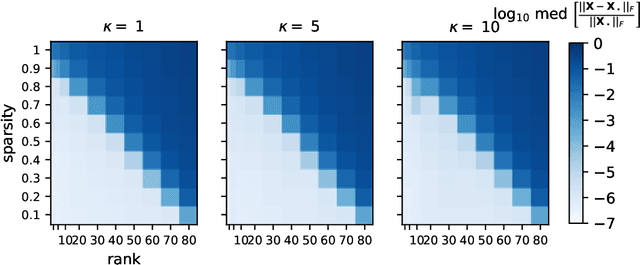


An increasing number of data science and machine learning problems rely on computation with tensors, which better capture the multi-way relationships and interactions of data than matrices. When tapping into this critical advantage, a key challenge is to develop computationally efficient and provably correct algorithms for extracting useful information from tensor data that are simultaneously robust to corruptions and ill-conditioning. This paper tackles tensor robust principal component analysis (RPCA), which aims to recover a low-rank tensor from its observations contaminated by sparse corruptions, under the Tucker decomposition. To minimize the computation and memory footprints, we propose to directly recover the low-dimensional tensor factors -- starting from a tailored spectral initialization -- via scaled gradient descent (ScaledGD), coupled with an iteration-varying thresholding operation to adaptively remove the impact of corruptions. Theoretically, we establish that the proposed algorithm converges linearly to the true low-rank tensor at a constant rate that is independent with its condition number, as long as the level of corruptions is not too large. Empirically, we demonstrate that the proposed algorithm achieves better and more scalable performance than state-of-the-art matrix and tensor RPCA algorithms through synthetic experiments and real-world applications.
Scaling and Scalability: Provable Nonconvex Low-Rank Tensor Estimation from Incomplete Measurements
Apr 29, 2021
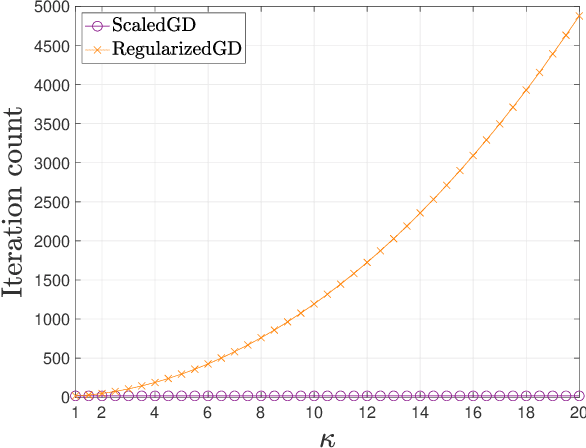
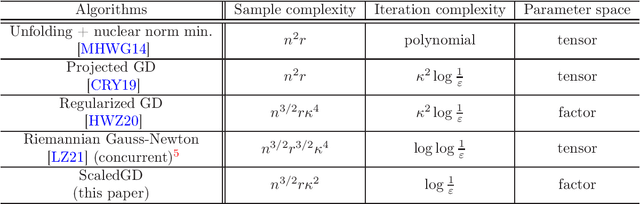
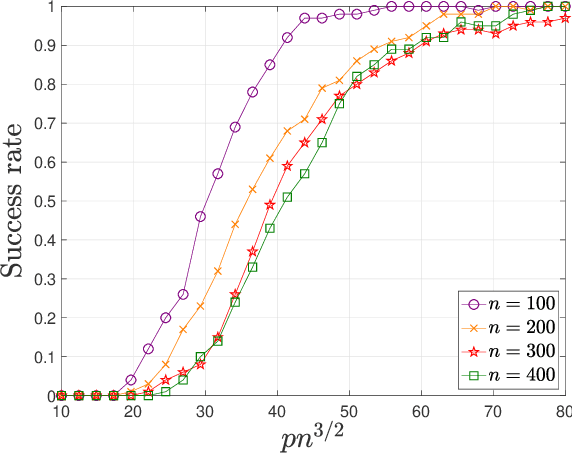
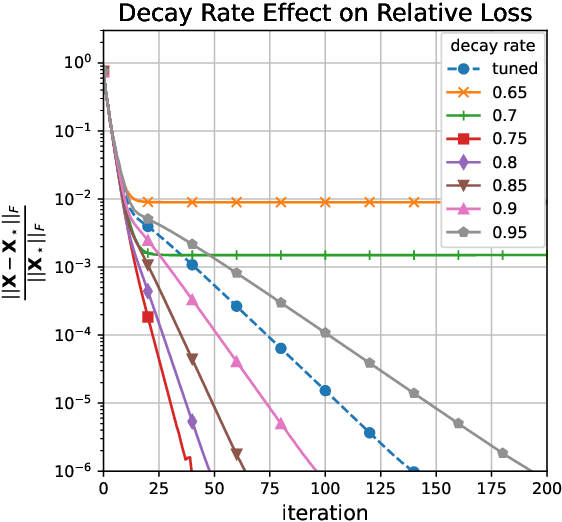
Tensors, which provide a powerful and flexible model for representing multi-attribute data and multi-way interactions, play an indispensable role in modern data science across various fields in science and engineering. A fundamental task is to faithfully recover the tensor from highly incomplete measurements in a statistically and computationally efficient manner. Harnessing the low-rank structure of tensors in the Tucker decomposition, this paper develops a scaled gradient descent (ScaledGD) algorithm to directly recover the tensor factors with tailored spectral initializations, and shows that it provably converges at a linear rate independent of the condition number of the ground truth tensor for two canonical problems -- tensor completion and tensor regression -- as soon as the sample size is above the order of $n^{3/2}$ ignoring other dependencies, where $n$ is the dimension of the tensor. This leads to an extremely scalable approach to low-rank tensor estimation compared with prior art, which suffers from at least one of the following drawbacks: extreme sensitivity to ill-conditioning, high per-iteration costs in terms of memory and computation, or poor sample complexity guarantees. To the best of our knowledge, ScaledGD is the first algorithm that achieves near-optimal statistical and computational complexities simultaneously for low-rank tensor completion with the Tucker decomposition. Our algorithm highlights the power of appropriate preconditioning in accelerating nonconvex statistical estimation, where the iteration-varying preconditioners promote desirable invariance properties of the trajectory with respect to the underlying symmetry in low-rank tensor factorization.
Low-Rank Matrix Recovery with Scaled Subgradient Methods: Fast and Robust Convergence Without the Condition Number
Oct 26, 2020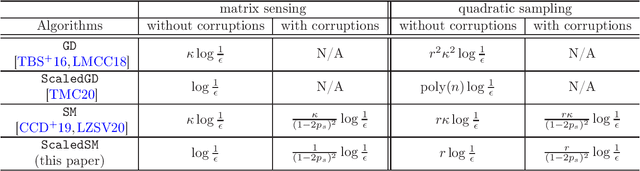
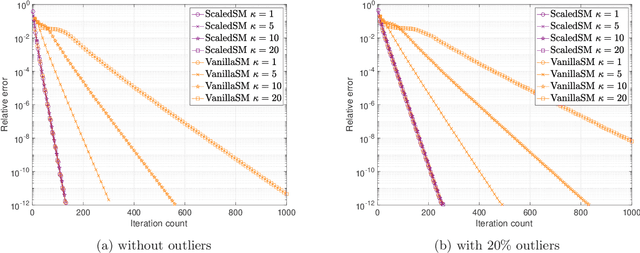
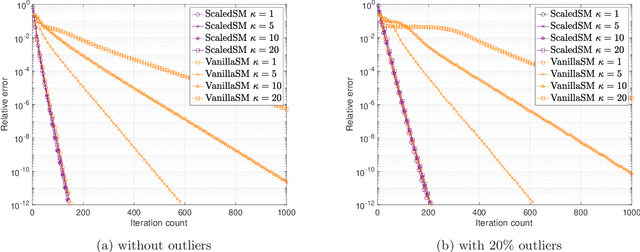
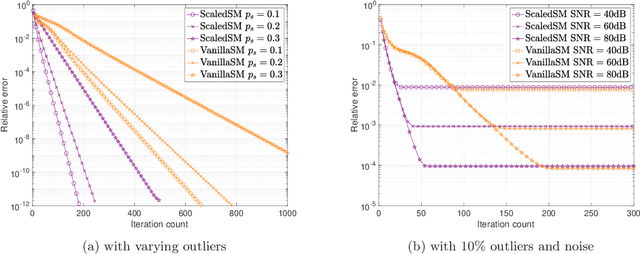
Many problems in data science can be treated as estimating a low-rank matrix from highly incomplete, sometimes even corrupted, observations. One popular approach is to resort to matrix factorization, where the low-rank matrix factors are optimized via first-order methods over a smooth loss function, such as the residual sum of squares. While tremendous progresses have been made in recent years, the natural smooth formulation suffers from two sources of ill-conditioning, where the iteration complexity of gradient descent scales poorly both with the dimension as well as the condition number of the low-rank matrix. Moreover, the smooth formulation is not robust to corruptions. In this paper, we propose scaled subgradient methods to minimize a family of nonsmooth and nonconvex formulations -- in particular, the residual sum of absolute errors -- which is guaranteed to converge at a fast rate that is almost dimension-free and independent of the condition number, even in the presence of corruptions. We illustrate the effectiveness of our approach when the observation operator satisfies certain mixed-norm restricted isometry properties, and derive state-of-the-art performance guarantees for a variety of problems such as robust low-rank matrix sensing and quadratic sampling.
Accelerating Ill-Conditioned Low-Rank Matrix Estimation via Scaled Gradient Descent
May 18, 2020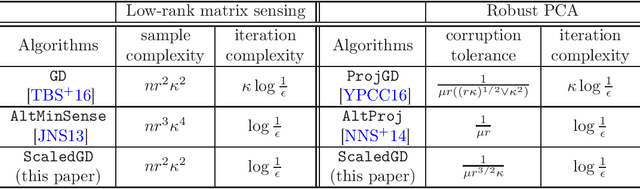
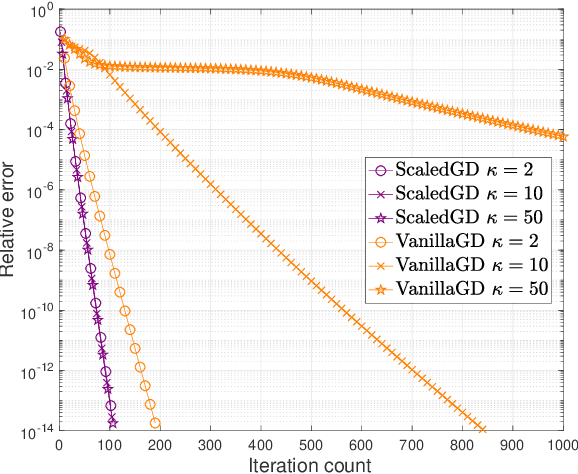
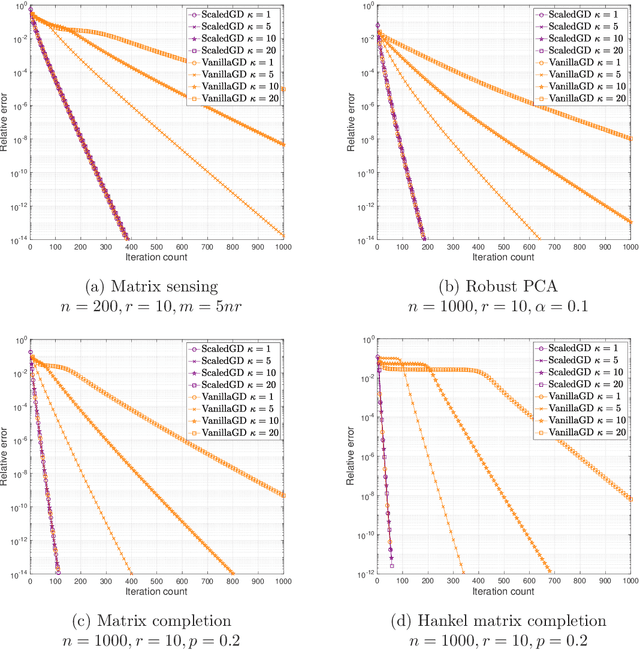
Low-rank matrix estimation is a canonical problem that finds numerous applications in signal processing, machine learning and imaging science. A popular approach in practice is to factorize the matrix into two compact low-rank factors, and then seek to optimize these factors directly via simple iterative methods such as gradient descent and alternating minimization. Despite nonconvexity, recent literatures have shown that these simple heuristics in fact achieve linear convergence when initialized properly for a growing number of problems of interest. However, upon closer examination, existing approaches can still be computationally expensive especially for ill-conditioned matrices: the convergence rate of gradient descent depends linearly on the condition number of the low-rank matrix, while the per-iteration cost of alternating minimization is often prohibitive for large matrices. The goal of this paper is to set forth a new algorithmic approach dubbed Scaled Gradient Descent (ScaledGD) which can be viewed as pre-conditioned or diagonally-scaled gradient descent, where the pre-conditioners are adaptive and iteration-varying with a minimal computational overhead. For low-rank matrix sensing and robust principal component analysis, we theoretically show that ScaledGD achieves the best of both worlds: it converges linearly at a rate independent of the condition number similar as alternating minimization, while maintaining the low per-iteration cost of gradient descent. To the best of our knowledge, ScaledGD is the first algorithm that provably has such properties. At the core of our analysis is the introduction of a new distance function that takes account of the pre-conditioners when measuring the distance between the iterates and the ground truth.