 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: The Inevitable End of One-Architecture-Fits-All-Domains in Time Series Forecasting
Feb 02, 2026Recent work has questioned the effectiveness and robustness of neural network architectures for time series forecasting tasks. We summarize these concerns and analyze groundly their inherent limitations: i.e. the irreconcilable conflict between single (or few similar) domains SOTA and generalizability over general domains for time series forecasting neural network architecture designs. Moreover, neural networks architectures for general domain time series forecasting are becoming more and more complicated and their performance has almost saturated in recent years. As a result, network architectures developed aiming at fitting general time series domains are almost not inspiring for real world practices for certain single (or few similar) domains such as Finance, Weather, Traffic, etc: each specific domain develops their own methods that rarely utilize advances in neural network architectures of time series community in recent 2-3 years. As a result, we call for the time series community to shift focus away from research on time series neural network architectures for general domains: these researches have become saturated and away from domain-specific SOTAs over time. We should either (1) focus on deep learning methods for certain specific domain(s), or (2) turn to the development of meta-learning methods for general domains.
CubeBench: Diagnosing Interactive, Long-Horizon Spatial Reasoning Under Partial Observations
Dec 30, 2025Large Language Model (LLM) agents, while proficient in the digital realm, face a significant gap in physical-world deployment due to the challenge of forming and maintaining a robust spatial mental model. We identify three core cognitive challenges hindering this transition: spatial reasoning, long-horizon state tracking via mental simulation, and active exploration under partial observation. To isolate and evaluate these faculties, we introduce CubeBench, a novel generative benchmark centered on the Rubik's Cube. CubeBench uses a three-tiered diagnostic framework that progressively assesses agent capabilities, from foundational state tracking with full symbolic information to active exploration with only partial visual data. Our experiments on leading LLMs reveal critical limitations, including a uniform 0.00% pass rate on all long-horizon tasks, exposing a fundamental failure in long-term planning. We also propose a diagnostic framework to isolate these cognitive bottlenecks by providing external solver tools. By analyzing the failure modes, we provide key insights to guide the development of more physically-grounded intelligent agents.
GenEnv: Difficulty-Aligned Co-Evolution Between LLM Agents and Environment Simulators
Dec 23, 2025Training capable Large Language Model (LLM) agents is critically bottlenecked by the high cost and static nature of real-world interaction data. We address this by introducing GenEnv, a framework that establishes a difficulty-aligned co-evolutionary game between an agent and a scalable, generative environment simulator. Unlike traditional methods that evolve models on static datasets, GenEnv instantiates a dataevolving: the simulator acts as a dynamic curriculum policy, continuously generating tasks specifically tailored to the agent's ``zone of proximal development''. This process is guided by a simple but effective $α$-Curriculum Reward, which aligns task difficulty with the agent's current capabilities. We evaluate GenEnv on five benchmarks, including API-Bank, ALFWorld, BFCL, Bamboogle, and TravelPlanner. Across these tasks, GenEnv improves agent performance by up to \textbf{+40.3\%} over 7B baselines and matches or exceeds the average performance of larger models. Compared to Gemini 2.5 Pro-based offline data augmentation, GenEnv achieves better performance while using 3.3$\times$ less data. By shifting from static supervision to adaptive simulation, GenEnv provides a data-efficient pathway for scaling agent capabilities.
From Word to World: Can Large Language Models be Implicit Text-based World Models?
Dec 21, 2025Agentic reinforcement learning increasingly relies on experience-driven scaling, yet real-world environments remain non-adaptive, limited in coverage, and difficult to scale. World models offer a potential way to improve learning efficiency through simulated experience, but it remains unclear whether large language models can reliably serve this role and under what conditions they meaningfully benefit agents. We study these questions in text-based environments, which provide a controlled setting to reinterpret language modeling as next-state prediction under interaction. We introduce a three-level framework for evaluating LLM-based world models: (i) fidelity and consistency, (ii) scalability and robustness, and (iii) agent utility. Across five representative environments, we find that sufficiently trained world models maintain coherent latent state, scale predictably with data and model size, and improve agent performance via action verification, synthetic trajectory generation, and warm-starting reinforcement learning. Meanwhile, these gains depend critically on behavioral coverage and environment complexity, delineating clear boundry on when world modeling effectively supports agent learning.
A Survey of Self-Evolving Agents: On Path to Artificial Super Intelligence
Jul 28, 2025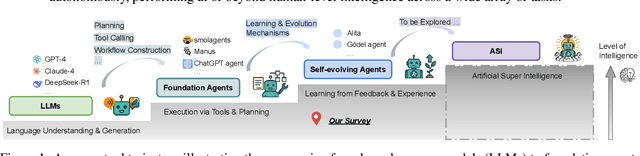

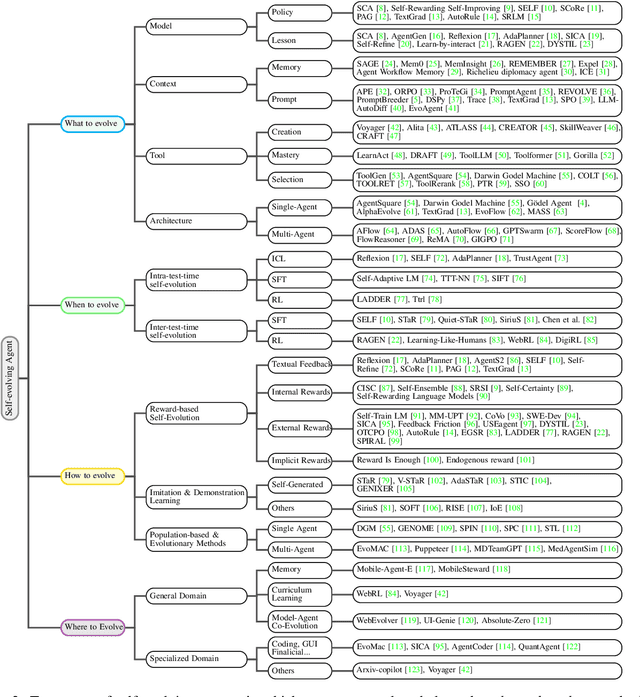
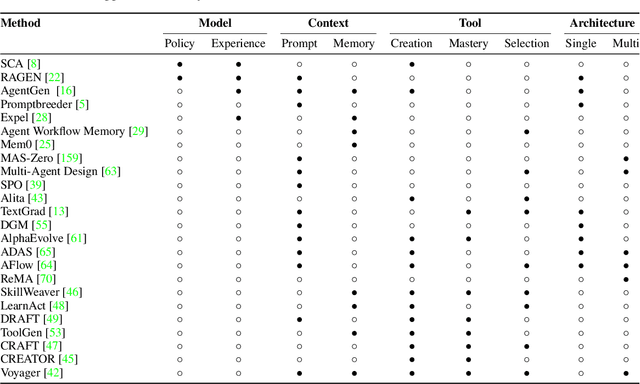
Large Language Models (LLMs) have demonstrated strong capabilities but remain fundamentally static, unable to adapt their internal parameters to novel tasks, evolving knowledge domains, or dynamic interaction contexts. As LLMs are increasingly deployed in open-ended, interactive environments, this static nature has become a critical bottleneck, necessitating agents that can adaptively reason, act, and evolve in real time. This paradigm shift -- from scaling static models to developing self-evolving agents -- has sparked growing interest in architectures and methods enabling continual learning and adaptation from data, interactions, and experiences. This survey provides the first systematic and comprehensive review of self-evolving agents, organized around three foundational dimensions -- what to evolve, when to evolve, and how to evolve. We examine evolutionary mechanisms across agent components (e.g., models, memory, tools, architecture), categorize adaptation methods by stages (e.g., intra-test-time, inter-test-time), and analyze the algorithmic and architectural designs that guide evolutionary adaptation (e.g., scalar rewards, textual feedback, single-agent and multi-agent systems). Additionally, we analyze evaluation metrics and benchmarks tailored for self-evolving agents, highlight applications in domains such as coding, education, and healthcare, and identify critical challenges and research directions in safety, scalability, and co-evolutionary dynamics. By providing a structured framework for understanding and designing self-evolving agents, this survey establishes a roadmap for advancing adaptive agentic systems in both research and real-world deployments, ultimately shedding lights to pave the way for the realization of Artificial Super Intelligence (ASI), where agents evolve autonomously, performing at or beyond human-level intelligence across a wide array of tasks.
ReasonFlux-PRM: Trajectory-Aware PRMs for Long Chain-of-Thought Reasoning in LLMs
Jun 23, 2025



Process Reward Models (PRMs) have recently emerged as a powerful framework for supervising intermediate reasoning steps in large language models (LLMs). Previous PRMs are primarily trained on model final output responses and struggle to evaluate intermediate thinking trajectories robustly, especially in the emerging setting of trajectory-response outputs generated by frontier reasoning models like Deepseek-R1. In this work, we introduce ReasonFlux-PRM, a novel trajectory-aware PRM explicitly designed to evaluate the trajectory-response type of reasoning traces. ReasonFlux-PRM incorporates both step-level and trajectory-level supervision, enabling fine-grained reward assignment aligned with structured chain-of-thought data. We adapt ReasonFlux-PRM to support reward supervision under both offline and online settings, including (i) selecting high-quality model distillation data for downstream supervised fine-tuning of smaller models, (ii) providing dense process-level rewards for policy optimization during reinforcement learning, and (iii) enabling reward-guided Best-of-N test-time scaling. Empirical results on challenging downstream benchmarks such as AIME, MATH500, and GPQA-Diamond demonstrate that ReasonFlux-PRM-7B selects higher quality data than strong PRMs (e.g., Qwen2.5-Math-PRM-72B) and human-curated baselines. Furthermore, our derived ReasonFlux-PRM-7B yields consistent performance improvements, achieving average gains of 12.1% in supervised fine-tuning, 4.5% in reinforcement learning, and 6.3% in test-time scaling. We also release our efficient ReasonFlux-PRM-1.5B for resource-constrained applications and edge deployment. Projects: https://github.com/Gen-Verse/ReasonFlux
AgentDistill: Training-Free Agent Distillation with Generalizable MCP Boxes
Jun 17, 2025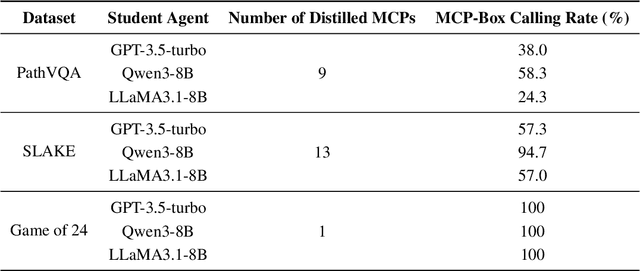
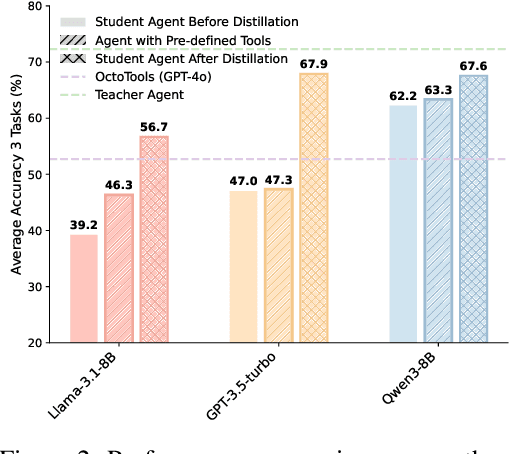
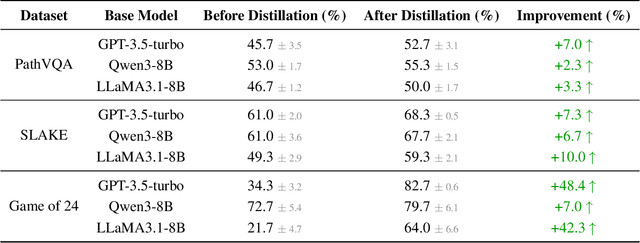
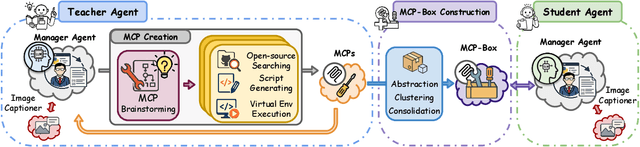
While knowledge distillation has become a mature field for compressing large language models (LLMs) into smaller ones by aligning their outputs or internal representations, the distillation of LLM-based agents, which involve planning, memory, and tool use, remains relatively underexplored. Existing agent distillation methods typically replay full teacher trajectories or imitate step-by-step teacher tool usage, but they often struggle to train student agents to dynamically plan and act in novel environments. We propose AgentDistill, a novel, training-free agent distillation framework that enables efficient and scalable knowledge transfer via direct reuse of Model-Context-Protocols (MCPs), which are structured and reusable task-solving modules autonomously generated by teacher agents. The reuse of these distilled MCPs enables student agents to generalize their capabilities across domains and solve new problems with minimal supervision or human intervention. Experiments on biomedical and mathematical benchmarks demonstrate that our distilled student agents, built on small language models, can achieve performance comparable to advanced systems using large LLMs such as OctoTools (GPT-4o), highlighting the effectiveness of our framework in building scalable and cost-efficient intelligent agents.
Alita: Generalist Agent Enabling Scalable Agentic Reasoning with Minimal Predefinition and Maximal Self-Evolution
May 26, 2025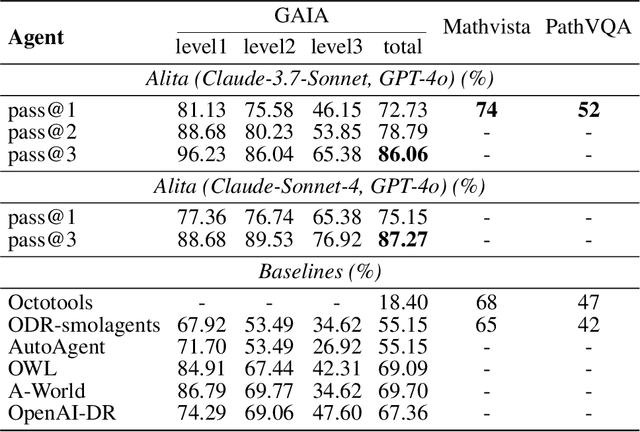
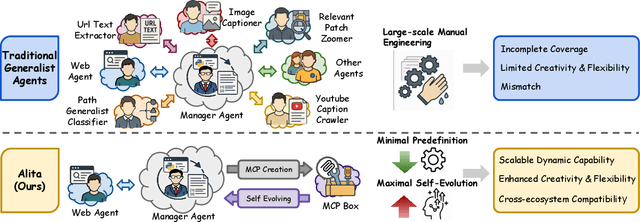
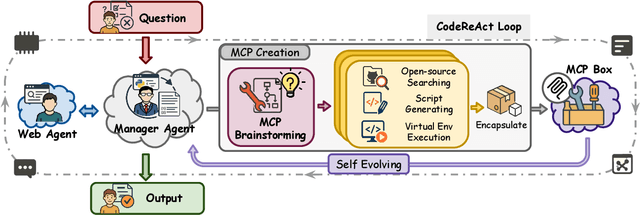

Recent advances in large language models (LLMs) have enabled agents to autonomously perform complex, open-ended tasks. However, many existing frameworks depend heavily on manually predefined tools and workflows, which hinder their adaptability, scalability, and generalization across domains. In this work, we introduce Alita--a generalist agent designed with the principle of "Simplicity is the ultimate sophistication," enabling scalable agentic reasoning through minimal predefinition and maximal self-evolution. For minimal predefinition, Alita is equipped with only one component for direct problem-solving, making it much simpler and neater than previous approaches that relied heavily on hand-crafted, elaborate tools and workflows. This clean design enhances its potential to generalize to challenging questions, without being limited by tools. For Maximal self-evolution, we enable the creativity of Alita by providing a suite of general-purpose components to autonomously construct, refine, and reuse external capabilities by generating task-related model context protocols (MCPs) from open source, which contributes to scalable agentic reasoning. Notably, Alita achieves 75.15% pass@1 and 87.27% pass@3 accuracy, which is top-ranking among general-purpose agents, on the GAIA benchmark validation dataset, 74.00% and 52.00% pass@1, respectively, on Mathvista and PathVQA, outperforming many agent systems with far greater complexity. More details will be updated at $\href{https://github.com/CharlesQ9/Alita}{https://github.com/CharlesQ9/Alita}$.
On Path to Multimodal Historical Reasoning: HistBench and HistAgent
May 26, 2025Recent advances in large language models (LLMs) have led to remarkable progress across domains, yet their capabilities in the humanities, particularly history, remain underexplored. Historical reasoning poses unique challenges for AI, involving multimodal source interpretation, temporal inference, and cross-linguistic analysis. While general-purpose agents perform well on many existing benchmarks, they lack the domain-specific expertise required to engage with historical materials and questions. To address this gap, we introduce HistBench, a new benchmark of 414 high-quality questions designed to evaluate AI's capacity for historical reasoning and authored by more than 40 expert contributors. The tasks span a wide range of historical problems-from factual retrieval based on primary sources to interpretive analysis of manuscripts and images, to interdisciplinary challenges involving archaeology, linguistics, or cultural history. Furthermore, the benchmark dataset spans 29 ancient and modern languages and covers a wide range of historical periods and world regions. Finding the poor performance of LLMs and other agents on HistBench, we further present HistAgent, a history-specific agent equipped with carefully designed tools for OCR, translation, archival search, and image understanding in History. On HistBench, HistAgent based on GPT-4o achieves an accuracy of 27.54% pass@1 and 36.47% pass@2, significantly outperforming LLMs with online search and generalist agents, including GPT-4o (18.60%), DeepSeek-R1(14.49%) and Open Deep Research-smolagents(20.29% pass@1 and 25.12% pass@2). These results highlight the limitations of existing LLMs and generalist agents and demonstrate the advantages of HistAgent for historical reasoning.
Shallow Preference Signals: Large Language Model Aligns Even Better with Truncated Data?
May 21, 2025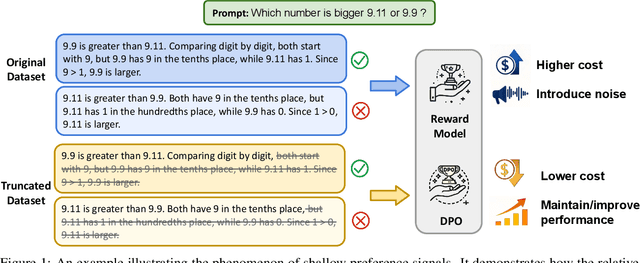
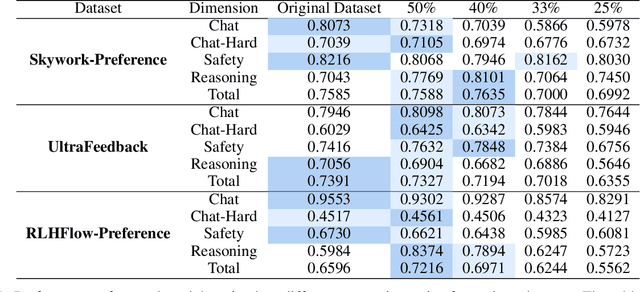
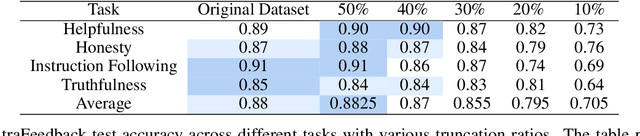
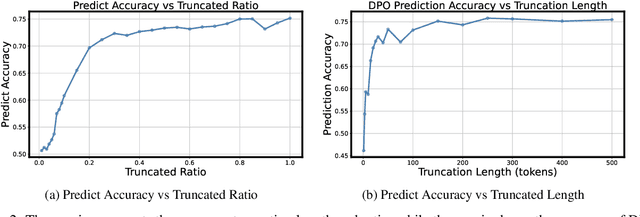
Aligning large language models (LLMs) with human preferences remains a key challenge in AI. Preference-based optimization methods, such as Reinforcement Learning with Human Feedback (RLHF) and Direct Preference Optimization (DPO), rely on human-annotated datasets to improve alignment. In this work, we identify a crucial property of the existing learning method: the distinguishing signal obtained in preferred responses is often concentrated in the early tokens. We refer to this as shallow preference signals. To explore this property, we systematically truncate preference datasets at various points and train both reward models and DPO models on the truncated data. Surprisingly, models trained on truncated datasets, retaining only the first half or fewer tokens, achieve comparable or even superior performance to those trained on full datasets. For example, a reward model trained on the Skywork-Reward-Preference-80K-v0.2 dataset outperforms the full dataset when trained on a 40\% truncated dataset. This pattern is consistent across multiple datasets, suggesting the widespread presence of shallow preference signals. We further investigate the distribution of the reward signal through decoding strategies. We consider two simple decoding strategies motivated by the shallow reward signal observation, namely Length Control Decoding and KL Threshold Control Decoding, which leverage shallow preference signals to optimize the trade-off between alignment and computational efficiency. The performance is even better, which again validates our hypothesis. The phenomenon of shallow preference signals highlights potential issues in LLM alignment: existing alignment methods often focus on aligning only the initial tokens of responses, rather than considering the full response. This could lead to discrepancies with real-world human preferences, resulting in suboptimal alignment performance.