 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Tabular Foundation Models via In-Context Kernel Regression
Feb 02, 2026Tabular foundation models like TabPFN and TabICL achieve state-of-the-art performance through in-context learning, yet their architectures remain fundamentally opaque. We introduce KernelICL, a framework to enhance tabular foundation models with quantifiable sample-based interpretability. Building on the insight that in-context learning is akin to kernel regression, we make this mechanism explicit by replacing the final prediction layer with kernel functions (Gaussian, dot-product, kNN) so that every prediction is a transparent weighted average of training labels. We introduce a two-dimensional taxonomy that formally unifies standard kernel methods, modern neighbor-based approaches, and attention mechanisms under a single framework, and quantify inspectability via the perplexity of the weight distribution over training samples. On 55 TALENT benchmark datasets, KernelICL achieves performance on par with existing tabular foundation models, demonstrating that explicit kernel constraints on the final layer enable inspectable predictions without sacrificing performance.
Cost-Effective Hallucination Detection for LLMs
Jul 31, 2024



Large language models (LLMs) can be prone to hallucinations - generating unreliable outputs that are unfaithful to their inputs, external facts or internally inconsistent. In this work, we address several challenges for post-hoc hallucination detection in production settings. Our pipeline for hallucination detection entails: first, producing a confidence score representing the likelihood that a generated answer is a hallucination; second, calibrating the score conditional on attributes of the inputs and candidate response; finally, performing detection by thresholding the calibrated score. We benchmark a variety of state-of-the-art scoring methods on different datasets, encompassing question answering, fact checking, and summarization tasks. We employ diverse LLMs to ensure a comprehensive assessment of performance. We show that calibrating individual scoring methods is critical for ensuring risk-aware downstream decision making. Based on findings that no individual score performs best in all situations, we propose a multi-scoring framework, which combines different scores and achieves top performance across all datasets. We further introduce cost-effective multi-scoring, which can match or even outperform more expensive detection methods, while significantly reducing computational overhead.
Probabilistic Demand Forecasting with Graph Neural Networks
Jan 23, 2024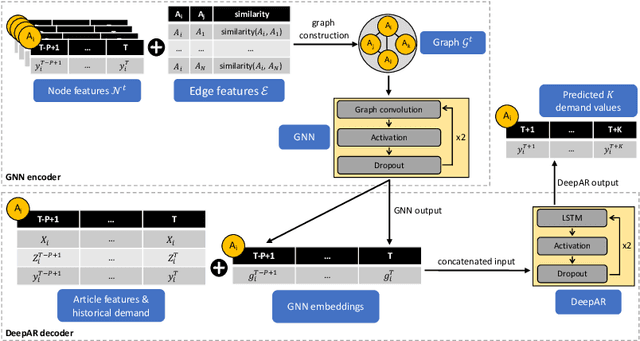



Demand forecasting is a prominent business use case that allows retailers to optimize inventory planning, logistics, and core business decisions. One of the key challenges in demand forecasting is accounting for relationships and interactions between articles. Most modern forecasting approaches provide independent article-level predictions that do not consider the impact of related articles. Recent research has attempted addressing this challenge using Graph Neural Networks (GNNs) and showed promising results. This paper builds on previous research on GNNs and makes two contributions. First, we integrate a GNN encoder into a state-of-the-art DeepAR model. The combined model produces probabilistic forecasts, which are crucial for decision-making under uncertainty. Second, we propose to build graphs using article attribute similarity, which avoids reliance on a pre-defined graph structure. Experiments on three real-world datasets show that the proposed approach consistently outperforms non-graph benchmarks. We also show that our approach produces article embeddings that encode article similarity and demand dynamics and are useful for other downstream business tasks beyond forecasting.
Designing Optimal Behavioral Experiments Using Machine Learning
May 12, 2023



Computational models are powerful tools for understanding human cognition and behavior. They let us express our theories clearly and precisely, and offer predictions that can be subtle and often counter-intuitive. However, this same richness and ability to surprise means our scientific intuitions and traditional tools are ill-suited to designing experiments to test and compare these models. To avoid these pitfalls and realize the full potential of computational modeling, we require tools to design experiments that provide clear answers about what models explain human behavior and the auxiliary assumptions those models must make. Bayesian optimal experimental design (BOED) formalizes the search for optimal experimental designs by identifying experiments that are expected to yield informative data. In this work, we provide a tutorial on leveraging recent advances in BOED and machine learning to find optimal experiments for any kind of model that we can simulate data from, and show how by-products of this procedure allow for quick and straightforward evaluation of models and their parameters against real experimental data. As a case study, we consider theories of how people balance exploration and exploitation in multi-armed bandit decision-making tasks. We validate the presented approach using simulations and a real-world experiment. As compared to experimental designs commonly used in the literature, we show that our optimal designs more efficiently determine which of a set of models best account for individual human behavior, and more efficiently characterize behavior given a preferred model. We provide code to replicate all analyses as well as tutorial notebooks and pointers to adapt the methodology to other experimental settings.
Bayesian Optimal Experimental Design for Simulator Models of Cognition
Oct 29, 2021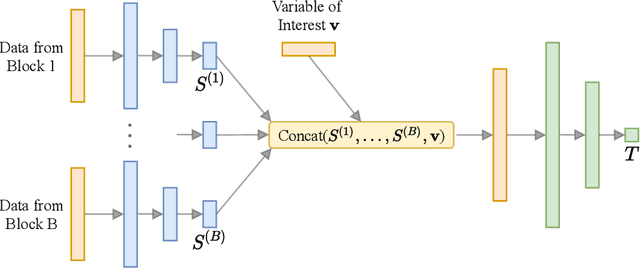


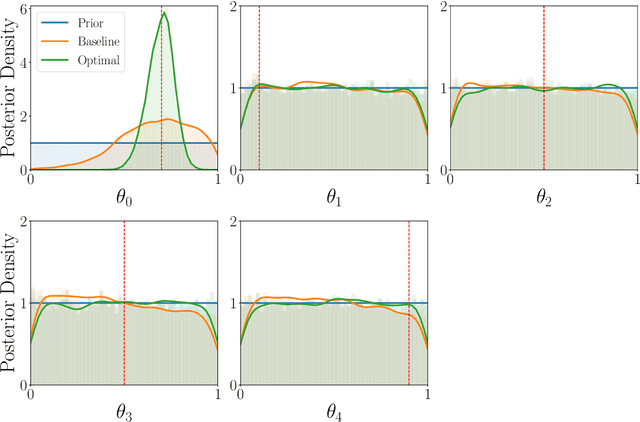
Bayesian optimal experimental design (BOED) is a methodology to identify experiments that are expected to yield informative data. Recent work in cognitive science considered BOED for computational models of human behavior with tractable and known likelihood functions. However, tractability often comes at the cost of realism; simulator models that can capture the richness of human behavior are often intractable. In this work, we combine recent advances in BOED and approximate inference for intractable models, using machine-learning methods to find optimal experimental designs, approximate sufficient summary statistics and amortized posterior distributions. Our simulation experiments on multi-armed bandit tasks show that our method results in improved model discrimination and parameter estimation, as compared to experimental designs commonly used in the literature.