 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFineVAU: A Novel Human-Aligned Benchmark for Fine-Grained Video Anomaly Understanding
Jan 24, 2026Video Anomaly Understanding (VAU) is a novel task focused on describing unusual occurrences in videos. Despite growing interest, the evaluation of VAU remains an open challenge. Existing benchmarks rely on n-gram-based metrics (e.g., BLEU, ROUGE-L) or LLM-based evaluation. The first fails to capture the rich, free-form, and visually grounded nature of LVLM responses, while the latter focuses on assessing language quality over factual relevance, often resulting in subjective judgments that are misaligned with human perception. In this work, we address this issue by proposing FineVAU, a new benchmark for VAU that shifts the focus towards rich, fine-grained and domain-specific understanding of anomalous videos. We formulate VAU as a three-fold problem, with the goal of comprehensively understanding key descriptive elements of anomalies in video: events (What), participating entities (Who) and location (Where). Our benchmark introduces a) FVScore, a novel, human-aligned evaluation metric that assesses the presence of critical visual elements in LVLM answers, providing interpretable, fine-grained feedback; and b) FineW3, a novel, comprehensive dataset curated through a structured and fully automatic procedure that augments existing human annotations with high quality, fine-grained visual information. Human evaluation reveals that our proposed metric has a superior alignment with human perception of anomalies in comparison to current approaches. Detailed experiments on FineVAU unveil critical limitations in LVLM's ability to perceive anomalous events that require spatial and fine-grained temporal understanding, despite strong performance on coarse grain, static information, and events with strong visual cues.
Chain-of-Anomaly Thoughts with Large Vision-Language Models
Dec 23, 2025Automated video surveillance with Large Vision-Language Models is limited by their inherent bias towards normality, often failing to detect crimes. While Chain-of-Thought reasoning strategies show significant potential for improving performance in language tasks, the lack of inductive anomaly biases in their reasoning further steers the models towards normal interpretations. To address this, we propose Chain-of-Anomaly-Thoughts (CoAT), a multi-agent reasoning framework that introduces inductive criminal bias in the reasoning process through a final, anomaly-focused classification layer. Our method significantly improves Anomaly Detection, boosting F1-score by 11.8 p.p. on challenging low-resolution footage and Anomaly Classification by 3.78 p.p. in high-resolution videos.
FLOWING: Implicit Neural Flows for Structure-Preserving Morphing
Oct 10, 2025



Morphing is a long-standing problem in vision and computer graphics, requiring a time-dependent warping for feature alignment and a blending for smooth interpolation. Recently, multilayer perceptrons (MLPs) have been explored as implicit neural representations (INRs) for modeling such deformations, due to their meshlessness and differentiability; however, extracting coherent and accurate morphings from standard MLPs typically relies on costly regularizations, which often lead to unstable training and prevent effective feature alignment. To overcome these limitations, we propose FLOWING (FLOW morphING), a framework that recasts warping as the construction of a differential vector flow, naturally ensuring continuity, invertibility, and temporal coherence by encoding structural flow properties directly into the network architectures. This flow-centric approach yields principled and stable transformations, enabling accurate and structure-preserving morphing of both 2D images and 3D shapes. Extensive experiments across a range of applications - including face and image morphing, as well as Gaussian Splatting morphing - show that FLOWING achieves state-of-the-art morphing quality with faster convergence. Code and pretrained models are available at http://schardong.github.io/flowing.
Cascaded Light Propagation Volumes using Spherical Radial Basis Functions
Jul 24, 2024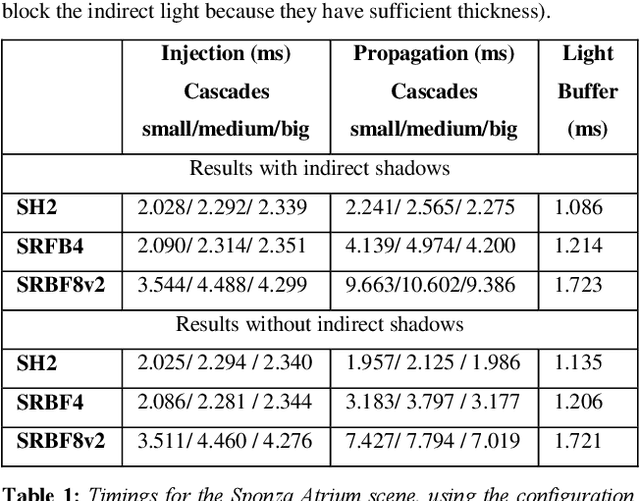
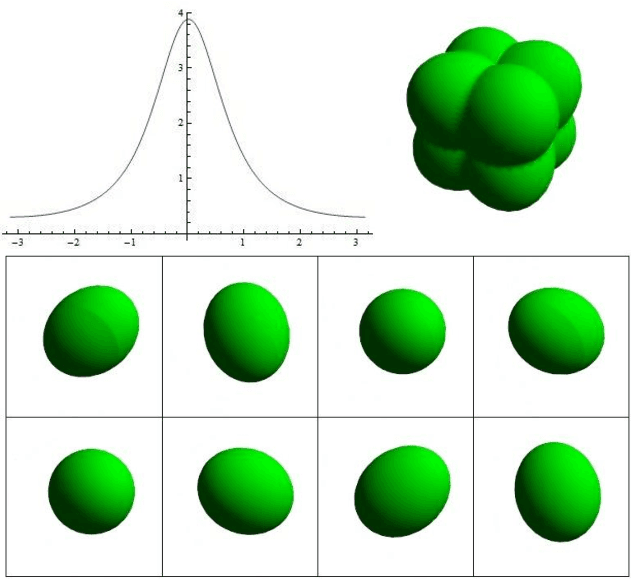
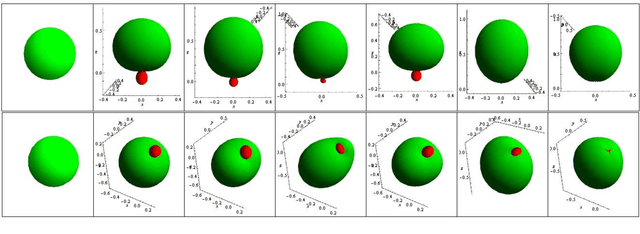

This paper introduces a contribution made to one of the newest methods for simulating indirect lighting in dynamic scenes , the cascaded light propagation volumes . Our contribution consists on using Spherical Radial Basis Functions instead of Spherical Harmonic, since the first achieves much better results when many coefficients are used. We explain how to integrate the Spherical Radial Basis Functions with the cascaded light propagation volumes, and evaluate our technique against the same implementation, but with Spherical harmonics.
Probabilistic Demand Forecasting with Graph Neural Networks
Jan 23, 2024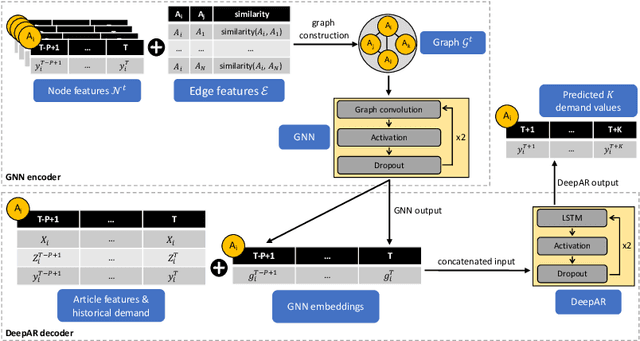



Demand forecasting is a prominent business use case that allows retailers to optimize inventory planning, logistics, and core business decisions. One of the key challenges in demand forecasting is accounting for relationships and interactions between articles. Most modern forecasting approaches provide independent article-level predictions that do not consider the impact of related articles. Recent research has attempted addressing this challenge using Graph Neural Networks (GNNs) and showed promising results. This paper builds on previous research on GNNs and makes two contributions. First, we integrate a GNN encoder into a state-of-the-art DeepAR model. The combined model produces probabilistic forecasts, which are crucial for decision-making under uncertainty. Second, we propose to build graphs using article attribute similarity, which avoids reliance on a pre-defined graph structure. Experiments on three real-world datasets show that the proposed approach consistently outperforms non-graph benchmarks. We also show that our approach produces article embeddings that encode article similarity and demand dynamics and are useful for other downstream business tasks beyond forecasting.
Covered Information Disentanglement: Model Transparency via Unbiased Permutation Importance
Nov 21, 2021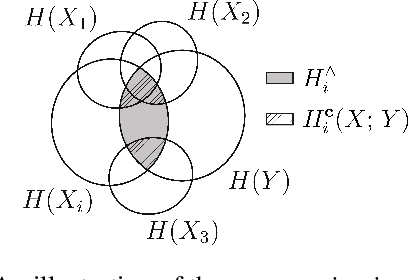
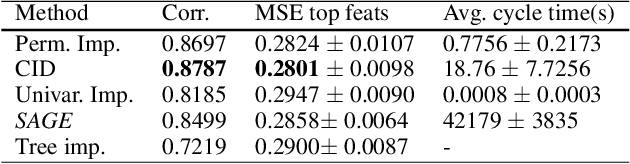
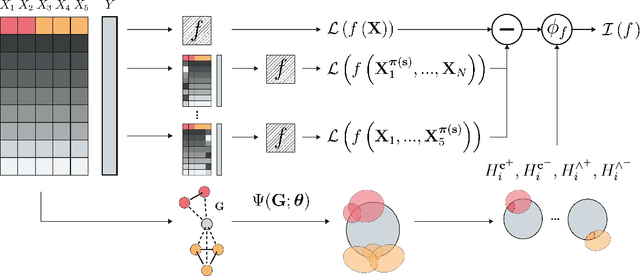
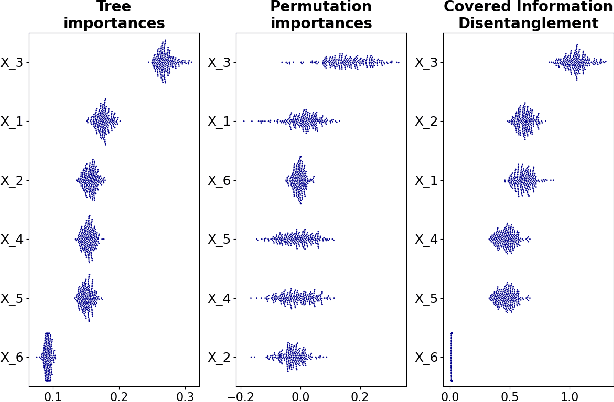
Model transparency is a prerequisite in many domains and an increasingly popular area in machine learning research. In the medical domain, for instance, unveiling the mechanisms behind a disease often has higher priority than the diagnostic itself since it might dictate or guide potential treatments and research directions. One of the most popular approaches to explain model global predictions is the permutation importance where the performance on permuted data is benchmarked against the baseline. However, this method and other related approaches will undervalue the importance of a feature in the presence of covariates since these cover part of its provided information. To address this issue, we propose Covered Information Disentanglement (CID), a method that considers all feature information overlap to correct the values provided by permutation importance. We further show how to compute CID efficiently when coupled with Markov random fields. We demonstrate its efficacy in adjusting permutation importance first on a controlled toy dataset and discuss its effect on real-world medical data.
Interpretable Models via Pairwise permutations algorithm
Nov 17, 2021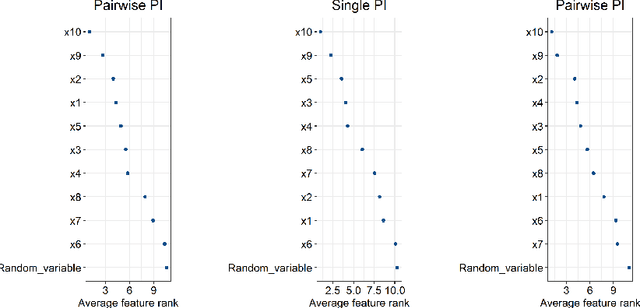
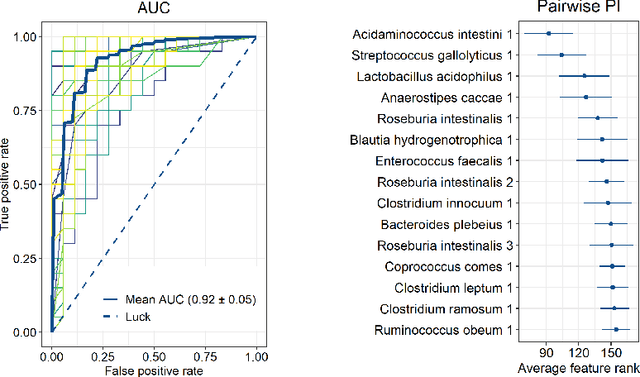
One of the most common pitfalls often found in high dimensional biological data sets are correlations between the features. This may lead to statistical and machine learning methodologies overvaluing or undervaluing these correlated predictors, while the truly relevant ones are ignored. In this paper, we will define a new method called \textit{pairwise permutation algorithm} (PPA) with the aim of mitigating the correlation bias in feature importance values. Firstly, we provide a theoretical foundation, which builds upon previous work on permutation importance. PPA is then applied to a toy data set, where we demonstrate its ability to correct the correlation effect. We further test PPA on a microbiome shotgun dataset, to show that the PPA is already able to obtain biological relevant biomarkers.
Graph Space Embedding
Jul 31, 2019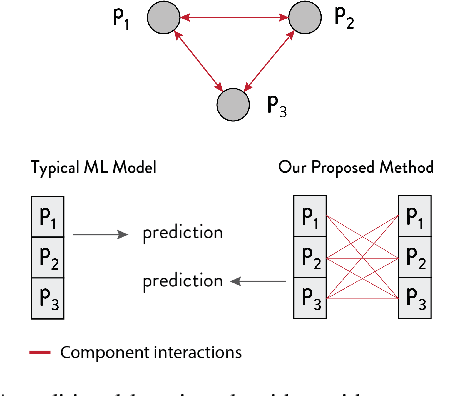
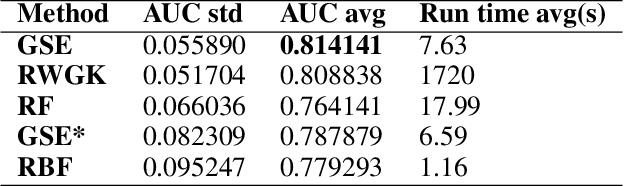
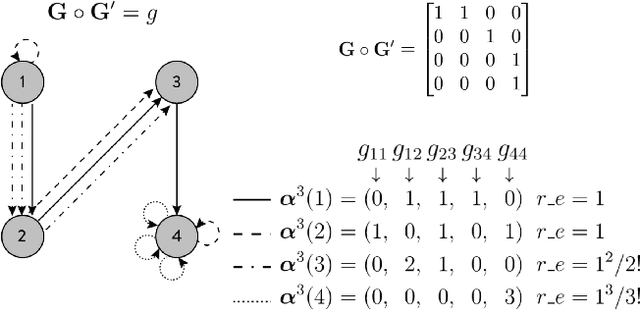
We propose the Graph Space Embedding (GSE), a technique that maps the input into a space where interactions are implicitly encoded, with little computations required. We provide theoretical results on an optimal regime for the GSE, namely a feasibility region for its parameters, and demonstrate the experimental relevance of our findings. Next, we introduce a strategy to gain insight on which interactions are responsible for the certain predictions, paving the way for a far more transparent model. In an empirical evaluation on a real-world clinical cohort containing patients with suspected coronary artery disease, the GSE achieves far better performance than traditional algorithms.