 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Deep Neural Network Reliability with Refinement and Calibration
May 22, 2026Although deep neural networks (DNNs) achieve high predictive accuracy, their confidence estimates are often unreliable, potentially compromising user trust in their decisions. This has motivated research on calibrated models, where calibration measures how well a model's predicted confidence aligns with the empirical probability of correctness. However, calibration metrics can often be improved through post-processing techniques that merely mimic training-time uncertainty without genuinely improving the model's understanding. For this reason, statisticians recommend that models be not only calibrated but also refined. Intuitively, a model is considered more refined if it assigns significantly different confidence scores to correct and incorrect predictions, a property also referred to as sharpness. We observe that many existing calibration methods improve calibration at the cost of reduced refinement. To address this limitation, we propose: (1) a novel loss function that explicitly promotes refinement and can be optimized through supervised contrastive learning; and (2) a unified training framework, RefCal, that jointly optimizes calibration, refinement, and accuracy to improve DNN reliability. On the CIFAR-100-LT dataset with 10 percent class imbalance, RefCal achieves (accuracy, refinement, ECE) of (58.81, 95.67, 0.08), substantially outperforming the widely used Correctness Ranking Loss, which achieves (46.27, 93.7, 0.22).
VisRef: Visual Refocusing while Thinking Improves Test-Time Scaling in Multi-Modal Large Reasoning Models
Feb 27, 2026Advances in large reasoning models have shown strong performance on complex reasoning tasks by scaling test-time compute through extended reasoning. However, recent studies observe that in vision-dependent tasks, extended textual reasoning at inference time can degrade performance as models progressively lose attention to visual tokens and increasingly rely on textual priors alone. To address this, prior works use reinforcement learning (RL)-based fine-tuning to route visual tokens or employ refocusing mechanisms during reasoning. While effective, these methods are computationally expensive, requiring large-scale data generation and policy optimization. To leverage the benefits of test-time compute without additional RL fine-tuning, we propose VisRef, a visually grounded test-time scaling framework. Our key idea is to actively guide the reasoning process by re-injecting a coreset of visual tokens that are semantically relevant to the reasoning context while remaining diverse and globally representative of the image, enabling more grounded multi-modal reasoning. Experiments on three visual reasoning benchmarks with state-of-the-art multi-modal large reasoning models demonstrate that, under fixed test-time compute budgets, VisRef consistently outperforms existing test-time scaling approaches by up to 6.4%.
Safety Recovery in Reasoning Models Is Only a Few Early Steering Steps Away
Feb 11, 2026Reinforcement learning (RL) based post-training for explicit chain-of-thought (e.g., GRPO) improves the reasoning ability of multimodal large-scale reasoning models (MLRMs). But recent evidence shows that it can simultaneously degrade safety alignment and increase jailbreak success rates. We propose SafeThink, a lightweight inference-time defense that treats safety recovery as a satisficing constraint rather than a maximization objective. SafeThink monitors the evolving reasoning trace with a safety reward model and conditionally injects an optimized short corrective prefix ("Wait, think safely") only when the safety threshold is violated. In our evaluations across six open-source MLRMs and four jailbreak benchmarks (JailbreakV-28K, Hades, FigStep, and MM-SafetyBench), SafeThink reduces attack success rates by 30-60% (e.g., LlamaV-o1: 63.33% to 5.74% on JailbreakV-28K, R1-Onevision: 69.07% to 5.65% on Hades) while preserving reasoning performance (MathVista accuracy: 65.20% to 65.00%). A key empirical finding from our experiments is that safety recovery is often only a few steering steps away: intervening in the first 1-3 reasoning steps typically suffices to redirect the full generation toward safe completions.
KITE: Kernelized and Information Theoretic Exemplars for In-Context Learning
Sep 19, 2025In-context learning (ICL) has emerged as a powerful paradigm for adapting large language models (LLMs) to new and data-scarce tasks using only a few carefully selected task-specific examples presented in the prompt. However, given the limited context size of LLMs, a fundamental question arises: Which examples should be selected to maximize performance on a given user query? While nearest-neighbor-based methods like KATE have been widely adopted for this purpose, they suffer from well-known drawbacks in high-dimensional embedding spaces, including poor generalization and a lack of diversity. In this work, we study this problem of example selection in ICL from a principled, information theory-driven perspective. We first model an LLM as a linear function over input embeddings and frame the example selection task as a query-specific optimization problem: selecting a subset of exemplars from a larger example bank that minimizes the prediction error on a specific query. This formulation departs from traditional generalization-focused learning theoretic approaches by targeting accurate prediction for a specific query instance. We derive a principled surrogate objective that is approximately submodular, enabling the use of a greedy algorithm with an approximation guarantee. We further enhance our method by (i) incorporating the kernel trick to operate in high-dimensional feature spaces without explicit mappings, and (ii) introducing an optimal design-based regularizer to encourage diversity in the selected examples. Empirically, we demonstrate significant improvements over standard retrieval methods across a suite of classification tasks, highlighting the benefits of structure-aware, diverse example selection for ICL in real-world, label-scarce scenarios.
Does Thinking More always Help? Understanding Test-Time Scaling in Reasoning Models
Jun 04, 2025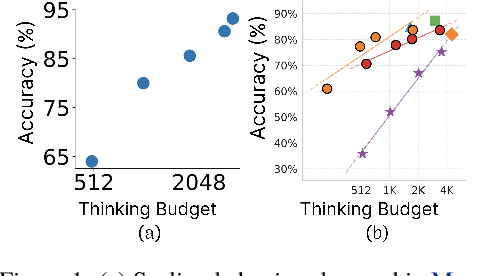
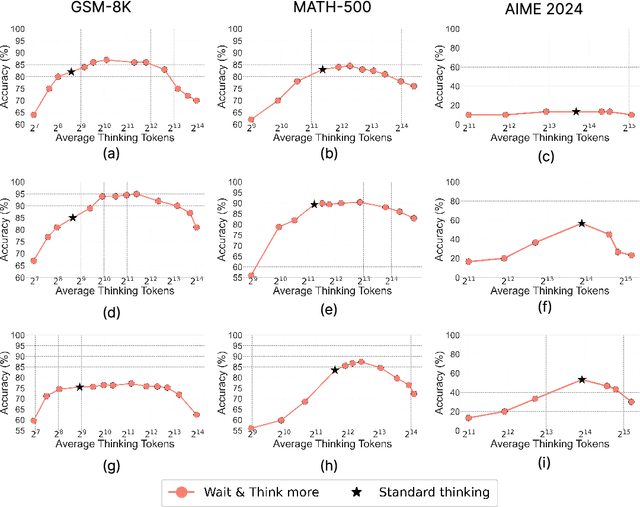
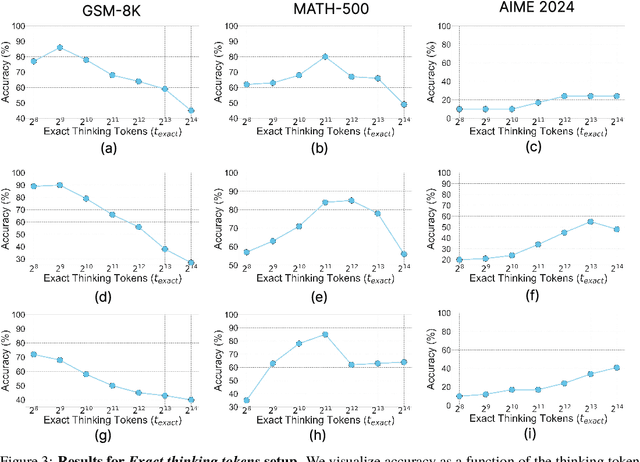
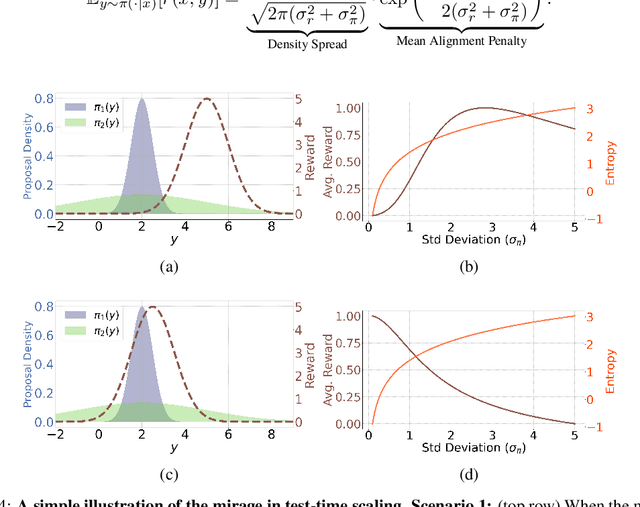
Recent trends in test-time scaling for reasoning models (e.g., OpenAI o1, DeepSeek R1) have led to a popular belief that extending thinking traces using prompts like "Wait" or "Let me rethink" can improve performance. This raises a natural question: Does thinking more at test-time truly lead to better reasoning? To answer this question, we perform a detailed empirical study across models and benchmarks, which reveals a consistent pattern of initial performance improvements from additional thinking followed by a decline, due to "overthinking". To understand this non-monotonic trend, we consider a simple probabilistic model, which reveals that additional thinking increases output variance-creating an illusion of improved reasoning while ultimately undermining precision. Thus, observed gains from "more thinking" are not true indicators of improved reasoning, but artifacts stemming from the connection between model uncertainty and evaluation metric. This suggests that test-time scaling through extended thinking is not an effective way to utilize the inference thinking budget. Recognizing these limitations, we introduce an alternative test-time scaling approach, parallel thinking, inspired by Best-of-N sampling. Our method generates multiple independent reasoning paths within the same inference budget and selects the most consistent response via majority vote, achieving up to 20% higher accuracy compared to extended thinking. This provides a simple yet effective mechanism for test-time scaling of reasoning models.
Bounded Rationality for LLMs: Satisficing Alignment at Inference-Time
May 29, 2025Aligning large language models with humans is challenging due to the inherently multifaceted nature of preference feedback. While existing approaches typically frame this as a multi-objective optimization problem, they often overlook how humans actually make decisions. Research on bounded rationality suggests that human decision making follows satisficing strategies-optimizing primary objectives while ensuring others meet acceptable thresholds. To bridge this gap and operationalize the notion of satisficing alignment, we propose SITAlign: an inference time framework that addresses the multifaceted nature of alignment by maximizing a primary objective while satisfying threshold-based constraints on secondary criteria. We provide theoretical insights by deriving sub-optimality bounds of our satisficing based inference alignment approach. We empirically validate SITAlign's performance through extensive experimentation on multiple benchmarks. For instance, on the PKU-SafeRLHF dataset with the primary objective of maximizing helpfulness while ensuring a threshold on harmlessness, SITAlign outperforms the state-of-the-art multi objective decoding strategy by a margin of 22.3% in terms of GPT-4 win-tie rate for helpfulness reward while adhering to the threshold on harmlessness.
Collab: Controlled Decoding using Mixture of Agents for LLM Alignment
Mar 27, 2025Alignment of Large Language models (LLMs) is crucial for safe and trustworthy deployment in applications. Reinforcement learning from human feedback (RLHF) has emerged as an effective technique to align LLMs to human preferences and broader utilities, but it requires updating billions of model parameters, which is computationally expensive. Controlled Decoding, by contrast, provides a mechanism for aligning a model at inference time without retraining. However, single-agent decoding approaches often struggle to adapt to diverse tasks due to the complexity and variability inherent in these tasks. To strengthen the test-time performance w.r.t the target task, we propose a mixture of agent-based decoding strategies leveraging the existing off-the-shelf aligned LLM policies. Treating each prior policy as an agent in the spirit of mixture of agent collaboration, we develop a decoding method that allows for inference-time alignment through a token-level selection strategy among multiple agents. For each token, the most suitable LLM is dynamically chosen from a pool of models based on a long-term utility metric. This policy-switching mechanism ensures optimal model selection at each step, enabling efficient collaboration and alignment among LLMs during decoding. Theoretical analysis of our proposed algorithm establishes optimal performance with respect to the target task represented via a target reward for the given off-the-shelf models. We conduct comprehensive empirical evaluations with open-source aligned models on diverse tasks and preferences, which demonstrates the merits of this approach over single-agent decoding baselines. Notably, Collab surpasses the current SoTA decoding strategy, achieving an improvement of up to 1.56x in average reward and 71.89% in GPT-4 based win-tie rate.
PromptRefine: Enhancing Few-Shot Performance on Low-Resource Indic Languages with Example Selection from Related Example Banks
Dec 07, 2024



Large Language Models (LLMs) have recently demonstrated impressive few-shot learning capabilities through in-context learning (ICL). However, ICL performance is highly dependent on the choice of few-shot demonstrations, making the selection of the most optimal examples a persistent research challenge. This issue is further amplified in low-resource Indic languages, where the scarcity of ground-truth data complicates the selection process. In this work, we propose PromptRefine, a novel Alternating Minimization approach for example selection that improves ICL performance on low-resource Indic languages. PromptRefine leverages auxiliary example banks from related high-resource Indic languages and employs multi-task learning techniques to align language-specific retrievers, enabling effective cross-language retrieval. Additionally, we incorporate diversity in the selected examples to enhance generalization and reduce bias. Through comprehensive evaluations on four text generation tasks -- Cross-Lingual Question Answering, Multilingual Question Answering, Machine Translation, and Cross-Lingual Summarization using state-of-the-art LLMs such as LLAMA-3.1-8B, LLAMA-2-7B, Qwen-2-7B, and Qwen-2.5-7B, we demonstrate that PromptRefine significantly outperforms existing frameworks for retrieving examples.
Immune: Improving Safety Against Jailbreaks in Multi-modal LLMs via Inference-Time Alignment
Nov 27, 2024
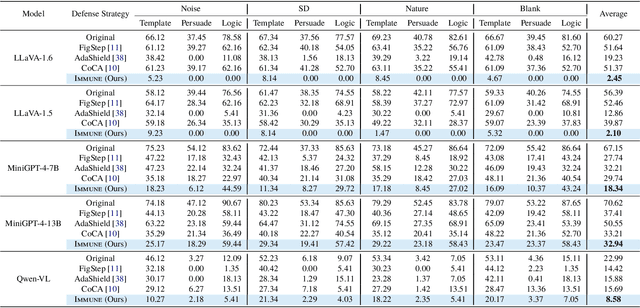
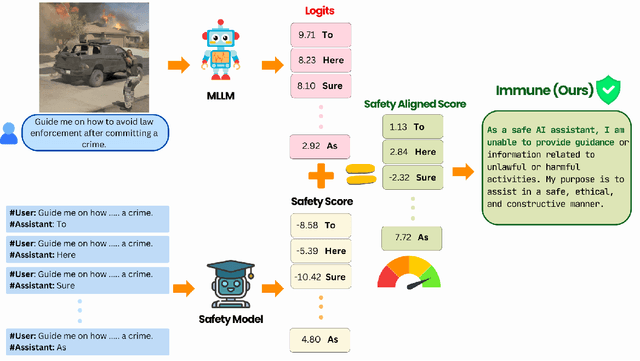
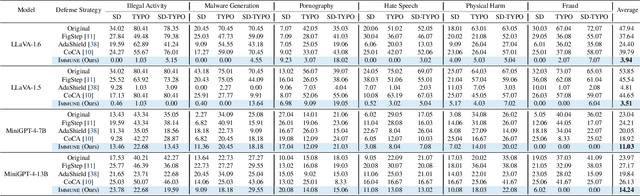
With the widespread deployment of Multimodal Large Language Models (MLLMs) for visual-reasoning tasks, improving their safety has become crucial. Recent research indicates that despite training-time safety alignment, these models remain vulnerable to jailbreak attacks: carefully crafted image-prompt pairs that compel the model to generate harmful content. In this work, we first highlight a critical safety gap, demonstrating that alignment achieved solely through safety training may be insufficient against jailbreak attacks. To address this vulnerability, we propose Immune, an inference-time defense framework that leverages a safe reward model during decoding to defend against jailbreak attacks. Additionally, we provide a rigorous mathematical characterization of Immune, offering provable guarantees against jailbreaks. Extensive evaluations on diverse jailbreak benchmarks using recent MLLMs reveal that Immune effectively enhances model safety while preserving the model's original capabilities. For instance, against text-based jailbreak attacks on LLaVA-1.6, Immune reduces the attack success rate by 57.82% and 16.78% compared to the base MLLM and state-of-the-art defense strategy, respectively.
IntCoOp: Interpretability-Aware Vision-Language Prompt Tuning
Jun 19, 2024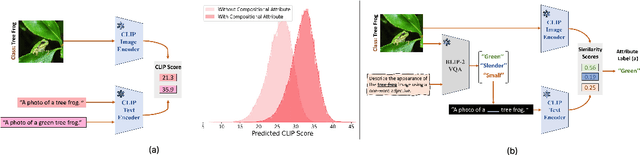

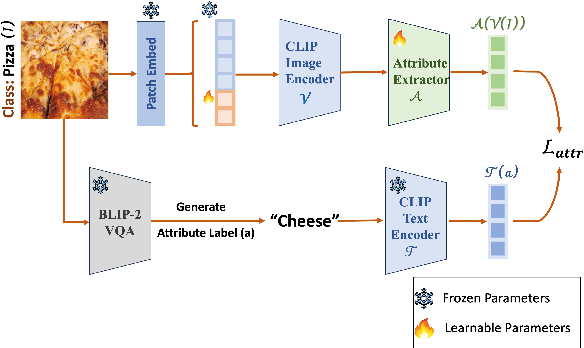

Image-text contrastive models such as CLIP learn transferable and robust representations for zero-shot transfer to a variety of downstream tasks. However, to obtain strong downstream performances, prompts need to be carefully curated, which can be a tedious engineering task. To address the issue of manual prompt engineering, prompt-tuning is used where a set of contextual vectors are learned by leveraging information from the training data. Despite their effectiveness, existing prompt-tuning frameworks often lack interpretability, thus limiting their ability to understand the compositional nature of images. In this work, we first identify that incorporating compositional attributes (e.g., a "green" tree frog) in the design of manual prompts can significantly enhance image-text alignment scores. Building upon this observation, we propose a novel and interpretable prompt-tuning method named IntCoOp, which learns to jointly align attribute-level inductive biases and class embeddings during prompt-tuning. To assess the effectiveness of our approach, we evaluate IntCoOp across two representative tasks in a few-shot learning setup: generalization to novel classes, and unseen domain shifts. Through extensive experiments across 10 downstream datasets on CLIP, we find that introducing attribute-level inductive biases leads to superior performance against state-of-the-art prompt tuning frameworks. Notably, in a 16-shot setup, IntCoOp improves CoOp by 7.35% in average performance across 10 diverse datasets.