 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Action Detection: Analysing Limitations and Challenges
Apr 17, 2022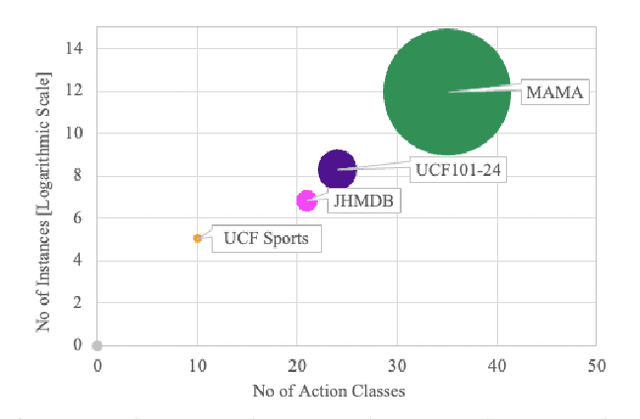
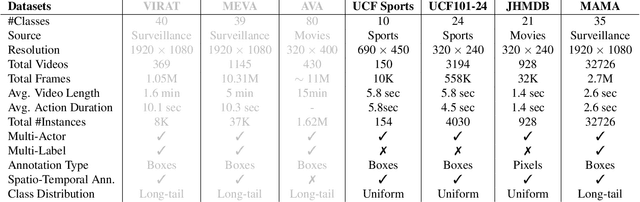

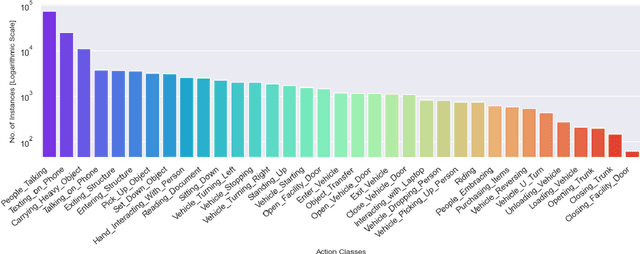
Beyond possessing large enough size to feed data hungry machines (eg, transformers), what attributes measure the quality of a dataset? Assuming that the definitions of such attributes do exist, how do we quantify among their relative existences? Our work attempts to explore these questions for video action detection. The task aims to spatio-temporally localize an actor and assign a relevant action class. We first analyze the existing datasets on video action detection and discuss their limitations. Next, we propose a new dataset, Multi Actor Multi Action (MAMA) which overcomes these limitations and is more suitable for real world applications. In addition, we perform a biasness study which analyzes a key property differentiating videos from static images: the temporal aspect. This reveals if the actions in these datasets really need the motion information of an actor, or whether they predict the occurrence of an action even by looking at a single frame. Finally, we investigate the widely held assumptions on the importance of temporal ordering: is temporal ordering important for detecting these actions? Such extreme experiments show existence of biases which have managed to creep into existing methods inspite of careful modeling.
Gabriella: An Online System for Real-Time Activity Detection in Untrimmed Security Videos
May 19, 2020

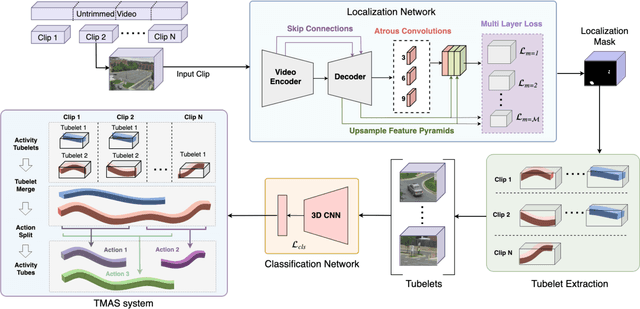
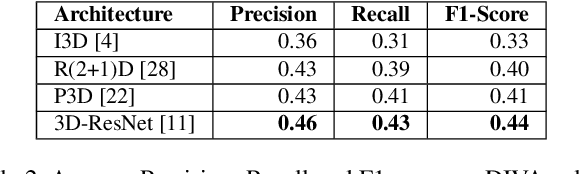
Activity detection in security videos is a difficult problem due to multiple factors such as large field of view, presence of multiple activities, varying scales and viewpoints, and its untrimmed nature. The existing research in activity detection is mainly focused on datasets, such as UCF-101, JHMDB, THUMOS, and AVA, which partially address these issues. The requirement of processing the security videos in real-time makes this even more challenging. In this work we propose Gabriella, a real-time online system to perform activity detection on untrimmed security videos. The proposed method consists of three stages: tubelet extraction, activity classification, and online tubelet merging. For tubelet extraction, we propose a localization network which takes a video clip as input and spatio-temporally detects potential foreground regions at multiple scales to generate action tubelets. We propose a novel Patch-Dice loss to handle large variations in actor size. Our online processing of videos at a clip level drastically reduces the computation time in detecting activities. The detected tubelets are assigned activity class scores by the classification network and merged together using our proposed Tubelet-Merge Action-Split (TMAS) algorithm to form the final action detections. The TMAS algorithm efficiently connects the tubelets in an online fashion to generate action detections which are robust against varying length activities. We perform our experiments on the VIRAT and MEVA (Multiview Extended Video with Activities) datasets and demonstrate the effectiveness of the proposed approach in terms of speed (~100 fps) and performance with state-of-the-art results. The code and models will be made publicly available.