 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracing the Oracle: Improving Diffusion Timestep Scheduling for 3D CT Reconstruction
Jun 04, 2026Pretrained diffusion models demonstrate impressive potential in solving highly ill-posed 3D computed tomography (CT) inverse problems, while the inference process suffers from significant computational overhead. Furthermore, existing uniform timestep schedules fail to capture the non-uniform evolution of the reverse conditional diffusion stochastic differential equation, thereby introducing substantial truncation errors. To overcome this limitation, we propose Tracing the Oracle (TrO), a plug-and-play framework for improved timestep scheduling. Specifically, we treat densely sampled numerical integration trajectories on a few samples as the reference oracle. The optimized schedule is extracted by leveraging dynamic programming to globally minimize the cumulative error between the few-step approximation and the oracle. This mechanism precisely allocates the limited sampling steps to critical evolution stages that are highly susceptible to truncation errors. Our extensive experiments on the AAPM dataset across multiple 3D CT reconstruction tasks demonstrate that, when combined with the state-of-the-art 3D CT reconstruction method DDS, our optimized timesteps significantly improve reconstruction fidelity and computational efficiency compared to existing heuristic schedules, especially under a strict budget of no more than 10 sampling steps.
Qwen-Image-VAE-2.0 Technical Report
May 13, 2026We present Qwen-Image-VAE-2.0, a suite of high-compression Variational Autoencoders (VAEs) that achieve significant advances in both reconstruction fidelity and diffusability. To address the reconstruction bottlenecks of high compression, we adopt an improved architecture featuring Global Skip Connections (GSC) and expanded latent channels. Moreover, we scale training to billions of images and incorporate a synthetic rendering engine to improve performance in text-rich scenarios. To tackle the convergence challenges of high-dimensional latent space, we implement an enhanced semantic alignment strategy to make the latent space highly amenable to diffusion modeling. To optimize computational efficiency, we leverage an asymmetric and attention-free encoder-decoder backbone to minimize encoding overhead. We present a comprehensive evaluation of Qwen-Image-VAE-2.0 on public reconstruction benchmarks. To evaluate performance in text-rich scenarios, we propose OmniDoc-TokenBench, a new benchmark comprising a diverse collection of real-world documents coupled with specialized OCR-based evaluation metrics. Qwen-Image-VAE-2.0 achieves state-of-the-art reconstruction performance, demonstrating exceptional capabilities in both general domains and text-rich scenarios at high compression ratio. Furthermore, downstream DiT experiments reveal our models possess superior diffusability, significantly accelerating convergence compared to existing high-compression baselines. These establish Qwen-Image-VAE-2.0 as a leading model with high compression, superior reconstruction, and exceptional diffusability.
Qwen-Image-2.0 Technical Report
May 11, 2026We present Qwen-Image-2.0, an omni-capable image generation foundation model that unifies high-fidelity generation and precise image editing within a single framework. Despite recent progress, existing models still struggle with ultra-long text rendering, multilingual typography, high-resolution photorealism, robust instruction following, and efficient deployment, especially in text-rich and compositionally complex scenarios. Qwen-Image-2.0 addresses these challenges by coupling Qwen3-VL as the condition encoder with a Multimodal Diffusion Transformer for joint condition-target modeling, supported by large-scale data curation and a customized multi-stage training pipeline. This enables strong multimodal understanding while preserving flexible generation and editing capabilities. The model supports instructions of up to 1K tokens for generating text-rich content such as slides, posters, infographics, and comics, while significantly improving multilingual text fidelity and typography. It also enhances photorealistic generation with richer details, more realistic textures, and coherent lighting, and follows complex prompts more reliably across diverse styles. Extensive human evaluations show that Qwen-Image-2.0 substantially outperforms previous Qwen-Image models in both generation and editing, marking a step toward more general, reliable, and practical image generation foundation models.
DiffSOS: Acoustic Conditional Diffusion Model for Speed-of-Sound Reconstruction in Ultrasound Computed Tomography
Feb 27, 2026Accurate Speed-of-Sound (SoS) reconstruction from acoustic waveforms is a cornerstone of ultrasound computed tomography (USCT), enabling quantitative velocity mapping that reveals subtle anatomical details and pathological variations often invisible in conventional imaging. However, practical utility is hindered by the limitations of existing algorithms; traditional Full Waveform Inversion (FWI) is computationally intensive, while current deep learning approaches tend to produce oversmoothed results lacking fine details. We propose DiffSOS, a conditional diffusion model that directly maps acoustic waveforms to SoS maps. Our framework employs a specialized acoustic ControlNet to strictly ground the denoising process in physical wave measurements. To ensure structural consistency, we optimize a hybrid loss function that integrates noise prediction, spatial reconstruction, and noise frequency content. To accelerate inference, we employ stochastic Denoising Diffusion Implicit Model (DDIM) sampling, achieving near real-time reconstruction with only 10 steps. Crucially, we exploit the stochastic generative nature of our framework to estimate pixel-wise uncertainty, providing a measure of reliability that is often absent in deterministic approaches. Evaluated on the OpenPros USCT benchmark, DiffSOS significantly outperforms state-of-the-art networks, achieving an average Multi-scale Structural Similarity of 0.957. Our approach provides high-fidelity SoS maps with a principled measure of confidence, facilitating safer and faster clinical interpretation.
IRSDE-Despeckle: A Physics-Grounded Diffusion Model for Generalizable Ultrasound Despeckling
Feb 26, 2026Ultrasound imaging is widely used for real-time, noninvasive diagnosis, but speckle and related artifacts reduce image quality and can hinder interpretation. We present a diffusion-based ultrasound despeckling method built on the Image Restoration Stochastic Differential Equations framework. To enable supervised training, we curate large paired datasets by simulating ultrasound images from speckle-free magnetic resonance images using the Matlab UltraSound Toolbox. The proposed model reconstructs speckle-suppressed images while preserving anatomically meaningful edges and contrast. On a held-out simulated test set, our approach consistently outperforms classical filters and recent learning-based despeckling baselines. We quantify prediction uncertainty via cross-model variance and show that higher uncertainty correlates with higher reconstruction error, providing a practical indicator of difficult or failure-prone regions. Finally, we evaluate sensitivity to simulation probe settings and observe domain shift, motivating diversified training and adaptation for robust clinical deployment.
Deep Learning-Driven Quantitative Spectroscopic Photoacoustic Imaging for Segmentation and Oxygen Saturation Estimation
Dec 17, 2025Spectroscopic photoacoustic (sPA) imaging can potentially estimate blood oxygenation saturation (sO2) in vivo noninvasively. However, quantitatively accurate results require accurate optical fluence estimates. Robust modeling in heterogeneous tissue, where light with different wavelengths can experience significantly different absorption and scattering, is difficult. In this work, we developed a deep neural network (Hybrid-Net) for sPA imaging to simultaneously estimate sO2 in blood vessels and segment those vessels from surrounding background tissue. sO2 error was minimized only in blood vessels segmented in Hybrid-Net, resulting in more accurate predictions. Hybrid-Net was first trained on simulated sPA data (at 700 nm and 850 nm) representing initial pressure distributions from three-dimensional Monte Carlo simulations of light transport in breast tissue. Then, for experimental verification, the network was retrained on experimental sPA data (at 700 nm and 850 nm) acquired from simple tissue mimicking phantoms with an embedded blood pool. Quantitative measures were used to evaluate Hybrid-Net performance with an averaged segmentation accuracy of >= 0.978 in simulations with varying noise levels (0dB-35dB) and 0.998 in the experiment, and an averaged sO2 mean squared error of <= 0.048 in simulations with varying noise levels (0dB-35dB) and 0.003 in the experiment. Overall, these results show that Hybrid-Net can provide accurate blood oxygenation without estimating the optical fluence, and this study could lead to improvements in in-vivo sO2 estimation.
Vision-G1: Towards General Vision Language Reasoning with Multi-Domain Data Curation
Aug 18, 2025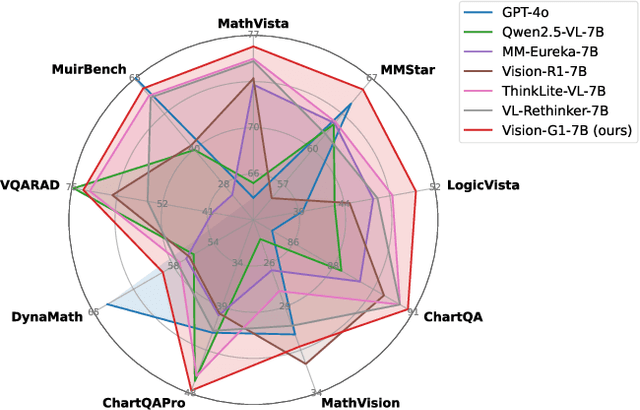
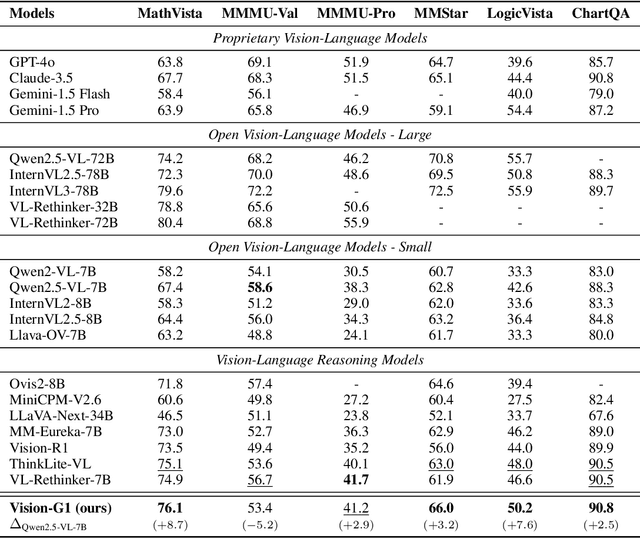
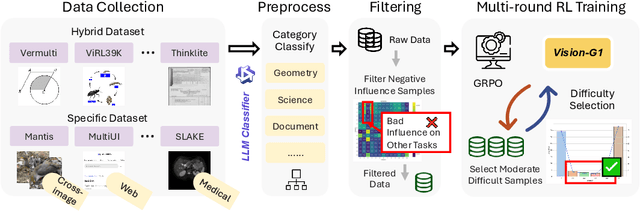
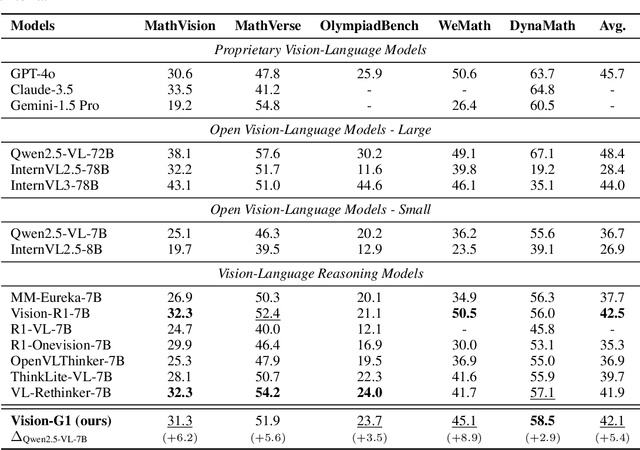
Despite their success, current training pipelines for reasoning VLMs focus on a limited range of tasks, such as mathematical and logical reasoning. As a result, these models face difficulties in generalizing their reasoning capabilities to a wide range of domains, primarily due to the scarcity of readily available and verifiable reward data beyond these narrowly defined areas. Moreover, integrating data from multiple domains is challenging, as the compatibility between domain-specific datasets remains uncertain. To address these limitations, we build a comprehensive RL-ready visual reasoning dataset from 46 data sources across 8 dimensions, covering a wide range of tasks such as infographic, mathematical, spatial, cross-image, graphic user interface, medical, common sense and general science. We propose an influence function based data selection and difficulty based filtering strategy to identify high-quality training samples from this dataset. Subsequently, we train the VLM, referred to as Vision-G1, using multi-round RL with a data curriculum to iteratively improve its visual reasoning capabilities. Our model achieves state-of-the-art performance across various visual reasoning benchmarks, outperforming similar-sized VLMs and even proprietary models like GPT-4o and Gemini-1.5 Flash. The model, code and dataset are publicly available at https://github.com/yuh-zha/Vision-G1.
On Path to Multimodal Historical Reasoning: HistBench and HistAgent
May 26, 2025Recent advances in large language models (LLMs) have led to remarkable progress across domains, yet their capabilities in the humanities, particularly history, remain underexplored. Historical reasoning poses unique challenges for AI, involving multimodal source interpretation, temporal inference, and cross-linguistic analysis. While general-purpose agents perform well on many existing benchmarks, they lack the domain-specific expertise required to engage with historical materials and questions. To address this gap, we introduce HistBench, a new benchmark of 414 high-quality questions designed to evaluate AI's capacity for historical reasoning and authored by more than 40 expert contributors. The tasks span a wide range of historical problems-from factual retrieval based on primary sources to interpretive analysis of manuscripts and images, to interdisciplinary challenges involving archaeology, linguistics, or cultural history. Furthermore, the benchmark dataset spans 29 ancient and modern languages and covers a wide range of historical periods and world regions. Finding the poor performance of LLMs and other agents on HistBench, we further present HistAgent, a history-specific agent equipped with carefully designed tools for OCR, translation, archival search, and image understanding in History. On HistBench, HistAgent based on GPT-4o achieves an accuracy of 27.54% pass@1 and 36.47% pass@2, significantly outperforming LLMs with online search and generalist agents, including GPT-4o (18.60%), DeepSeek-R1(14.49%) and Open Deep Research-smolagents(20.29% pass@1 and 25.12% pass@2). These results highlight the limitations of existing LLMs and generalist agents and demonstrate the advantages of HistAgent for historical reasoning.
Precise Facial Landmark Detection by Dynamic Semantic Aggregation Transformer
Dec 01, 2024



At present, deep neural network methods have played a dominant role in face alignment field. However, they generally use predefined network structures to predict landmarks, which tends to learn general features and leads to mediocre performance, e.g., they perform well on neutral samples but struggle with faces exhibiting large poses or occlusions. Moreover, they cannot effectively deal with semantic gaps and ambiguities among features at different scales, which may hinder them from learning efficient features. To address the above issues, in this paper, we propose a Dynamic Semantic-Aggregation Transformer (DSAT) for more discriminative and representative feature (i.e., specialized feature) learning. Specifically, a Dynamic Semantic-Aware (DSA) model is first proposed to partition samples into subsets and activate the specific pathways for them by estimating the semantic correlations of feature channels, making it possible to learn specialized features from each subset. Then, a novel Dynamic Semantic Specialization (DSS) model is designed to mine the homogeneous information from features at different scales for eliminating the semantic gap and ambiguities and enhancing the representation ability. Finally, by integrating the DSA model and DSS model into our proposed DSAT in both dynamic architecture and dynamic parameter manners, more specialized features can be learned for achieving more precise face alignment. It is interesting to show that harder samples can be handled by activating more feature channels. Extensive experiments on popular face alignment datasets demonstrate that our proposed DSAT outperforms state-of-the-art models in the literature.Our code is available at https://github.com/GERMINO-LiuHe/DSAT.
Tensor-Fused Multi-View Graph Contrastive Learning
Oct 20, 2024



Graph contrastive learning (GCL) has emerged as a promising approach to enhance graph neural networks' (GNNs) ability to learn rich representations from unlabeled graph-structured data. However, current GCL models face challenges with computational demands and limited feature utilization, often relying only on basic graph properties like node degrees and edge attributes. This constrains their capacity to fully capture the complex topological characteristics of real-world phenomena represented by graphs. To address these limitations, we propose Tensor-Fused Multi-View Graph Contrastive Learning (TensorMV-GCL), a novel framework that integrates extended persistent homology (EPH) with GCL representations and facilitates multi-scale feature extraction. Our approach uniquely employs tensor aggregation and compression to fuse information from graph and topological features obtained from multiple augmented views of the same graph. By incorporating tensor concatenation and contraction modules, we reduce computational overhead by separating feature tensor aggregation and transformation. Furthermore, we enhance the quality of learned topological features and model robustness through noise-injected EPH. Experiments on molecular, bioinformatic, and social network datasets demonstrate TensorMV-GCL's superiority, outperforming 15 state-of-the-art methods in graph classification tasks across 9 out of 11 benchmarks while achieving comparable results on the remaining two. The code for this paper is publicly available at https://github.com/CS-SAIL/Tensor-MV-GCL.git.