 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniToM: Benchmarking Theory of Mind in LLMs via Explicit Belief Modeling
May 25, 2026Theory of Mind (ToM), the ability to infer others' knowledge, intentions, and emotions, is commonly evaluated in large language models (LLMs) using end-point question answering, where performance is judged solely by the final answer to a social reasoning query. This paradigm obscures whether the model actually constructs the underlying mental-state representations required for robust reasoning, particularly in scenarios involving divergent, evolving, or mistaken beliefs. In order to address this research gap, we introduce OmniToM, a benchmark that directly evaluates these representations by requiring explicit modeling of belief structures for all relevant actors within a narrative. These structures are composed of belief propositions: minimal statements of what an actor takes to be true about the world or another actor's mental state, allowing knowledge, intentions, emotions, and false beliefs to be analyzed in a common format. Models are evaluated in two stages: Stage 1: Belief Extraction, which extracts from the story the beliefs relevant to its social dynamics, and Stage 2: Belief Labeling, which assigns each belief a seven-dimensional schema label covering recursive order, truth status, knowledge access, explicitness, content type, mental source, and context. Built from 895 stories from the existing ToMBench story corpus and augmented with 22,343 labeled belief propositions, OmniToM uses a human-calibrated LLM-assisted annotation pipeline. Across diverse models in zero-shot evaluation, OmniToM reveals an actor-specific belief-tracking bottleneck: current LLMs struggle with the knowledge-access and representational decisions required to transform narrative facts into actors' beliefs and shared mental states.
RL with Learnable Textual Feedback: A Bilevel Approach
May 23, 2026Reinforcement learning with verifiable rewards can improve LLM reasoning, but learning remains sample-inefficient when terminal rewards are sparse. This has motivated a growing line of work on RL with textual feedback, where a critic model generates natural language feedback to guide a reasoning model (the actor), augmenting scalar rewards with richer learning signals. However, existing methods typically treat feedback as fixed or auxiliary, which misses a key property: feedback should not merely be correct, but should improve the policy (actor model) when provided in context. This motivates a paradigm of learnable textual feedback for RL. Yet the learnability and usefulness of feedback depend on the policy's ability to learn from it, making RL with learnable feedback an inherently bilevel problem. We formalize this coupling as a Stackelberg bilevel program and derive Bilevel Natural Language Actor-Critic (Bi-NAC), which jointly trains a critic to generate reward-improving feedback and an actor to exploit it. Across MATH-500, MBPP, and GPQA, Bi-NAC improves sample and parameter efficiency over RL and fixed-critic baselines: our 2B model outperforms the 3B GRPO baseline, achieving 46.6% versus 41.4% on MATH-500, while our 6B model surpasses the 7B GRPO baseline, achieving 49.3% versus 43.6% on GPQA.
SABER: A Stealthy Agentic Black-Box Attack Framework for Vision-Language-Action Models
Mar 26, 2026Vision-language-action (VLA) models enable robots to follow natural-language instructions grounded in visual observations, but the instruction channel also introduces a critical vulnerability: small textual perturbations can alter downstream robot behavior. Systematic robustness evaluation therefore requires a black-box attacker that can generate minimal yet effective instruction edits across diverse VLA models. To this end, we present SABER, an agent-centric approach for automatically generating instruction-based adversarial attacks on VLA models under bounded edit budgets. SABER uses a GRPO-trained ReAct attacker to generate small, plausible adversarial instruction edits using character-, token-, and prompt-level tools under a bounded edit budget that induces targeted behavioral degradation, including task failure, unnecessarily long execution, and increased constraint violations. On the LIBERO benchmark across six state-of-the-art VLA models, SABER reduces task success by 20.6%, increases action-sequence length by 55%, and raises constraint violations by 33%, while requiring 21.1% fewer tool calls and 54.7% fewer character edits than strong GPT-based baselines. These results show that small, plausible instruction edits are sufficient to substantially degrade robot execution, and that an agentic black-box pipeline offers a practical, scalable, and adaptive approach for red-teaming robotic foundation models.
Why Pass@k Optimization Can Degrade Pass@1: Prompt Interference in LLM Post-training
Feb 26, 2026Pass@k is a widely used performance metric for verifiable large language model tasks, including mathematical reasoning, code generation, and short-answer reasoning. It defines success if any of $k$ independently sampled solutions passes a verifier. This multi-sample inference metric has motivated inference-aware fine-tuning methods that directly optimize pass@$k$. However, prior work reports a recurring trade-off: pass@k improves while pass@1 degrades under such methods. This trade-off is practically important because pass@1 often remains a hard operational constraint due to latency and cost budgets, imperfect verifier coverage, and the need for a reliable single-shot fallback. We study the origin of this trade-off and provide a theoretical characterization of when pass@k policy optimization can reduce pass@1 through gradient conflict induced by prompt interference. We show that pass@$k$ policy gradients can conflict with pass@1 gradients because pass@$k$ optimization implicitly reweights prompts toward low-success prompts; when these prompts are what we term negatively interfering, their upweighting can rotate the pass@k update direction away from the pass@1 direction. We illustrate our theoretical findings with large language model experiments on verifiable mathematical reasoning tasks.
Safety Recovery in Reasoning Models Is Only a Few Early Steering Steps Away
Feb 11, 2026Reinforcement learning (RL) based post-training for explicit chain-of-thought (e.g., GRPO) improves the reasoning ability of multimodal large-scale reasoning models (MLRMs). But recent evidence shows that it can simultaneously degrade safety alignment and increase jailbreak success rates. We propose SafeThink, a lightweight inference-time defense that treats safety recovery as a satisficing constraint rather than a maximization objective. SafeThink monitors the evolving reasoning trace with a safety reward model and conditionally injects an optimized short corrective prefix ("Wait, think safely") only when the safety threshold is violated. In our evaluations across six open-source MLRMs and four jailbreak benchmarks (JailbreakV-28K, Hades, FigStep, and MM-SafetyBench), SafeThink reduces attack success rates by 30-60% (e.g., LlamaV-o1: 63.33% to 5.74% on JailbreakV-28K, R1-Onevision: 69.07% to 5.65% on Hades) while preserving reasoning performance (MathVista accuracy: 65.20% to 65.00%). A key empirical finding from our experiments is that safety recovery is often only a few steering steps away: intervening in the first 1-3 reasoning steps typically suffices to redirect the full generation toward safe completions.
AI Cap-and-Trade: Efficiency Incentives for Accessibility and Sustainability
Jan 27, 2026The race for artificial intelligence (AI) dominance often prioritizes scale over efficiency. Hyper-scaling is the common industry approach: larger models, more data, and as many computational resources as possible. Using more resources is a simpler path to improved AI performance. Thus, efficiency has been de-emphasized. Consequently, the need for costly computational resources has marginalized academics and smaller companies. Simultaneously, increased energy expenditure, due to growing AI use, has led to mounting environmental costs. In response to accessibility and sustainability concerns, we argue for research into, and implementation of, market-based methods that incentivize AI efficiency. We believe that incentivizing efficient operations and approaches will reduce emissions while opening new opportunities for academics and smaller companies. As a call to action, we propose a cap-and-trade system for AI. Our system provably reduces computations for AI deployment, thereby lowering emissions and monetizing efficiency to the benefit of of academics and smaller companies.
Test-Time Scaling in Diffusion LLMs via Hidden Semi-Autoregressive Experts
Oct 06, 2025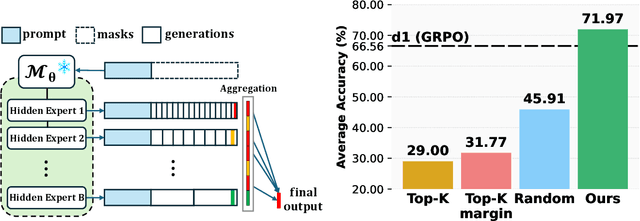
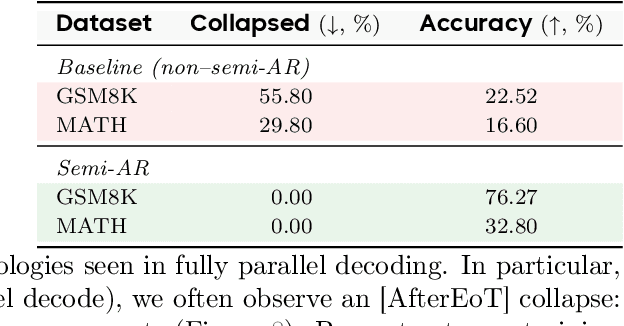
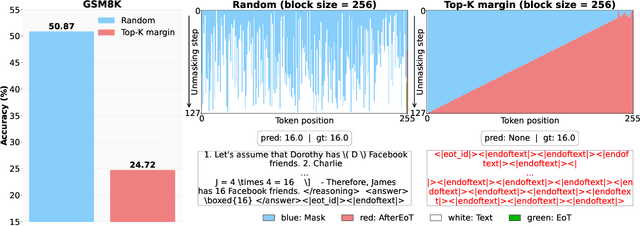
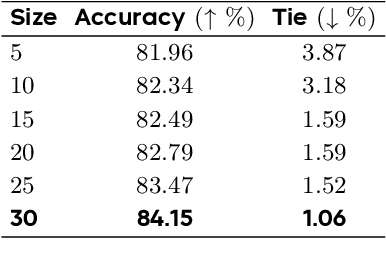
Diffusion-based large language models (dLLMs) are trained flexibly to model extreme dependence in the data distribution; however, how to best utilize this information at inference time remains an open problem. In this work, we uncover an interesting property of these models: dLLMs trained on textual data implicitly learn a mixture of semi-autoregressive experts, where different generation orders reveal different specialized behaviors. We show that committing to any single, fixed inference time schedule, a common practice, collapses performance by failing to leverage this latent ensemble. To address this, we introduce HEX (Hidden semiautoregressive EXperts for test-time scaling), a training-free inference method that ensembles across heterogeneous block schedules. By doing a majority vote over diverse block-sized generation paths, HEX robustly avoids failure modes associated with any single fixed schedule. On reasoning benchmarks such as GSM8K, it boosts accuracy by up to 3.56X (from 24.72% to 88.10%), outperforming top-K margin inference and specialized fine-tuned methods like GRPO, without additional training. HEX even yields significant gains on MATH benchmark from 16.40% to 40.00%, scientific reasoning on ARC-C from 54.18% to 87.80%, and TruthfulQA from 28.36% to 57.46%. Our results establish a new paradigm for test-time scaling in diffusion-based LLMs (dLLMs), revealing that the sequence in which masking is performed plays a critical role in determining performance during inference.
MIRA: Towards Mitigating Reward Hacking in Inference-Time Alignment of T2I Diffusion Models
Oct 02, 2025Diffusion models excel at generating images conditioned on text prompts, but the resulting images often do not satisfy user-specific criteria measured by scalar rewards such as Aesthetic Scores. This alignment typically requires fine-tuning, which is computationally demanding. Recently, inference-time alignment via noise optimization has emerged as an efficient alternative, modifying initial input noise to steer the diffusion denoising process towards generating high-reward images. However, this approach suffers from reward hacking, where the model produces images that score highly, yet deviate significantly from the original prompt. We show that noise-space regularization is insufficient and that preventing reward hacking requires an explicit image-space constraint. To this end, we propose MIRA (MItigating Reward hAcking), a training-free, inference-time alignment method. MIRA introduces an image-space, score-based KL surrogate that regularizes the sampling trajectory with a frozen backbone, constraining the output distribution so reward can increase without off-distribution drift (reward hacking). We derive a tractable approximation to KL using diffusion scores. Across SDv1.5 and SDXL, multiple rewards (Aesthetic, HPSv2, PickScore), and public datasets (e.g., Animal-Animal, HPDv2), MIRA achieves >60\% win rate vs. strong baselines while preserving prompt adherence; mechanism plots show reward gains with near-zero drift, whereas DNO drifts as compute increases. We further introduce MIRA-DPO, mapping preference optimization to inference time with a frozen backbone, extending MIRA to non-differentiable rewards without fine-tuning.
Leveraging Pre-Trained Visual Models for AI-Generated Video Detection
Jul 17, 2025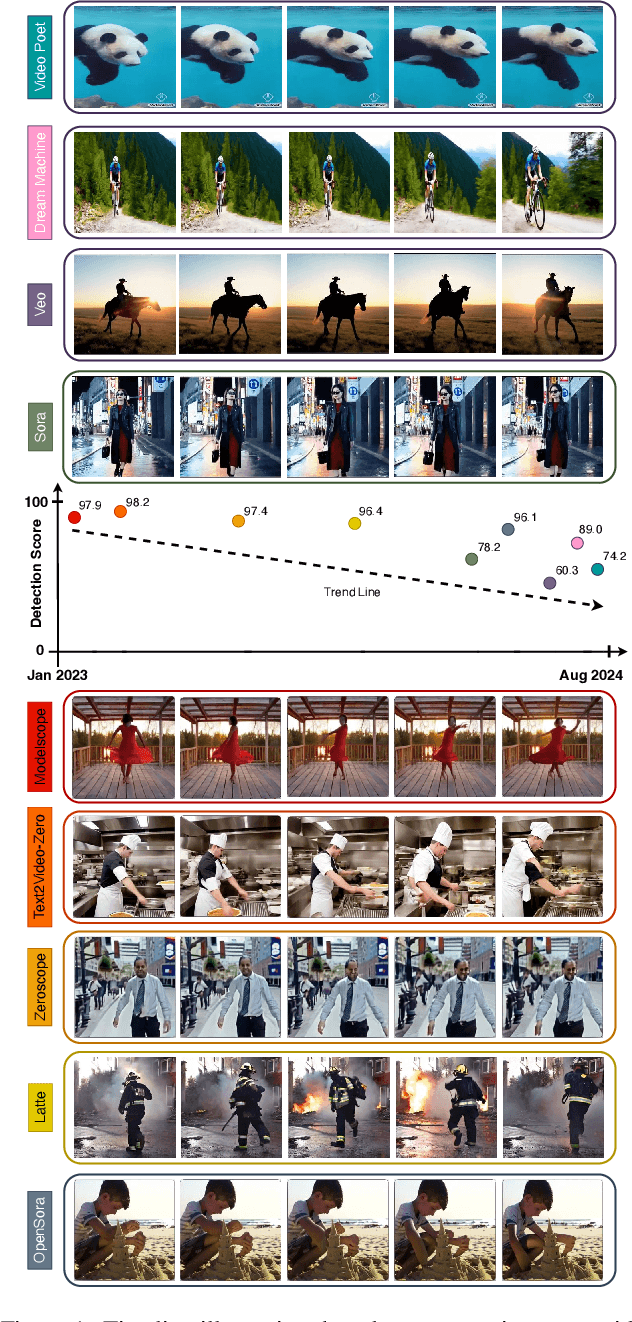
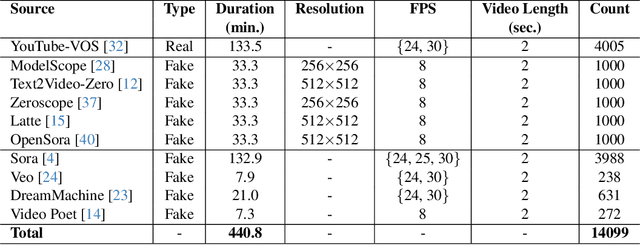
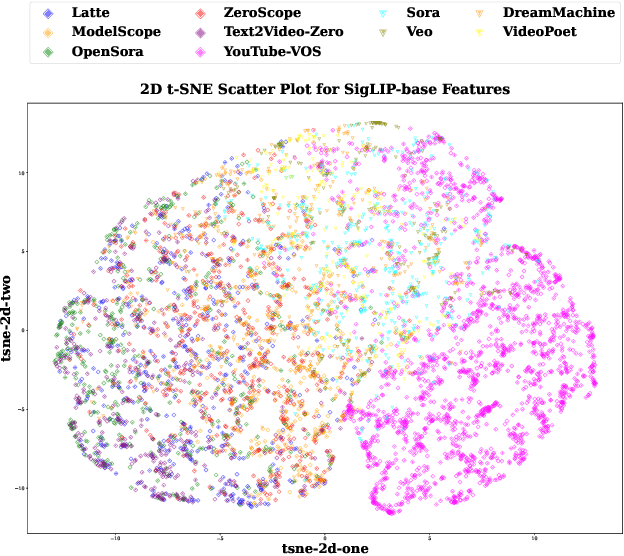
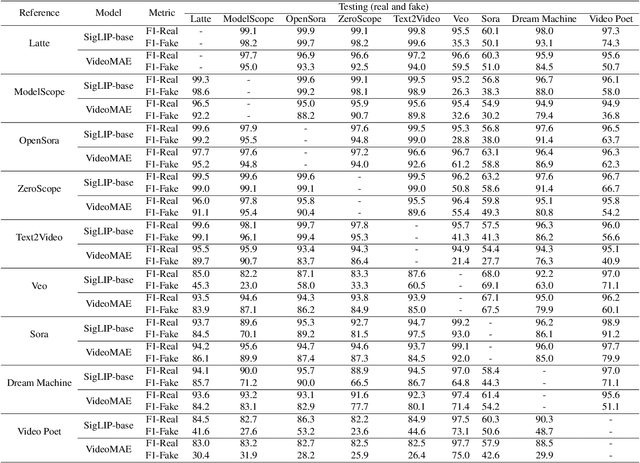
Recent advances in Generative AI (GenAI) have led to significant improvements in the quality of generated visual content. As AI-generated visual content becomes increasingly indistinguishable from real content, the challenge of detecting the generated content becomes critical in combating misinformation, ensuring privacy, and preventing security threats. Although there has been substantial progress in detecting AI-generated images, current methods for video detection are largely focused on deepfakes, which primarily involve human faces. However, the field of video generation has advanced beyond DeepFakes, creating an urgent need for methods capable of detecting AI-generated videos with generic content. To address this gap, we propose a novel approach that leverages pre-trained visual models to distinguish between real and generated videos. The features extracted from these pre-trained models, which have been trained on extensive real visual content, contain inherent signals that can help distinguish real from generated videos. Using these extracted features, we achieve high detection performance without requiring additional model training, and we further improve performance by training a simple linear classification layer on top of the extracted features. We validated our method on a dataset we compiled (VID-AID), which includes around 10,000 AI-generated videos produced by 9 different text-to-video models, along with 4,000 real videos, totaling over 7 hours of video content. Our evaluation shows that our approach achieves high detection accuracy, above 90% on average, underscoring its effectiveness. Upon acceptance, we plan to publicly release the code, the pre-trained models, and our dataset to support ongoing research in this critical area.
Does Thinking More always Help? Understanding Test-Time Scaling in Reasoning Models
Jun 04, 2025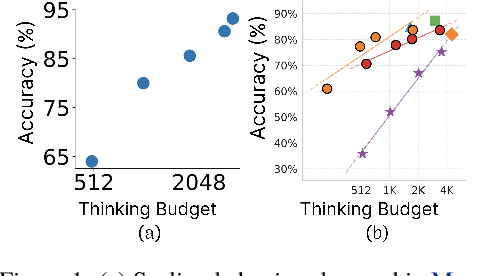
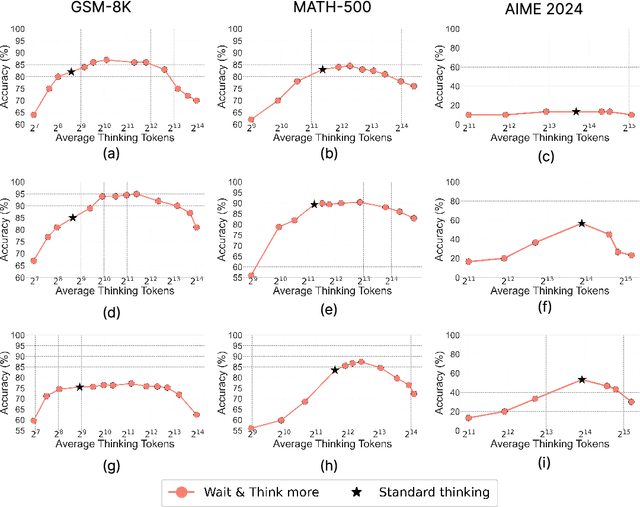
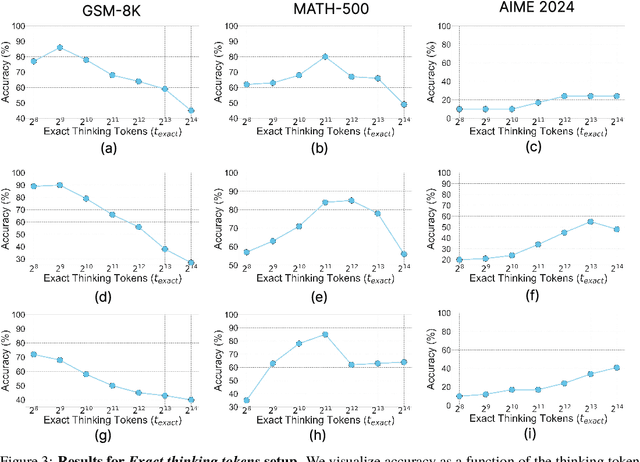
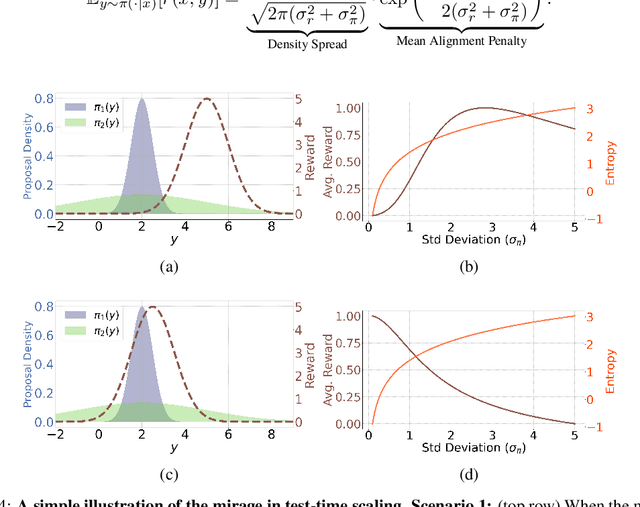
Recent trends in test-time scaling for reasoning models (e.g., OpenAI o1, DeepSeek R1) have led to a popular belief that extending thinking traces using prompts like "Wait" or "Let me rethink" can improve performance. This raises a natural question: Does thinking more at test-time truly lead to better reasoning? To answer this question, we perform a detailed empirical study across models and benchmarks, which reveals a consistent pattern of initial performance improvements from additional thinking followed by a decline, due to "overthinking". To understand this non-monotonic trend, we consider a simple probabilistic model, which reveals that additional thinking increases output variance-creating an illusion of improved reasoning while ultimately undermining precision. Thus, observed gains from "more thinking" are not true indicators of improved reasoning, but artifacts stemming from the connection between model uncertainty and evaluation metric. This suggests that test-time scaling through extended thinking is not an effective way to utilize the inference thinking budget. Recognizing these limitations, we introduce an alternative test-time scaling approach, parallel thinking, inspired by Best-of-N sampling. Our method generates multiple independent reasoning paths within the same inference budget and selects the most consistent response via majority vote, achieving up to 20% higher accuracy compared to extended thinking. This provides a simple yet effective mechanism for test-time scaling of reasoning models.