 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoLDU: Low-Rank Adaptation via Lower-Diag-Upper Decomposition for Parameter-Efficient Fine-Tuning
Oct 17, 2024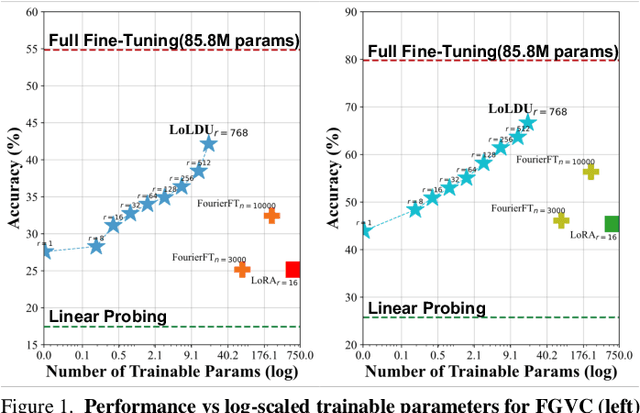
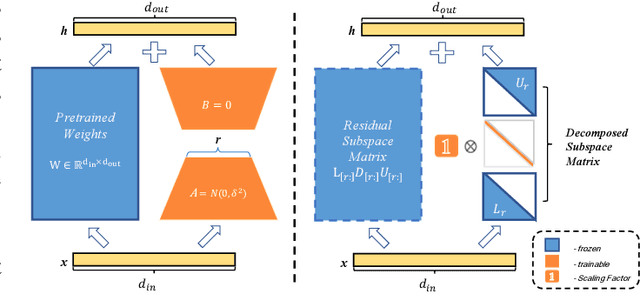
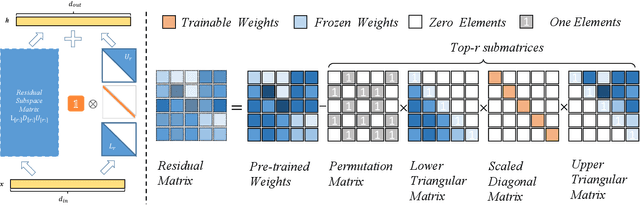
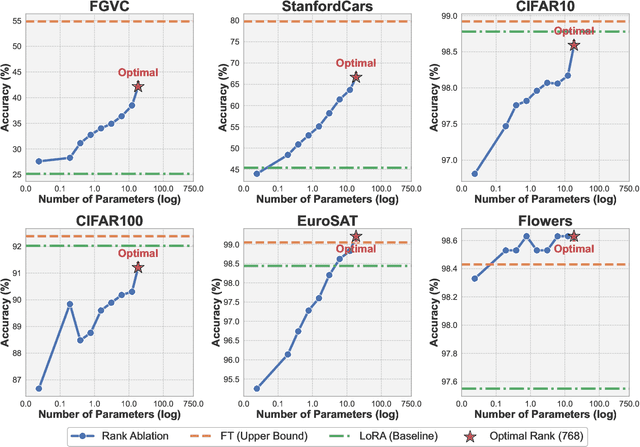
The rapid growth of model scale has necessitated substantial computational resources for fine-tuning. Existing approach such as Low-Rank Adaptation (LoRA) has sought to address the problem of handling the large updated parameters in full fine-tuning. However, LoRA utilize random initialization and optimization of low-rank matrices to approximate updated weights, which can result in suboptimal convergence and an accuracy gap compared to full fine-tuning. To address these issues, we propose LoLDU, a Parameter-Efficient Fine-Tuning (PEFT) approach that significantly reduces trainable parameters by 2600 times compared to regular PEFT methods while maintaining comparable performance. LoLDU leverages Lower-Diag-Upper Decomposition (LDU) to initialize low-rank matrices for faster convergence and orthogonality. We focus on optimizing the diagonal matrix for scaling transformations. To the best of our knowledge, LoLDU has the fewest parameters among all PEFT approaches. We conducted extensive experiments across 4 instruction-following datasets, 6 natural language understanding (NLU) datasets, 8 image classification datasets, and image generation datasets with multiple model types (LLaMA2, RoBERTa, ViT, and Stable Diffusion), providing a comprehensive and detailed analysis. Our open-source code can be accessed at \href{https://github.com/SKDDJ/LoLDU}{https://github.com/SKDDJ/LoLDU}.
SVFit: Parameter-Efficient Fine-Tuning of Large Pre-Trained Models Using Singular Values
Sep 09, 2024

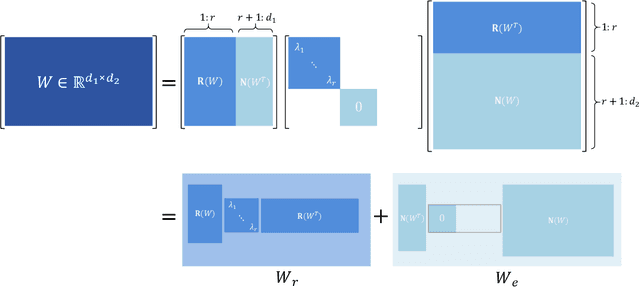

Large pre-trained models (LPMs) have demonstrated exceptional performance in diverse natural language processing and computer vision tasks. However, fully fine-tuning these models poses substantial memory challenges, particularly in resource-constrained environments. Parameter-efficient fine-tuning (PEFT) methods, such as LoRA, mitigate this issue by adjusting only a small subset of parameters. Nevertheless, these methods typically employ random initialization for low-rank matrices, which can lead to inefficiencies in gradient descent and diminished generalizability due to suboptimal starting points. To address these limitations, we propose SVFit, a novel PEFT approach that leverages singular value decomposition (SVD) to initialize low-rank matrices using critical singular values as trainable parameters. Specifically, SVFit performs SVD on the pre-trained weight matrix to obtain the best rank-r approximation matrix, emphasizing the most critical singular values that capture over 99% of the matrix's information. These top-r singular values are then used as trainable parameters to scale the fundamental subspaces of the matrix, facilitating rapid domain adaptation. Extensive experiments across various pre-trained models in natural language understanding, text-to-image generation, and image classification tasks reveal that SVFit outperforms LoRA while requiring 16 times fewer trainable parameters.
DiffLoRA: Generating Personalized Low-Rank Adaptation Weights with Diffusion
Aug 13, 2024

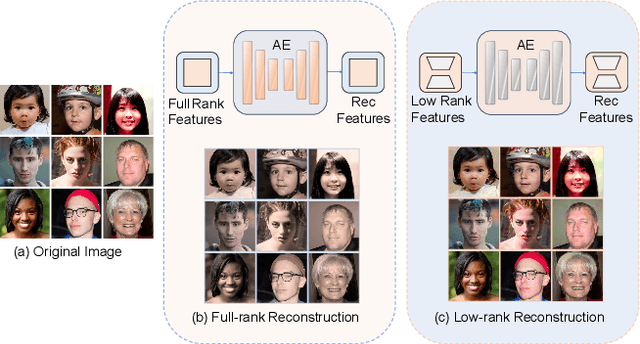
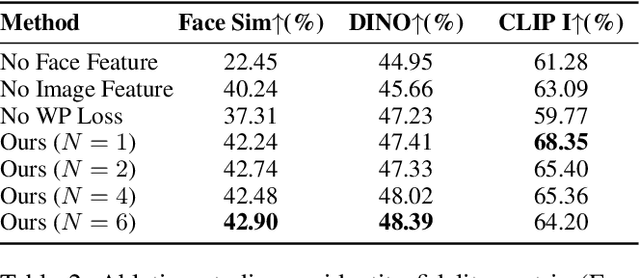
Personalized text-to-image generation has gained significant attention for its capability to generate high-fidelity portraits of specific identities conditioned on user-defined prompts. Existing methods typically involve test-time fine-tuning or instead incorporating an additional pre-trained branch. However, these approaches struggle to simultaneously address the demands of efficiency, identity fidelity, and preserving the model's original generative capabilities. In this paper, we propose DiffLoRA, a novel approach that leverages diffusion models as a hypernetwork to predict personalized low-rank adaptation (LoRA) weights based on the reference images. By integrating these LoRA weights into the text-to-image model, DiffLoRA achieves personalization during inference without further training. Additionally, we propose an identity-oriented LoRA weight construction pipeline to facilitate the training of DiffLoRA. By utilizing the dataset produced by this pipeline, our DiffLoRA consistently generates high-performance and accurate LoRA weights. Extensive evaluations demonstrate the effectiveness of our method, achieving both time efficiency and maintaining identity fidelity throughout the personalization process.