 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free ANN-to-SNN Conversion for High-Performance Spiking Transformer
Aug 11, 2025Leveraging the event-driven paradigm, Spiking Neural Networks (SNNs) offer a promising approach for constructing energy-efficient Transformer architectures. Compared to directly trained Spiking Transformers, ANN-to-SNN conversion methods bypass the high training costs. However, existing methods still suffer from notable limitations, failing to effectively handle nonlinear operations in Transformer architectures and requiring additional fine-tuning processes for pre-trained ANNs. To address these issues, we propose a high-performance and training-free ANN-to-SNN conversion framework tailored for Transformer architectures. Specifically, we introduce a Multi-basis Exponential Decay (MBE) neuron, which employs an exponential decay strategy and multi-basis encoding method to efficiently approximate various nonlinear operations. It removes the requirement for weight modifications in pre-trained ANNs. Extensive experiments across diverse tasks (CV, NLU, NLG) and mainstream Transformer architectures (ViT, RoBERTa, GPT-2) demonstrate that our method achieves near-lossless conversion accuracy with significantly lower latency. This provides a promising pathway for the efficient and scalable deployment of Spiking Transformers in real-world applications.
DIMT25@ICDAR2025: HW-TSC's End-to-End Document Image Machine Translation System Leveraging Large Vision-Language Model
Apr 24, 2025This paper presents the technical solution proposed by Huawei Translation Service Center (HW-TSC) for the "End-to-End Document Image Machine Translation for Complex Layouts" competition at the 19th International Conference on Document Analysis and Recognition (DIMT25@ICDAR2025). Leveraging state-of-the-art open-source large vision-language model (LVLM), we introduce a training framework that combines multi-task learning with perceptual chain-of-thought to develop a comprehensive end-to-end document translation system. During the inference phase, we apply minimum Bayesian decoding and post-processing strategies to further enhance the system's translation capabilities. Our solution uniquely addresses both OCR-based and OCR-free document image translation tasks within a unified framework. This paper systematically details the training methods, inference strategies, LVLM base models, training data, experimental setups, and results, demonstrating an effective approach to document image machine translation.
Evaluating Menu OCR and Translation: A Benchmark for Aligning Human and Automated Evaluations in Large Vision-Language Models
Apr 22, 2025The rapid advancement of large vision-language models (LVLMs) has significantly propelled applications in document understanding, particularly in optical character recognition (OCR) and multilingual translation. However, current evaluations of LVLMs, like the widely used OCRBench, mainly focus on verifying the correctness of their short-text responses and long-text responses with simple layout, while the evaluation of their ability to understand long texts with complex layout design is highly significant but largely overlooked. In this paper, we propose Menu OCR and Translation Benchmark (MOTBench), a specialized evaluation framework emphasizing the pivotal role of menu translation in cross-cultural communication. MOTBench requires LVLMs to accurately recognize and translate each dish, along with its price and unit items on a menu, providing a comprehensive assessment of their visual understanding and language processing capabilities. Our benchmark is comprised of a collection of Chinese and English menus, characterized by intricate layouts, a variety of fonts, and culturally specific elements across different languages, along with precise human annotations. Experiments show that our automatic evaluation results are highly consistent with professional human evaluation. We evaluate a range of publicly available state-of-the-art LVLMs, and through analyzing their output to identify the strengths and weaknesses in their performance, offering valuable insights to guide future advancements in LVLM development. MOTBench is available at https://github.com/gitwzl/MOTBench.
Multimodal Instruction Tuning with Hybrid State Space Models
Nov 13, 2024



Handling lengthy context is crucial for enhancing the recognition and understanding capabilities of multimodal large language models (MLLMs) in applications such as processing high-resolution images or high frame rate videos. The rise in image resolution and frame rate substantially increases computational demands due to the increased number of input tokens. This challenge is further exacerbated by the quadratic complexity with respect to sequence length of the self-attention mechanism. Most prior works either pre-train models with long contexts, overlooking the efficiency problem, or attempt to reduce the context length via downsampling (e.g., identify the key image patches or frames) to decrease the context length, which may result in information loss. To circumvent this issue while keeping the remarkable effectiveness of MLLMs, we propose a novel approach using a hybrid transformer-MAMBA model to efficiently handle long contexts in multimodal applications. Our multimodal model can effectively process long context input exceeding 100k tokens, outperforming existing models across various benchmarks. Remarkably, our model enhances inference efficiency for high-resolution images and high-frame-rate videos by about 4 times compared to current models, with efficiency gains increasing as image resolution or video frames rise. Furthermore, our model is the first to be trained on low-resolution images or low-frame-rate videos while being capable of inference on high-resolution images and high-frame-rate videos, offering flexibility for inference in diverse scenarios.
SVFit: Parameter-Efficient Fine-Tuning of Large Pre-Trained Models Using Singular Values
Sep 09, 2024

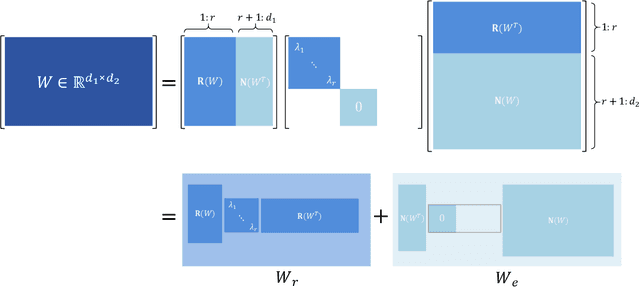

Large pre-trained models (LPMs) have demonstrated exceptional performance in diverse natural language processing and computer vision tasks. However, fully fine-tuning these models poses substantial memory challenges, particularly in resource-constrained environments. Parameter-efficient fine-tuning (PEFT) methods, such as LoRA, mitigate this issue by adjusting only a small subset of parameters. Nevertheless, these methods typically employ random initialization for low-rank matrices, which can lead to inefficiencies in gradient descent and diminished generalizability due to suboptimal starting points. To address these limitations, we propose SVFit, a novel PEFT approach that leverages singular value decomposition (SVD) to initialize low-rank matrices using critical singular values as trainable parameters. Specifically, SVFit performs SVD on the pre-trained weight matrix to obtain the best rank-r approximation matrix, emphasizing the most critical singular values that capture over 99% of the matrix's information. These top-r singular values are then used as trainable parameters to scale the fundamental subspaces of the matrix, facilitating rapid domain adaptation. Extensive experiments across various pre-trained models in natural language understanding, text-to-image generation, and image classification tasks reveal that SVFit outperforms LoRA while requiring 16 times fewer trainable parameters.
TLEX: An Efficient Method for Extracting Exact Timelines from TimeML Temporal Graphs
Jun 07, 2024



A timeline provides a total ordering of events and times, and is useful for a number of natural language understanding tasks. However, qualitative temporal graphs that can be derived directly from text -- such as TimeML annotations -- usually explicitly reveal only partial orderings of events and times. In this work, we apply prior work on solving point algebra problems to the task of extracting timelines from TimeML annotated texts, and develop an exact, end-to-end solution which we call TLEX (TimeLine EXtraction). TLEX transforms TimeML annotations into a collection of timelines arranged in a trunk-and-branch structure. Like what has been done in prior work, TLEX checks the consistency of the temporal graph and solves it; however, it adds two novel functionalities. First, it identifies specific relations involved in an inconsistency (which could then be manually corrected) and, second, TLEX performs a novel identification of sections of the timelines that have indeterminate order, information critical for downstream tasks such as aligning events from different timelines. We provide detailed descriptions and analysis of the algorithmic components in TLEX, and conduct experimental evaluations by applying TLEX to 385 TimeML annotated texts from four corpora. We show that 123 of the texts are inconsistent, 181 of them have more than one ``real world'' or main timeline, and there are 2,541 indeterminate sections across all four corpora. A sampling evaluation showed that TLEX is 98--100% accurate with 95% confidence along five dimensions: the ordering of time-points, the number of main timelines, the placement of time-points on main versus subordinate timelines, the connecting point of branch timelines, and the location of the indeterminate sections. We provide a reference implementation of TLEX, the extracted timelines for all texts, and the manual corrections of the inconsistent texts.
Collective Human Opinions in Semantic Textual Similarity
Aug 08, 2023Despite the subjective nature of semantic textual similarity (STS) and pervasive disagreements in STS annotation, existing benchmarks have used averaged human ratings as the gold standard. Averaging masks the true distribution of human opinions on examples of low agreement, and prevents models from capturing the semantic vagueness that the individual ratings represent. In this work, we introduce USTS, the first Uncertainty-aware STS dataset with ~15,000 Chinese sentence pairs and 150,000 labels, to study collective human opinions in STS. Analysis reveals that neither a scalar nor a single Gaussian fits a set of observed judgements adequately. We further show that current STS models cannot capture the variance caused by human disagreement on individual instances, but rather reflect the predictive confidence over the aggregate dataset.
* 16 pages, 7 figures
Instance-Variant Loss with Gaussian RBF Kernel for 3D Cross-modal Retriveal
May 07, 2023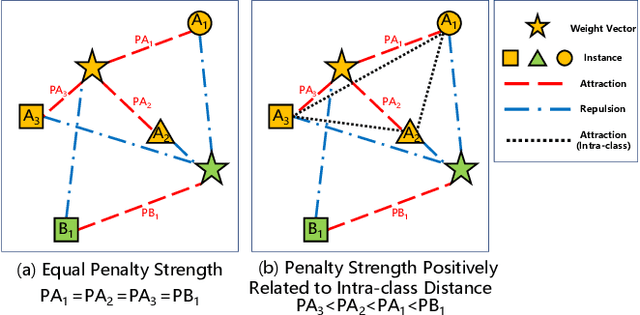
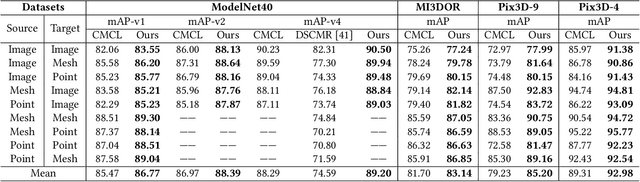
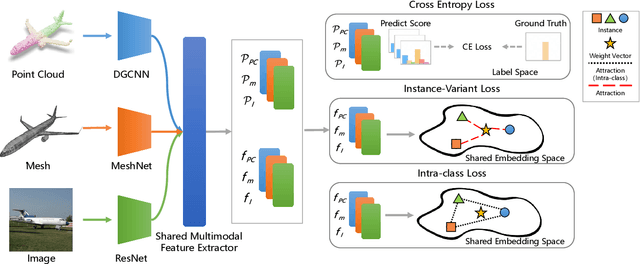
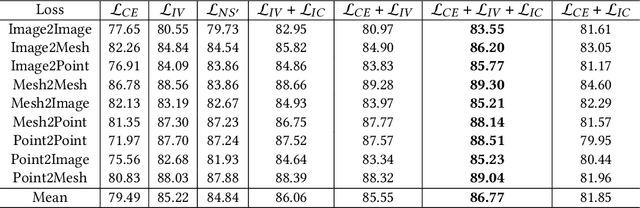
3D cross-modal retrieval is gaining attention in the multimedia community. Central to this topic is learning a joint embedding space to represent data from different modalities, such as images, 3D point clouds, and polygon meshes, to extract modality-invariant and discriminative features. Hence, the performance of cross-modal retrieval methods heavily depends on the representational capacity of this embedding space. Existing methods treat all instances equally, applying the same penalty strength to instances with varying degrees of difficulty, ignoring the differences between instances. This can result in ambiguous convergence or local optima, severely compromising the separability of the feature space. To address this limitation, we propose an Instance-Variant loss to assign different penalty strengths to different instances, improving the space separability. Specifically, we assign different penalty weights to instances positively related to their intra-class distance. Simultaneously, we reduce the cross-modal discrepancy between features by learning a shared weight vector for the same class data from different modalities. By leveraging the Gaussian RBF kernel to evaluate sample similarity, we further propose an Intra-Class loss function that minimizes the intra-class distance among same-class instances. Extensive experiments on three 3D cross-modal datasets show that our proposed method surpasses recent state-of-the-art approaches.
FederatedTrust: A Solution for Trustworthy Federated Learning
Feb 20, 2023With the ever-widening spread of the Internet of Things (IoT) and Edge Computing paradigms, centralized Machine and Deep Learning (ML/DL) have become challenging due to existing distributed data silos containing sensitive information. The rising concern for data privacy is promoting the development of collaborative and privacy-preserving ML/DL techniques such as Federated Learning (FL). FL enables data privacy by design since the local data of participants are not exposed during the creation of the global and collaborative model. However, data privacy and performance are no longer sufficient, and there is a real necessity to trust model predictions. The literature has proposed some works on trustworthy ML/DL (without data privacy), where robustness, fairness, explainability, and accountability are identified as relevant pillars. However, more efforts are needed to identify trustworthiness pillars and evaluation metrics relevant to FL models and to create solutions computing the trustworthiness level of FL models. Thus, this work analyzes the existing requirements for trustworthiness evaluation in FL and proposes a comprehensive taxonomy of six pillars (privacy, robustness, fairness, explainability, accountability, and federation) with notions and more than 30 metrics for computing the trustworthiness of FL models. Then, an algorithm called FederatedTrust has been designed according to the pillars and metrics identified in the previous taxonomy to compute the trustworthiness score of FL models. A prototype of FederatedTrust has been implemented and deployed into the learning process of FederatedScope, a well-known FL framework. Finally, four experiments performed with different configurations of FederatedScope using the FEMNIST dataset under different federation configurations demonstrated the usefulness of FederatedTrust when computing the trustworthiness of FL models.
Hardness of Maximum Likelihood Learning of DPPs
May 26, 2022
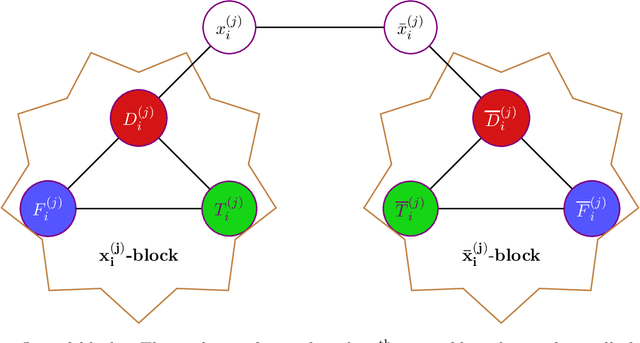

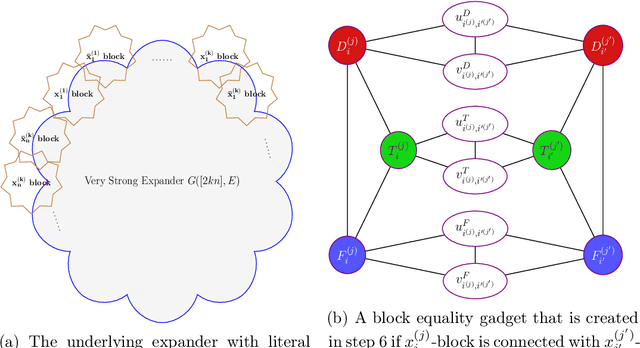
Determinantal Point Processes (DPPs) are a widely used probabilistic model for negatively correlated sets. DPPs have been successfully employed in Machine Learning applications to select a diverse, yet representative subset of data. In seminal work on DPPs in Machine Learning, Kulesza conjectured in his PhD Thesis (2011) that the problem of finding a maximum likelihood DPP model for a given data set is NP-complete. In this work we prove Kulesza's conjecture. In fact, we prove the following stronger hardness of approximation result: even computing a $\left(1-O(\frac{1}{\log^9{N}})\right)$-approximation to the maximum log-likelihood of a DPP on a ground set of $N$ elements is NP-complete. At the same time, we also obtain the first polynomial-time algorithm that achieves a nontrivial worst-case approximation to the optimal log-likelihood: the approximation factor is $\frac{1}{(1+o(1))\log{m}}$ unconditionally (for data sets that consist of $m$ subsets), and can be improved to $1-\frac{1+o(1)}{\log N}$ if all $N$ elements appear in a $O(1/N)$-fraction of the subsets. In terms of techniques, we reduce approximating the maximum log-likelihood of DPPs on a data set to solving a gap instance of a "vector coloring" problem on a hypergraph. Such a hypergraph is built on a bounded-degree graph construction of Bogdanov, Obata and Trevisan (FOCS 2002), and is further enhanced by the strong expanders of Alon and Capalbo (FOCS 2007) to serve our purposes.