 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCL: Prompt-based Continual Learning for User Modeling in Recommender Systems
Feb 26, 2025



User modeling in large e-commerce platforms aims to optimize user experiences by incorporating various customer activities. Traditional models targeting a single task often focus on specific business metrics, neglecting the comprehensive user behavior, and thus limiting their effectiveness. To develop more generalized user representations, some existing work adopts Multi-task Learning (MTL)approaches. But they all face the challenges of optimization imbalance and inefficiency in adapting to new tasks. Continual Learning (CL), which allows models to learn new tasks incrementally and independently, has emerged as a solution to MTL's limitations. However, CL faces the challenge of catastrophic forgetting, where previously learned knowledge is lost when the model is learning the new task. Inspired by the success of prompt tuning in Pretrained Language Models (PLMs), we propose PCL, a Prompt-based Continual Learning framework for user modeling, which utilizes position-wise prompts as external memory for each task, preserving knowledge and mitigating catastrophic forgetting. Additionally, we design contextual prompts to capture and leverage inter-task relationships during prompt tuning. We conduct extensive experiments on real-world datasets to demonstrate PCL's effectiveness.
Cost-Effective Hallucination Detection for LLMs
Jul 31, 2024



Large language models (LLMs) can be prone to hallucinations - generating unreliable outputs that are unfaithful to their inputs, external facts or internally inconsistent. In this work, we address several challenges for post-hoc hallucination detection in production settings. Our pipeline for hallucination detection entails: first, producing a confidence score representing the likelihood that a generated answer is a hallucination; second, calibrating the score conditional on attributes of the inputs and candidate response; finally, performing detection by thresholding the calibrated score. We benchmark a variety of state-of-the-art scoring methods on different datasets, encompassing question answering, fact checking, and summarization tasks. We employ diverse LLMs to ensure a comprehensive assessment of performance. We show that calibrating individual scoring methods is critical for ensuring risk-aware downstream decision making. Based on findings that no individual score performs best in all situations, we propose a multi-scoring framework, which combines different scores and achieves top performance across all datasets. We further introduce cost-effective multi-scoring, which can match or even outperform more expensive detection methods, while significantly reducing computational overhead.
Q-Tuning: Queue-based Prompt Tuning for Lifelong Few-shot Language Learning
Apr 22, 2024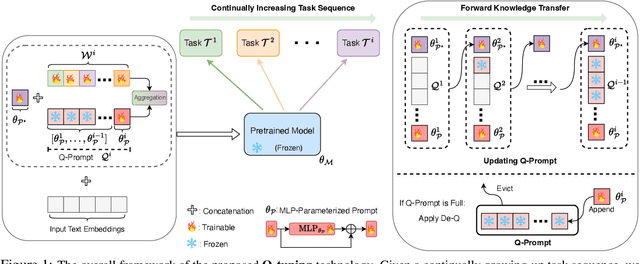
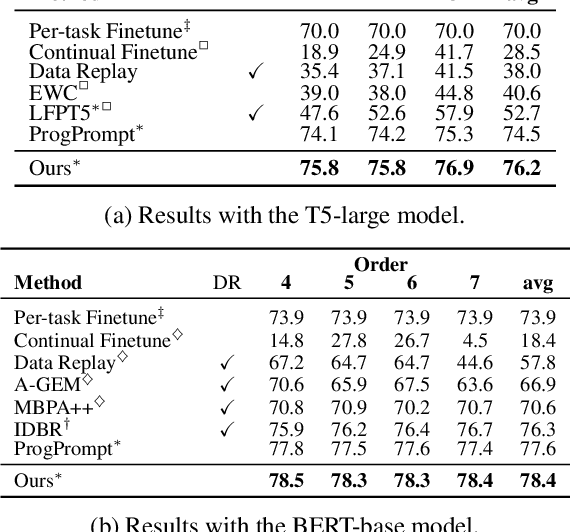
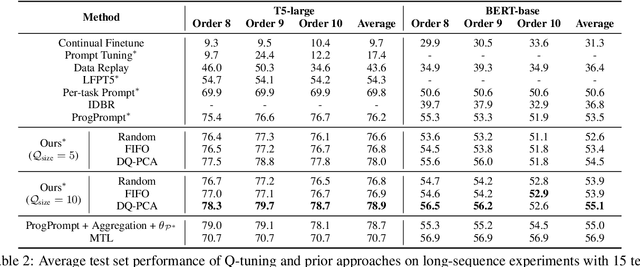
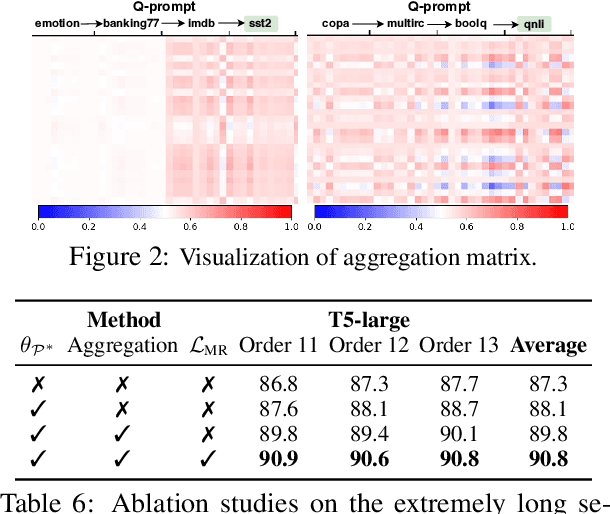
This paper introduces \textbf{Q-tuning}, a novel approach for continual prompt tuning that enables the lifelong learning of a pre-trained language model. When learning a new task, Q-tuning trains a task-specific prompt by adding it to a prompt queue consisting of the prompts from older tasks. To better transfer the knowledge of old tasks, we design an adaptive knowledge aggregation technique that reweighs previous prompts in the queue with a learnable low-rank matrix. Once the prompt queue reaches its maximum capacity, we leverage a PCA-based eviction rule to reduce the queue's size, allowing the newly trained prompt to be added while preserving the primary knowledge of old tasks. In order to mitigate the accumulation of information loss caused by the eviction, we additionally propose a globally shared prefix prompt and a memory retention regularization based on information theory. Extensive experiments demonstrate that our approach outperforms the state-of-the-art methods substantially on continual prompt tuning benchmarks. Moreover, our approach enables lifelong learning on linearly growing task sequences while requiring constant complexity for training and inference.
Hierarchical Conditional Semi-Paired Image-to-Image Translation For Multi-Task Image Defect Correction On Shopping Websites
Sep 12, 2023On shopping websites, product images of low quality negatively affect customer experience. Although there are plenty of work in detecting images with different defects, few efforts have been dedicated to correct those defects at scale. A major challenge is that there are thousands of product types and each has specific defects, therefore building defect specific models is unscalable. In this paper, we propose a unified Image-to-Image (I2I) translation model to correct multiple defects across different product types. Our model leverages an attention mechanism to hierarchically incorporate high-level defect groups and specific defect types to guide the network to focus on defect-related image regions. Evaluated on eight public datasets, our model reduces the Frechet Inception Distance (FID) by 24.6% in average compared with MoNCE, the state-of-the-art I2I method. Unlike public data, another practical challenge on shopping websites is that some paired images are of low quality. Therefore we design our model to be semi-paired by combining the L1 loss of paired data with the cycle loss of unpaired data. Tested on a shopping website dataset to correct three image defects, our model reduces (FID) by 63.2% in average compared with WS-I2I, the state-of-the art semi-paired I2I method.
KD-FixMatch: Knowledge Distillation Siamese Neural Networks
Sep 11, 2023

Semi-supervised learning (SSL) has become a crucial approach in deep learning as a way to address the challenge of limited labeled data. The success of deep neural networks heavily relies on the availability of large-scale high-quality labeled data. However, the process of data labeling is time-consuming and unscalable, leading to shortages in labeled data. SSL aims to tackle this problem by leveraging additional unlabeled data in the training process. One of the popular SSL algorithms, FixMatch, trains identical weight-sharing teacher and student networks simultaneously using a siamese neural network (SNN). However, it is prone to performance degradation when the pseudo labels are heavily noisy in the early training stage. We present KD-FixMatch, a novel SSL algorithm that addresses the limitations of FixMatch by incorporating knowledge distillation. The algorithm utilizes a combination of sequential and simultaneous training of SNNs to enhance performance and reduce performance degradation. Firstly, an outer SNN is trained using labeled and unlabeled data. After that, the network of the well-trained outer SNN generates pseudo labels for the unlabeled data, from which a subset of unlabeled data with trusted pseudo labels is then carefully created through high-confidence sampling and deep embedding clustering. Finally, an inner SNN is trained with the labeled data, the unlabeled data, and the subset of unlabeled data with trusted pseudo labels. Experiments on four public data sets demonstrate that KD-FixMatch outperforms FixMatch in all cases. Our results indicate that KD-FixMatch has a better training starting point that leads to improved model performance compared to FixMatch.
CMA-CLIP: Cross-Modality Attention CLIP for Image-Text Classification
Dec 09, 2021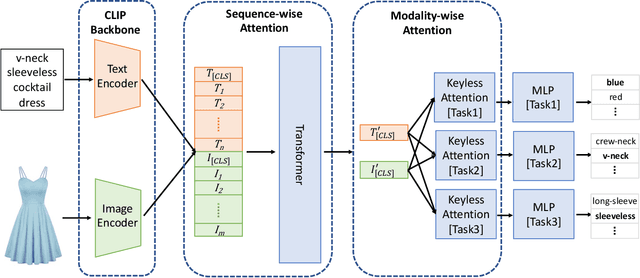

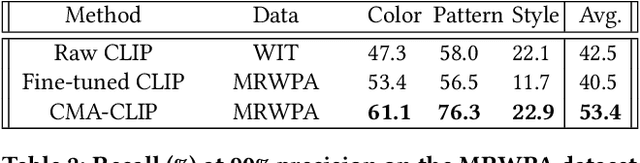

Modern Web systems such as social media and e-commerce contain rich contents expressed in images and text. Leveraging information from multi-modalities can improve the performance of machine learning tasks such as classification and recommendation. In this paper, we propose the Cross-Modality Attention Contrastive Language-Image Pre-training (CMA-CLIP), a new framework which unifies two types of cross-modality attentions, sequence-wise attention and modality-wise attention, to effectively fuse information from image and text pairs. The sequence-wise attention enables the framework to capture the fine-grained relationship between image patches and text tokens, while the modality-wise attention weighs each modality by its relevance to the downstream tasks. In addition, by adding task specific modality-wise attentions and multilayer perceptrons, our proposed framework is capable of performing multi-task classification with multi-modalities. We conduct experiments on a Major Retail Website Product Attribute (MRWPA) dataset and two public datasets, Food101 and Fashion-Gen. The results show that CMA-CLIP outperforms the pre-trained and fine-tuned CLIP by an average of 11.9% in recall at the same level of precision on the MRWPA dataset for multi-task classification. It also surpasses the state-of-the-art method on Fashion-Gen Dataset by 5.5% in accuracy and achieves competitive performance on Food101 Dataset. Through detailed ablation studies, we further demonstrate the effectiveness of both cross-modality attention modules and our method's robustness against noise in image and text inputs, which is a common challenge in practice.
The Blessing and the Curse of the Noise behind Facial Landmark Annotations
Jul 30, 2020

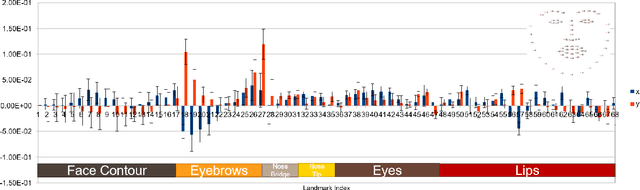
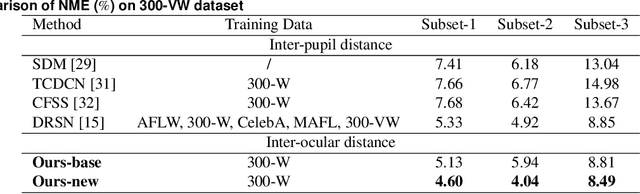
The evolving algorithms for 2D facial landmark detection empower people to recognize faces, analyze facial expressions, etc. However, existing methods still encounter problems of unstable facial landmarks when applied to videos. Because previous research shows that the instability of facial landmarks is caused by the inconsistency of labeling quality among the public datasets, we want to have a better understanding of the influence of annotation noise in them. In this paper, we make the following contributions: 1) we propose two metrics that quantitatively measure the stability of detected facial landmarks, 2) we model the annotation noise in an existing public dataset, 3) we investigate the influence of different types of noise in training face alignment neural networks, and propose corresponding solutions. Our results demonstrate improvements in both accuracy and stability of detected facial landmarks.