 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Pre-Trained Visual Models for AI-Generated Video Detection
Jul 17, 2025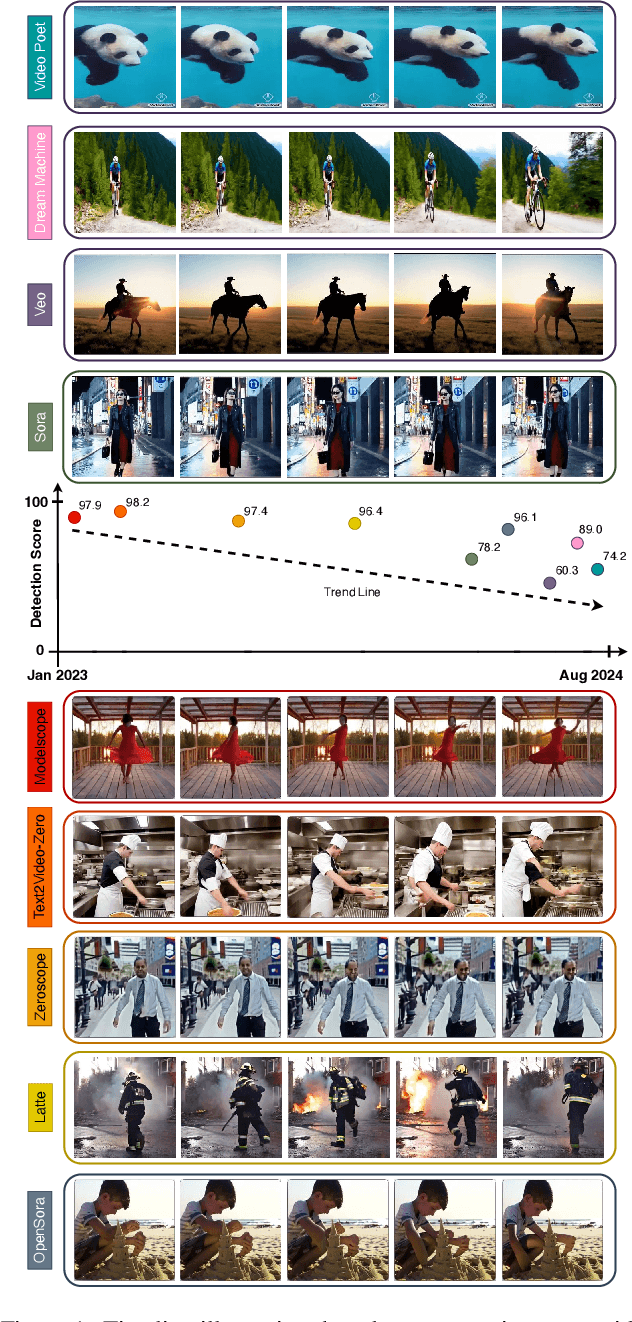
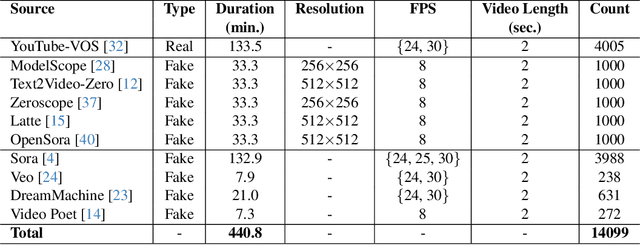
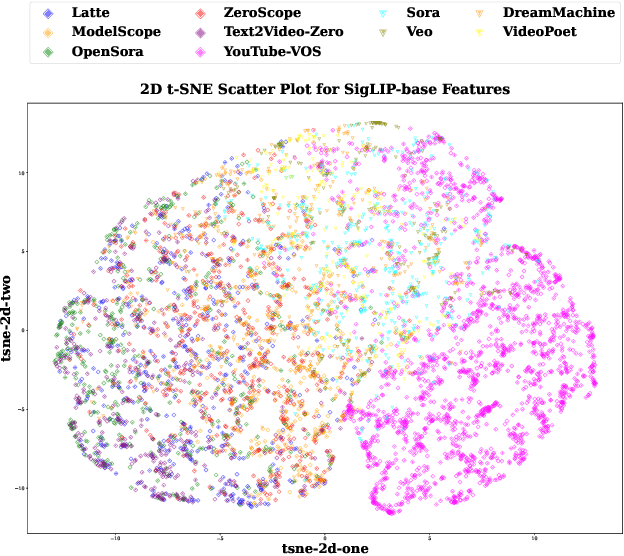
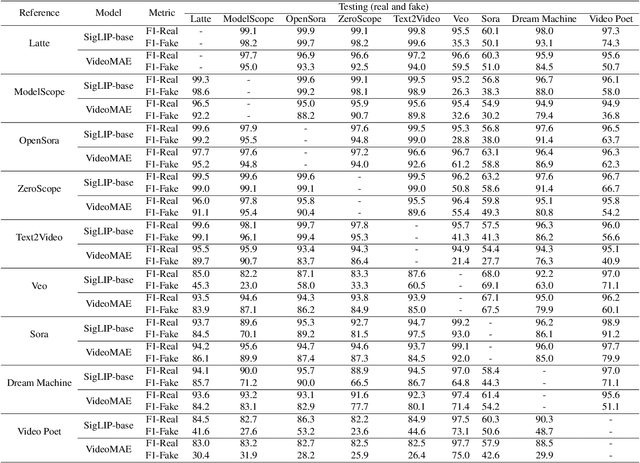
Recent advances in Generative AI (GenAI) have led to significant improvements in the quality of generated visual content. As AI-generated visual content becomes increasingly indistinguishable from real content, the challenge of detecting the generated content becomes critical in combating misinformation, ensuring privacy, and preventing security threats. Although there has been substantial progress in detecting AI-generated images, current methods for video detection are largely focused on deepfakes, which primarily involve human faces. However, the field of video generation has advanced beyond DeepFakes, creating an urgent need for methods capable of detecting AI-generated videos with generic content. To address this gap, we propose a novel approach that leverages pre-trained visual models to distinguish between real and generated videos. The features extracted from these pre-trained models, which have been trained on extensive real visual content, contain inherent signals that can help distinguish real from generated videos. Using these extracted features, we achieve high detection performance without requiring additional model training, and we further improve performance by training a simple linear classification layer on top of the extracted features. We validated our method on a dataset we compiled (VID-AID), which includes around 10,000 AI-generated videos produced by 9 different text-to-video models, along with 4,000 real videos, totaling over 7 hours of video content. Our evaluation shows that our approach achieves high detection accuracy, above 90% on average, underscoring its effectiveness. Upon acceptance, we plan to publicly release the code, the pre-trained models, and our dataset to support ongoing research in this critical area.
MGD$^3$: Mode-Guided Dataset Distillation using Diffusion Models
May 25, 2025Dataset distillation has emerged as an effective strategy, significantly reducing training costs and facilitating more efficient model deployment. Recent advances have leveraged generative models to distill datasets by capturing the underlying data distribution. Unfortunately, existing methods require model fine-tuning with distillation losses to encourage diversity and representativeness. However, these methods do not guarantee sample diversity, limiting their performance. We propose a mode-guided diffusion model leveraging a pre-trained diffusion model without the need to fine-tune with distillation losses. Our approach addresses dataset diversity in three stages: Mode Discovery to identify distinct data modes, Mode Guidance to enhance intra-class diversity, and Stop Guidance to mitigate artifacts in synthetic samples that affect performance. Our approach outperforms state-of-the-art methods, achieving accuracy gains of 4.4%, 2.9%, 1.6%, and 1.6% on ImageNette, ImageIDC, ImageNet-100, and ImageNet-1K, respectively. Our method eliminates the need for fine-tuning diffusion models with distillation losses, significantly reducing computational costs. Our code is available on the project webpage: https://jachansantiago.github.io/mode-guided-distillation/
DVANet: Disentangling View and Action Features for Multi-View Action Recognition
Dec 10, 2023In this work, we present a novel approach to multi-view action recognition where we guide learned action representations to be separated from view-relevant information in a video. When trying to classify action instances captured from multiple viewpoints, there is a higher degree of difficulty due to the difference in background, occlusion, and visibility of the captured action from different camera angles. To tackle the various problems introduced in multi-view action recognition, we propose a novel configuration of learnable transformer decoder queries, in conjunction with two supervised contrastive losses, to enforce the learning of action features that are robust to shifts in viewpoints. Our disentangled feature learning occurs in two stages: the transformer decoder uses separate queries to separately learn action and view information, which are then further disentangled using our two contrastive losses. We show that our model and method of training significantly outperforms all other uni-modal models on four multi-view action recognition datasets: NTU RGB+D, NTU RGB+D 120, PKU-MMD, and N-UCLA. Compared to previous RGB works, we see maximal improvements of 1.5\%, 4.8\%, 2.2\%, and 4.8\% on each dataset, respectively.
Video Action Detection: Analysing Limitations and Challenges
Apr 17, 2022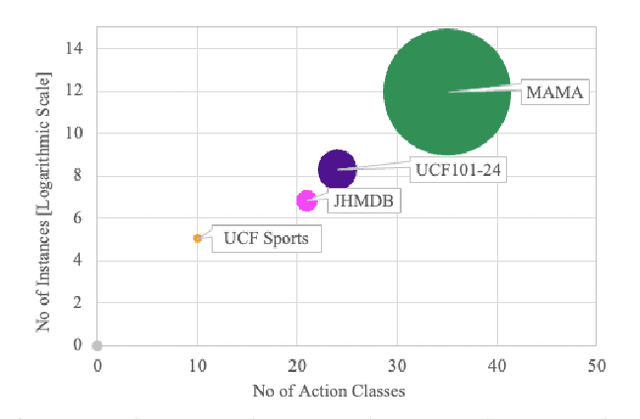
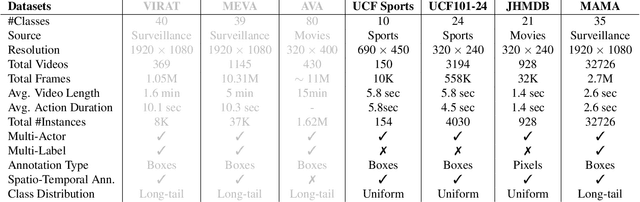

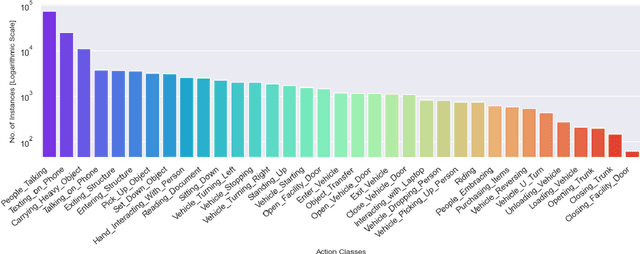
Beyond possessing large enough size to feed data hungry machines (eg, transformers), what attributes measure the quality of a dataset? Assuming that the definitions of such attributes do exist, how do we quantify among their relative existences? Our work attempts to explore these questions for video action detection. The task aims to spatio-temporally localize an actor and assign a relevant action class. We first analyze the existing datasets on video action detection and discuss their limitations. Next, we propose a new dataset, Multi Actor Multi Action (MAMA) which overcomes these limitations and is more suitable for real world applications. In addition, we perform a biasness study which analyzes a key property differentiating videos from static images: the temporal aspect. This reveals if the actions in these datasets really need the motion information of an actor, or whether they predict the occurrence of an action even by looking at a single frame. Finally, we investigate the widely held assumptions on the importance of temporal ordering: is temporal ordering important for detecting these actions? Such extreme experiments show existence of biases which have managed to creep into existing methods inspite of careful modeling.
Violence Detection in Videos
Sep 18, 2021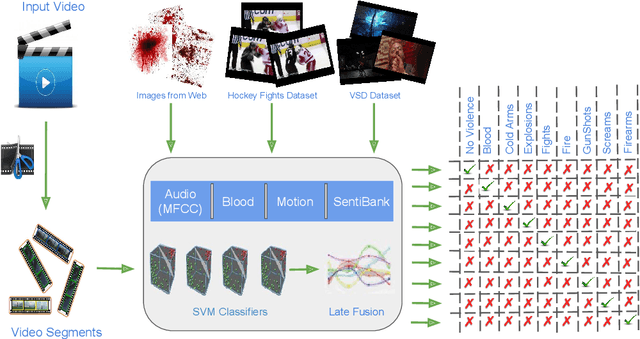


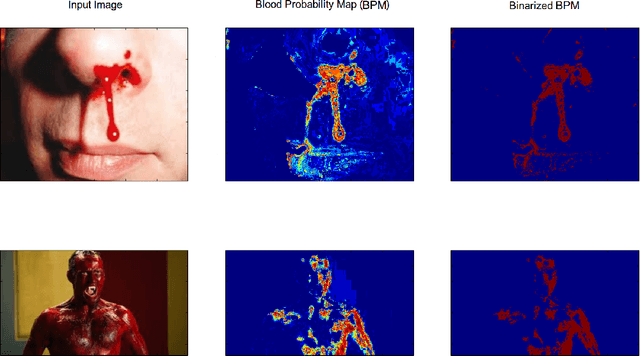
In the recent years, there has been a tremendous increase in the amount of video content uploaded to social networking and video sharing websites like Facebook and Youtube. As of result of this, the risk of children getting exposed to adult and violent content on the web also increased. To address this issue, an approach to automatically detect violent content in videos is proposed in this work. Here, a novel attempt is made also to detect the category of violence present in a video. A system which can automatically detect violence from both Hollywood movies and videos from the web is extremely useful not only in parental control but also for applications related to movie ratings, video surveillance, genre classification and so on. Here, both audio and visual features are used to detect violence. MFCC features are used as audio cues. Blood, Motion, and SentiBank features are used as visual cues. Binary SVM classifiers are trained on each of these features to detect violence. Late fusion using a weighted sum of classification scores is performed to get final classification scores for each of the violence class target by the system. To determine optimal weights for each of the violence classes an approach based on grid search is employed. Publicly available datasets, mainly Violent Scene Detection (VSD), are used for classifier training, weight calculation, and testing. The performance of the system is evaluated on two classification tasks, Multi-Class classification, and Binary Classification. The results obtained for Binary Classification are better than the baseline results from MediaEval-2014.
TinyAction Challenge: Recognizing Real-world Low-resolution Activities in Videos
Jul 24, 2021

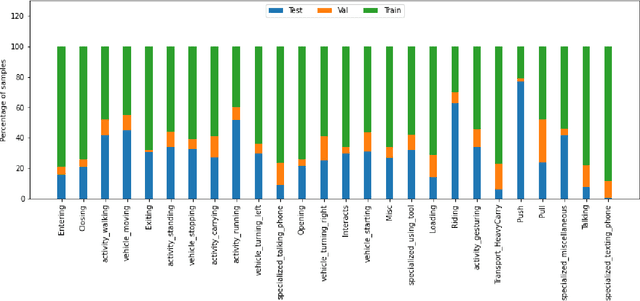
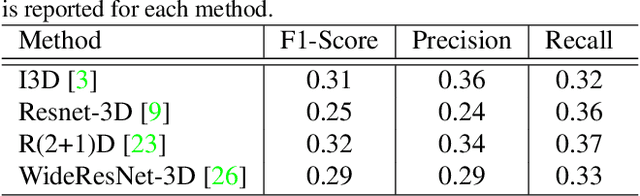
This paper summarizes the TinyAction challenge which was organized in ActivityNet workshop at CVPR 2021. This challenge focuses on recognizing real-world low-resolution activities present in videos. Action recognition task is currently focused around classifying the actions from high-quality videos where the actors and the action is clearly visible. While various approaches have been shown effective for recognition task in recent works, they often do not deal with videos of lower resolution where the action is happening in a tiny region. However, many real world security videos often have the actual action captured in a small resolution, making action recognition in a tiny region a challenging task. In this work, we propose a benchmark dataset, TinyVIRAT-v2, which is comprised of naturally occuring low-resolution actions. This is an extension of the TinyVIRAT dataset and consists of actions with multiple labels. The videos are extracted from security videos which makes them realistic and more challenging. We use current state-of-the-art action recognition methods on the dataset as a benchmark, and propose the TinyAction Challenge.
Modeling Multi-Label Action Dependencies for Temporal Action Localization
Mar 05, 2021

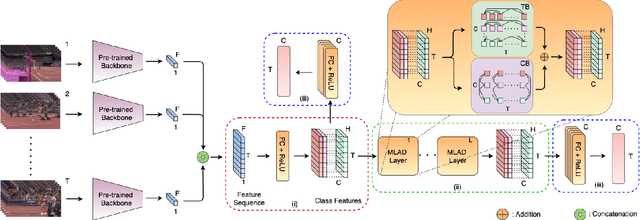
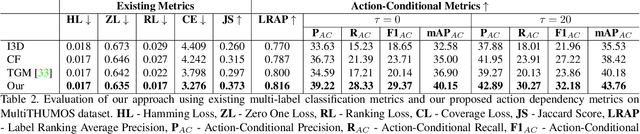
Real-world videos contain many complex actions with inherent relationships between action classes. In this work, we propose an attention-based architecture that models these action relationships for the task of temporal action localization in untrimmed videos. As opposed to previous works that leverage video-level co-occurrence of actions, we distinguish the relationships between actions that occur at the same time-step and actions that occur at different time-steps (i.e. those which precede or follow each other). We define these distinct relationships as action dependencies. We propose to improve action localization performance by modeling these action dependencies in a novel attention-based Multi-Label Action Dependency (MLAD)layer. The MLAD layer consists of two branches: a Co-occurrence Dependency Branch and a Temporal Dependency Branch to model co-occurrence action dependencies and temporal action dependencies, respectively. We observe that existing metrics used for multi-label classification do not explicitly measure how well action dependencies are modeled, therefore, we propose novel metrics that consider both co-occurrence and temporal dependencies between action classes. Through empirical evaluation and extensive analysis, we show improved performance over state-of-the-art methods on multi-label action localization benchmarks(MultiTHUMOS and Charades) in terms of f-mAP and our proposed metric.
Gabriella: An Online System for Real-Time Activity Detection in Untrimmed Security Videos
May 19, 2020

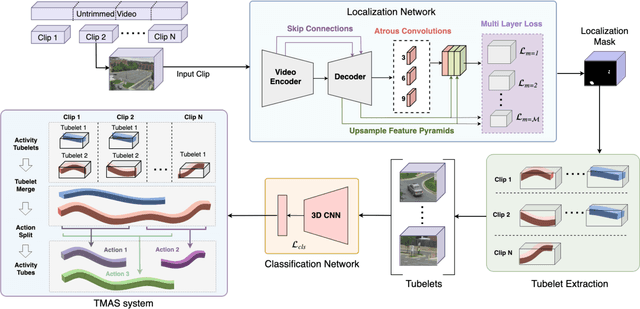
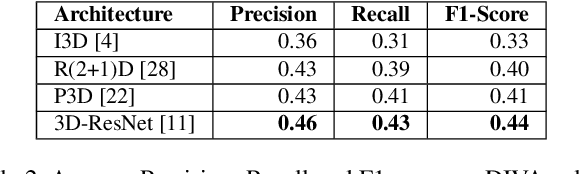
Activity detection in security videos is a difficult problem due to multiple factors such as large field of view, presence of multiple activities, varying scales and viewpoints, and its untrimmed nature. The existing research in activity detection is mainly focused on datasets, such as UCF-101, JHMDB, THUMOS, and AVA, which partially address these issues. The requirement of processing the security videos in real-time makes this even more challenging. In this work we propose Gabriella, a real-time online system to perform activity detection on untrimmed security videos. The proposed method consists of three stages: tubelet extraction, activity classification, and online tubelet merging. For tubelet extraction, we propose a localization network which takes a video clip as input and spatio-temporally detects potential foreground regions at multiple scales to generate action tubelets. We propose a novel Patch-Dice loss to handle large variations in actor size. Our online processing of videos at a clip level drastically reduces the computation time in detecting activities. The detected tubelets are assigned activity class scores by the classification network and merged together using our proposed Tubelet-Merge Action-Split (TMAS) algorithm to form the final action detections. The TMAS algorithm efficiently connects the tubelets in an online fashion to generate action detections which are robust against varying length activities. We perform our experiments on the VIRAT and MEVA (Multiview Extended Video with Activities) datasets and demonstrate the effectiveness of the proposed approach in terms of speed (~100 fps) and performance with state-of-the-art results. The code and models will be made publicly available.