 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntCoOp: Interpretability-Aware Vision-Language Prompt Tuning
Paper and Code
Jun 19, 2024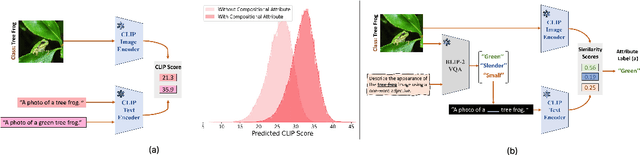

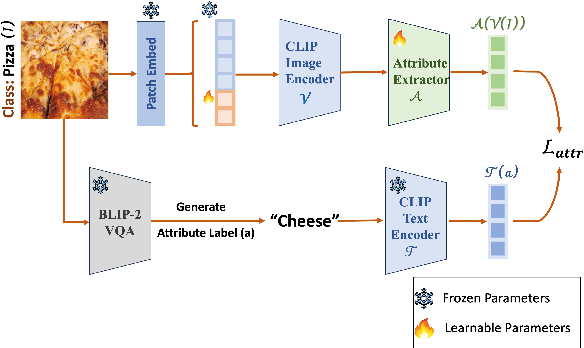

Image-text contrastive models such as CLIP learn transferable and robust representations for zero-shot transfer to a variety of downstream tasks. However, to obtain strong downstream performances, prompts need to be carefully curated, which can be a tedious engineering task. To address the issue of manual prompt engineering, prompt-tuning is used where a set of contextual vectors are learned by leveraging information from the training data. Despite their effectiveness, existing prompt-tuning frameworks often lack interpretability, thus limiting their ability to understand the compositional nature of images. In this work, we first identify that incorporating compositional attributes (e.g., a "green" tree frog) in the design of manual prompts can significantly enhance image-text alignment scores. Building upon this observation, we propose a novel and interpretable prompt-tuning method named IntCoOp, which learns to jointly align attribute-level inductive biases and class embeddings during prompt-tuning. To assess the effectiveness of our approach, we evaluate IntCoOp across two representative tasks in a few-shot learning setup: generalization to novel classes, and unseen domain shifts. Through extensive experiments across 10 downstream datasets on CLIP, we find that introducing attribute-level inductive biases leads to superior performance against state-of-the-art prompt tuning frameworks. Notably, in a 16-shot setup, IntCoOp improves CoOp by 7.35% in average performance across 10 diverse datasets.