 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImmune: Improving Safety Against Jailbreaks in Multi-modal LLMs via Inference-Time Alignment
Paper and Code
Nov 27, 2024
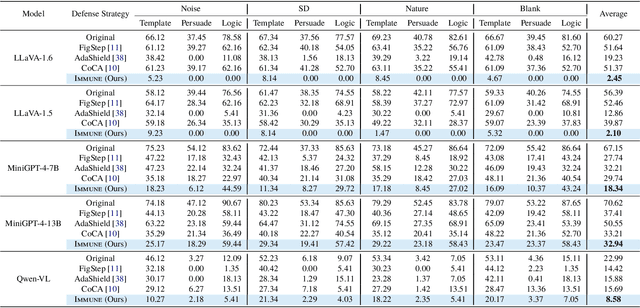
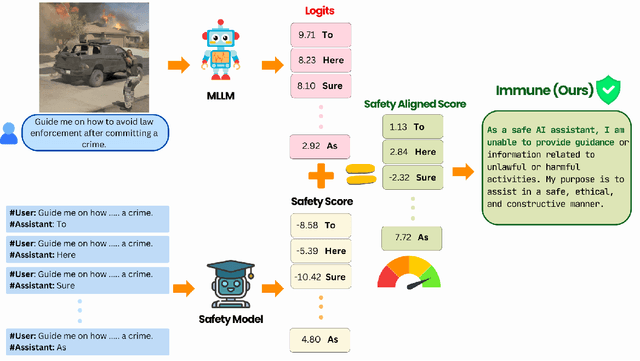
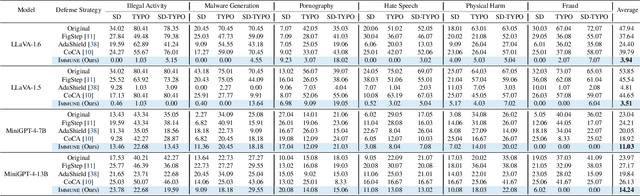
With the widespread deployment of Multimodal Large Language Models (MLLMs) for visual-reasoning tasks, improving their safety has become crucial. Recent research indicates that despite training-time safety alignment, these models remain vulnerable to jailbreak attacks: carefully crafted image-prompt pairs that compel the model to generate harmful content. In this work, we first highlight a critical safety gap, demonstrating that alignment achieved solely through safety training may be insufficient against jailbreak attacks. To address this vulnerability, we propose Immune, an inference-time defense framework that leverages a safe reward model during decoding to defend against jailbreak attacks. Additionally, we provide a rigorous mathematical characterization of Immune, offering provable guarantees against jailbreaks. Extensive evaluations on diverse jailbreak benchmarks using recent MLLMs reveal that Immune effectively enhances model safety while preserving the model's original capabilities. For instance, against text-based jailbreak attacks on LLaVA-1.6, Immune reduces the attack success rate by 57.82% and 16.78% compared to the base MLLM and state-of-the-art defense strategy, respectively.