 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOwen-Shapley Policy Optimization (OSPO): A Principled RL Algorithm for Generative Search LLMs
Jan 13, 2026Large language models are increasingly trained via reinforcement learning for personalized recommendation tasks, but standard methods like GRPO rely on sparse, sequence-level rewards that create a credit assignment gap, obscuring which tokens drive success. This gap is especially problematic when models must infer latent user intent from under-specified language without ground truth labels, a reasoning pattern rarely seen during pretraining. We introduce Owen-Shapley Policy Optimization (OSPO), a framework that redistributes sequence-level advantages based on tokens' marginal contributions to outcomes. Unlike value-model-based methods requiring additional computation, OSPO employs potential-based reward shaping via Shapley-Owen attributions to assign segment-level credit while preserving the optimal policy, learning directly from task feedback without parametric value models. By forming coalitions of semantically coherent units (phrases describing product attributes or sentences capturing preferences), OSPO identifies which response parts drive performance. Experiments on Amazon ESCI and H&M Fashion datasets show consistent gains over baselines, with notable test-time robustness to out-of-distribution retrievers unseen during training.
PCL: Prompt-based Continual Learning for User Modeling in Recommender Systems
Feb 26, 2025



User modeling in large e-commerce platforms aims to optimize user experiences by incorporating various customer activities. Traditional models targeting a single task often focus on specific business metrics, neglecting the comprehensive user behavior, and thus limiting their effectiveness. To develop more generalized user representations, some existing work adopts Multi-task Learning (MTL)approaches. But they all face the challenges of optimization imbalance and inefficiency in adapting to new tasks. Continual Learning (CL), which allows models to learn new tasks incrementally and independently, has emerged as a solution to MTL's limitations. However, CL faces the challenge of catastrophic forgetting, where previously learned knowledge is lost when the model is learning the new task. Inspired by the success of prompt tuning in Pretrained Language Models (PLMs), we propose PCL, a Prompt-based Continual Learning framework for user modeling, which utilizes position-wise prompts as external memory for each task, preserving knowledge and mitigating catastrophic forgetting. Additionally, we design contextual prompts to capture and leverage inter-task relationships during prompt tuning. We conduct extensive experiments on real-world datasets to demonstrate PCL's effectiveness.
Finite-Time Convergence and Sample Complexity of Actor-Critic Multi-Objective Reinforcement Learning
May 05, 2024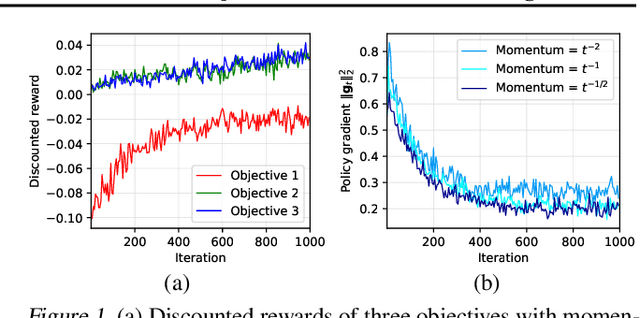
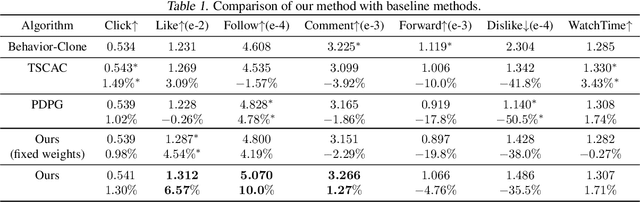
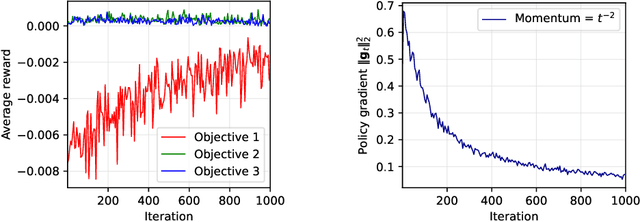
Reinforcement learning with multiple, potentially conflicting objectives is pervasive in real-world applications, while this problem remains theoretically under-explored. This paper tackles the multi-objective reinforcement learning (MORL) problem and introduces an innovative actor-critic algorithm named MOAC which finds a policy by iteratively making trade-offs among conflicting reward signals. Notably, we provide the first analysis of finite-time Pareto-stationary convergence and corresponding sample complexity in both discounted and average reward settings. Our approach has two salient features: (a) MOAC mitigates the cumulative estimation bias resulting from finding an optimal common gradient descent direction out of stochastic samples. This enables provable convergence rate and sample complexity guarantees independent of the number of objectives; (b) With proper momentum coefficient, MOAC initializes the weights of individual policy gradients using samples from the environment, instead of manual initialization. This enhances the practicality and robustness of our algorithm. Finally, experiments conducted on a real-world dataset validate the effectiveness of our proposed method.
Bandit Learning to Rank with Position-Based Click Models: Personalized and Equal Treatments
Nov 08, 2023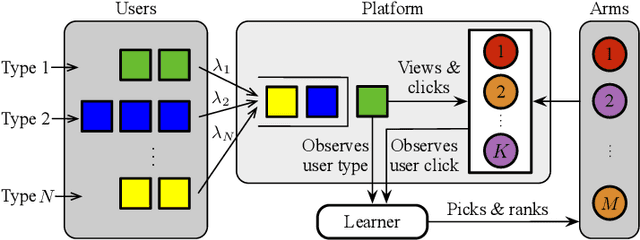
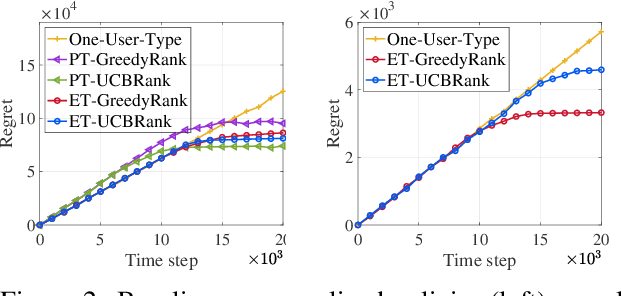

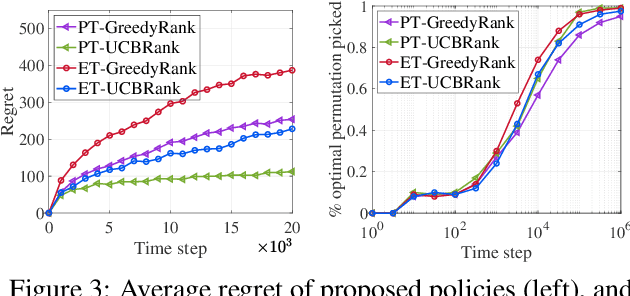
Online learning to rank (ONL2R) is a foundational problem for recommender systems and has received increasing attention in recent years. Among the existing approaches for ONL2R, a natural modeling architecture is the multi-armed bandit framework coupled with the position-based click model. However, developing efficient online learning policies for MAB-based ONL2R with position-based click models is highly challenging due to the combinatorial nature of the problem, and partial observability in the position-based click model. To date, results in MAB-based ONL2R with position-based click models remain rather limited, which motivates us to fill this gap in this work. Our main contributions in this work are threefold: i) We propose the first general MAB framework that captures all key ingredients of ONL2R with position-based click models. Our model considers personalized and equal treatments in ONL2R ranking recommendations, both of which are widely used in practice; ii) Based on the above analytical framework, we develop two unified greed- and UCB-based policies called GreedyRank and UCBRank, each of which can be applied to personalized and equal ranking treatments; and iii) We show that both GreedyRank and UCBRank enjoy $O(\sqrt{t}\ln t)$ and $O(\sqrt{t\ln t})$ anytime sublinear regret for personalized and equal treatment, respectively. For the fundamentally hard equal ranking treatment, we identify classes of collective utility functions and their associated sufficient conditions under which $O(\sqrt{t}\ln t)$ and $O(\sqrt{t\ln t})$ anytime sublinear regrets are still achievable for GreedyRank and UCBRank, respectively. Our numerical experiments also verify our theoretical results and demonstrate the efficiency of GreedyRank and UCBRank in seeking the optimal action under various problem settings.
AdaSelection: Accelerating Deep Learning Training through Data Subsampling
Jun 19, 2023
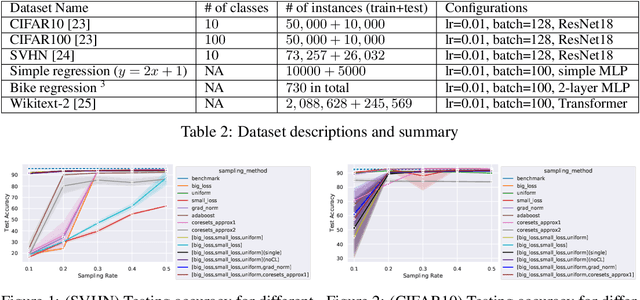
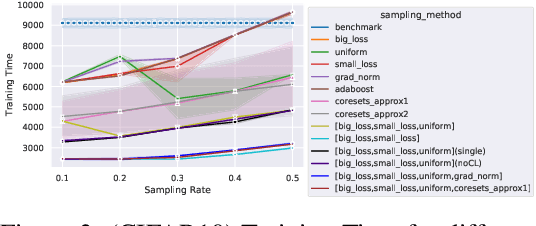
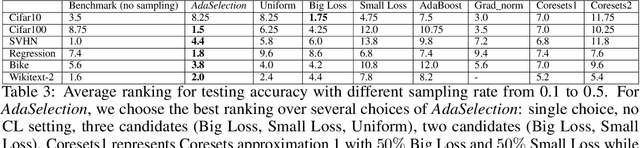
In this paper, we introduce AdaSelection, an adaptive sub-sampling method to identify the most informative sub-samples within each minibatch to speed up the training of large-scale deep learning models without sacrificing model performance. Our method is able to flexibly combines an arbitrary number of baseline sub-sampling methods incorporating the method-level importance and intra-method sample-level importance at each iteration. The standard practice of ad-hoc sampling often leads to continuous training with vast amounts of data from production environments. To improve the selection of data instances during forward and backward passes, we propose recording a constant amount of information per instance from these passes. We demonstrate the effectiveness of our method by testing it across various types of inputs and tasks, including the classification tasks on both image and language datasets, as well as regression tasks. Compared with industry-standard baselines, AdaSelection consistently displays superior performance.
SLPerf: a Unified Framework for Benchmarking Split Learning
Apr 04, 2023Data privacy concerns has made centralized training of data, which is scattered across silos, infeasible, leading to the need for collaborative learning frameworks. To address that, two prominent frameworks emerged, i.e., federated learning (FL) and split learning (SL). While FL has established various benchmark frameworks and research libraries, SL currently lacks a unified library despite its diversity in terms of label sharing, model aggregation, and cut layer choice. This lack of standardization makes comparing SL paradigms difficult. To address this, we propose SLPerf, a unified research framework and open research library for SL, and conduct extensive experiments on four widely-used datasets under both IID and Non-IID data settings. Our contributions include a comprehensive survey of recently proposed SL paradigms, a detailed benchmark comparison of different SL paradigms in different situations, and rich engineering take-away messages and research insights for improving SL paradigms. SLPerf can facilitate SL algorithm development and fair performance comparisons.
Incentivized Bandit Learning with Self-Reinforcing User Preferences
May 31, 2021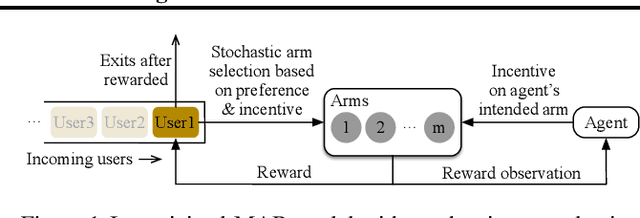
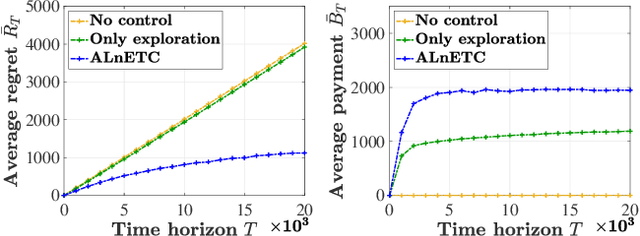
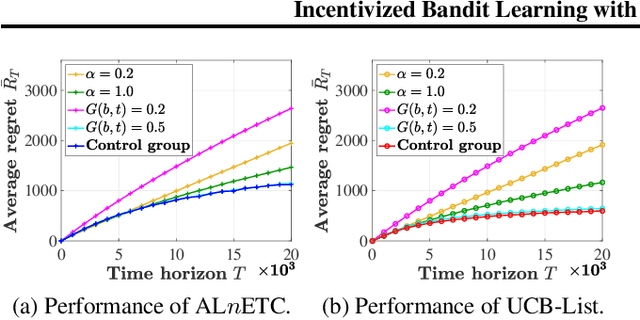
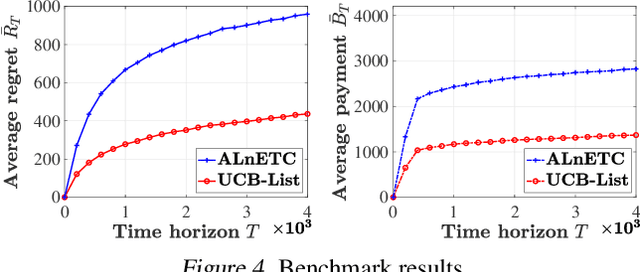
In this paper, we investigate a new multi-armed bandit (MAB) online learning model that considers real-world phenomena in many recommender systems: (i) the learning agent cannot pull the arms by itself and thus has to offer rewards to users to incentivize arm-pulling indirectly; and (ii) if users with specific arm preferences are well rewarded, they induce a "self-reinforcing" effect in the sense that they will attract more users of similar arm preferences. Besides addressing the tradeoff of exploration and exploitation, another key feature of this new MAB model is to balance reward and incentivizing payment. The goal of the agent is to maximize the total reward over a fixed time horizon $T$ with a low total payment. Our contributions in this paper are two-fold: (i) We propose a new MAB model with random arm selection that considers the relationship of users' self-reinforcing preferences and incentives; and (ii) We leverage the properties of a multi-color Polya urn with nonlinear feedback model to propose two MAB policies termed "At-Least-$n$ Explore-Then-Commit" and "UCB-List". We prove that both policies achieve $O(log T)$ expected regret with $O(log T)$ expected payment over a time horizon $T$. We conduct numerical simulations to demonstrate and verify the performances of these two policies and study their robustness under various settings.