 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndependently-Normalized SGD for Generalized-Smooth Nonconvex Optimization
Oct 17, 2024


Recent studies have shown that many nonconvex machine learning problems meet a so-called generalized-smooth condition that extends beyond traditional smooth nonconvex optimization. However, the existing algorithms designed for generalized-smooth nonconvex optimization encounter significant limitations in both their design and convergence analysis. In this work, we first study deterministic generalized-smooth nonconvex optimization and analyze the convergence of normalized gradient descent under the generalized Polyak-Lojasiewicz condition. Our results provide a comprehensive understanding of the interplay between gradient normalization and function geometry. Then, for stochastic generalized-smooth nonconvex optimization, we propose an independently-normalized stochastic gradient descent algorithm, which leverages independent sampling, gradient normalization and clipping to achieve an $\mathcal{O}(\epsilon^{-4})$ sample complexity under relaxed assumptions. Experiments demonstrate the fast convergence of our algorithm.
Scaling and Scalability: Provable Nonconvex Low-Rank Tensor Estimation from Incomplete Measurements
Apr 29, 2021
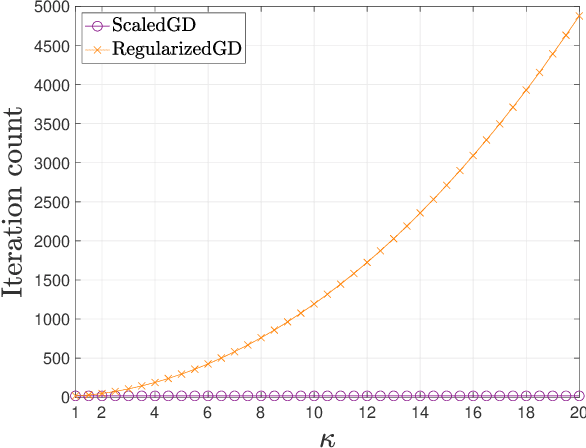
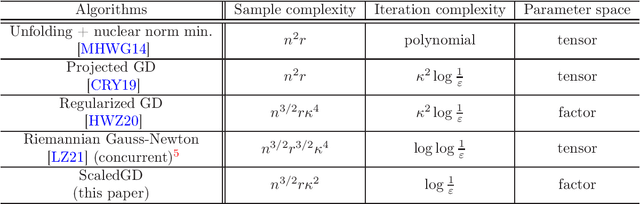
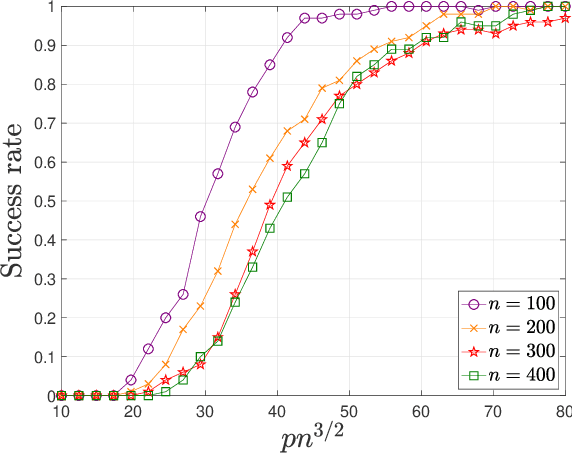
Tensors, which provide a powerful and flexible model for representing multi-attribute data and multi-way interactions, play an indispensable role in modern data science across various fields in science and engineering. A fundamental task is to faithfully recover the tensor from highly incomplete measurements in a statistically and computationally efficient manner. Harnessing the low-rank structure of tensors in the Tucker decomposition, this paper develops a scaled gradient descent (ScaledGD) algorithm to directly recover the tensor factors with tailored spectral initializations, and shows that it provably converges at a linear rate independent of the condition number of the ground truth tensor for two canonical problems -- tensor completion and tensor regression -- as soon as the sample size is above the order of $n^{3/2}$ ignoring other dependencies, where $n$ is the dimension of the tensor. This leads to an extremely scalable approach to low-rank tensor estimation compared with prior art, which suffers from at least one of the following drawbacks: extreme sensitivity to ill-conditioning, high per-iteration costs in terms of memory and computation, or poor sample complexity guarantees. To the best of our knowledge, ScaledGD is the first algorithm that achieves near-optimal statistical and computational complexities simultaneously for low-rank tensor completion with the Tucker decomposition. Our algorithm highlights the power of appropriate preconditioning in accelerating nonconvex statistical estimation, where the iteration-varying preconditioners promote desirable invariance properties of the trajectory with respect to the underlying symmetry in low-rank tensor factorization.