 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolSight: Molecular Property Prediction with Images
May 11, 2026Every molecule ever synthesised can be drawn as a 2D skeletal diagram, yet in modern property prediction this universally available representation has received less focus in favour of molecular graphs, 3D conformers, or billion-parameter language models, each imposing its own computational and data-engineering overhead. We present $\textbf{MolSight}$, the first systematic large-scale study of vision-based Molecular Property Prediction (MPP). Using 10 vision architectures, 7 pre-training strategies, and $2\,M$ molecule images, we evaluate performance across 10 downstream tasks spanning physical-property regression, drug-discovery classification, and quantum-chemistry prediction. To account for the wide variation in structural complexity across pre-training molecules, we further propose a $\textbf{chemistry-informed curriculum}$: five structural complexity descriptors partition the corpus into five tiers of increasing chemical difficulty, consistently outperforming non-curriculum baselines. We show that a single rendered bond-line image, processed by a vision encoder, is sufficient for competitive molecular property prediction, i.e. $\textit{chemical insight from sight alone}$. The best curriculum-trained configuration achieves the top result on $\textbf{5 of 10}$ benchmarks and top two on $\textbf{all 10}$, at $\textbf{$\textit{80$\times$ lower}$}$ FLOPs than the nearest multi-modal competitor.
Bridging Foundation Models and ASTM Metallurgical Standards for Automated Grain Size Estimation from Microscopy Images
Apr 21, 2026Extracting standardized metallurgical metrics from microscopy images remains challenging due to complex grain morphology and the data demands of supervised segmentation. To bridge foundational computer vision with practical metallurgical evaluation, we propose an automated pipeline for dense instance segmentation and grain size estimation that adapts Cellpose-SAM to microstructures and integrates its topology-aware gradient tracking with an ASTM E112 Jeffries planimetric module. We systematically benchmark this pipeline against a classical convolutional network (U-Net), an adaptive-prompting vision foundation model (MatSAM) and a contemporary vision-language model (Qwen2.5-VL-7B). Our evaluations reveal that while the out-of-the-box vision-language model struggles with the localized spatial reasoning required for dense microscopic counting and MatSAM suffers from over-segmentation despite its domain-specific prompt generation, our adapted pipeline successfully maintains topological separation. Furthermore, experiments across progressively reduced training splits demonstrate exceptional few-shot scalability; utilizing only two training samples, the proposed system predicts the ASTM grain size number (G) with a mean absolute percentage error (MAPE) as low as 1.50%, while robustness testing across varying target grain counts empirically validates the ASTM 50-grain sampling minimum. These results highlight the efficacy of application-level foundation model integration for highly accurate, automated materials characterization. Our project repository is available at https://github.com/mueez-overflow/ASTM-Grain-Size-Estimator.
ChemPro: A Progressive Chemistry Benchmark for Large Language Models
Feb 03, 2026We introduce ChemPro, a progressive benchmark with 4100 natural language question-answer pairs in Chemistry, across 4 coherent sections of difficulty designed to assess the proficiency of Large Language Models (LLMs) in a broad spectrum of general chemistry topics. We include Multiple Choice Questions and Numerical Questions spread across fine-grained information recall, long-horizon reasoning, multi-concept questions, problem-solving with nuanced articulation, and straightforward questions in a balanced ratio, effectively covering Bio-Chemistry, Inorganic-Chemistry, Organic-Chemistry and Physical-Chemistry. ChemPro is carefully designed analogous to a student's academic evaluation for basic to high-school chemistry. A gradual increase in the question difficulty rigorously tests the ability of LLMs to progress from solving basic problems to solving more sophisticated challenges. We evaluate 45+7 state-of-the-art LLMs, spanning both open-source and proprietary variants, and our analysis reveals that while LLMs perform well on basic chemistry questions, their accuracy declines with different types and levels of complexity. These findings highlight the critical limitations of LLMs in general scientific reasoning and understanding and point towards understudied dimensions of difficulty, emphasizing the need for more robust methodologies to improve LLMs.
SynSpill: Improved Industrial Spill Detection With Synthetic Data
Aug 13, 2025
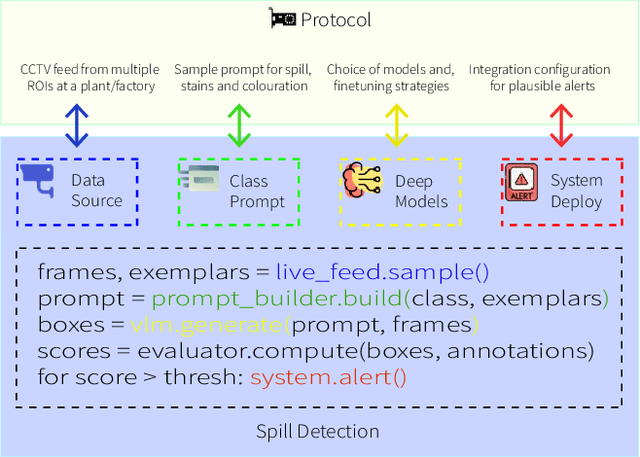


Large-scale Vision-Language Models (VLMs) have transformed general-purpose visual recognition through strong zero-shot capabilities. However, their performance degrades significantly in niche, safety-critical domains such as industrial spill detection, where hazardous events are rare, sensitive, and difficult to annotate. This scarcity -- driven by privacy concerns, data sensitivity, and the infrequency of real incidents -- renders conventional fine-tuning of detectors infeasible for most industrial settings. We address this challenge by introducing a scalable framework centered on a high-quality synthetic data generation pipeline. We demonstrate that this synthetic corpus enables effective Parameter-Efficient Fine-Tuning (PEFT) of VLMs and substantially boosts the performance of state-of-the-art object detectors such as YOLO and DETR. Notably, in the absence of synthetic data (SynSpill dataset), VLMs still generalize better to unseen spill scenarios than these detectors. When SynSpill is used, both VLMs and detectors achieve marked improvements, with their performance becoming comparable. Our results underscore that high-fidelity synthetic data is a powerful means to bridge the domain gap in safety-critical applications. The combination of synthetic generation and lightweight adaptation offers a cost-effective, scalable pathway for deploying vision systems in industrial environments where real data is scarce/impractical to obtain. Project Page: https://synspill.vercel.app
Re:Verse -- Can Your VLM Read a Manga?
Aug 11, 2025Current Vision Language Models (VLMs) demonstrate a critical gap between surface-level recognition and deep narrative reasoning when processing sequential visual storytelling. Through a comprehensive investigation of manga narrative understanding, we reveal that while recent large multimodal models excel at individual panel interpretation, they systematically fail at temporal causality and cross-panel cohesion, core requirements for coherent story comprehension. We introduce a novel evaluation framework that combines fine-grained multimodal annotation, cross-modal embedding analysis, and retrieval-augmented assessment to systematically characterize these limitations. Our methodology includes (i) a rigorous annotation protocol linking visual elements to narrative structure through aligned light novel text, (ii) comprehensive evaluation across multiple reasoning paradigms, including direct inference and retrieval-augmented generation, and (iii) cross-modal similarity analysis revealing fundamental misalignments in current VLMs' joint representations. Applying this framework to Re:Zero manga across 11 chapters with 308 annotated panels, we conduct the first systematic study of long-form narrative understanding in VLMs through three core evaluation axes: generative storytelling, contextual dialogue grounding, and temporal reasoning. Our findings demonstrate that current models lack genuine story-level intelligence, struggling particularly with non-linear narratives, character consistency, and causal inference across extended sequences. This work establishes both the foundation and practical methodology for evaluating narrative intelligence, while providing actionable insights into the capability of deep sequential understanding of Discrete Visual Narratives beyond basic recognition in Multimodal Models.
LR0.FM: Low-Resolution Zero-shot Classification Benchmark For Foundation Models
Feb 07, 2025Visual-language foundation Models (FMs) exhibit remarkable zero-shot generalization across diverse tasks, largely attributed to extensive pre-training on largescale datasets. However, their robustness on low-resolution/pixelated (LR) images, a common challenge in real-world scenarios, remains underexplored. We introduce LR0.FM, a comprehensive benchmark evaluating the impact of low resolution on the zero-shot classification performance of 10 FM(s) across 66 backbones and 15 datasets. We propose a novel metric, Weighted Aggregated Robustness, to address the limitations of existing metrics and better evaluate model performance across resolutions and datasets. Our key findings show that: (i) model size positively correlates with robustness to resolution degradation, (ii) pre-training dataset quality is more important than its size, and (iii) fine-tuned and higher resolution models are less robust against LR. Our analysis further reveals that the model makes semantically reasonable predictions at LR, and the lack of fine-grained details in input adversely impacts the model's initial layers more than the deeper layers. We use these insights and introduce a simple strategy, LR-TK0, to enhance the robustness of models without compromising their pre-trained weights. We demonstrate the effectiveness of LR-TK0 for robustness against low-resolution across several datasets and its generalization capability across backbones and other approaches. Code is available at https://github.com/shyammarjit/LR0.FM
PV-S3: Advancing Automatic Photovoltaic Defect Detection using Semi-Supervised Semantic Segmentation of Electroluminescence Images
Apr 21, 2024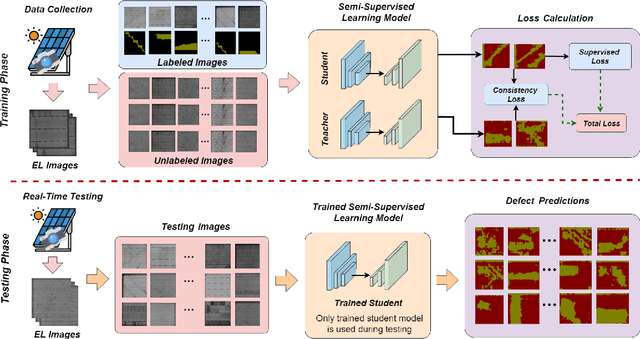
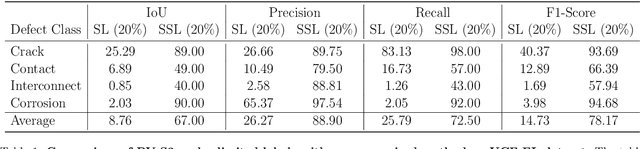
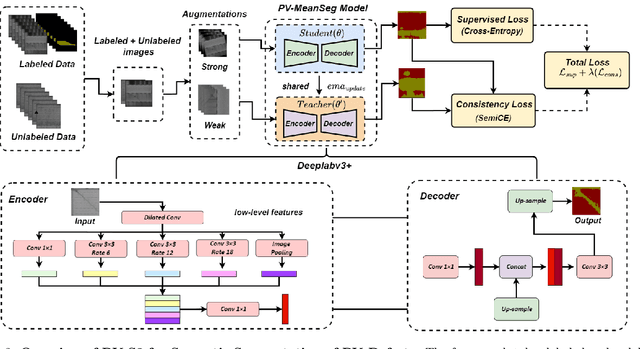
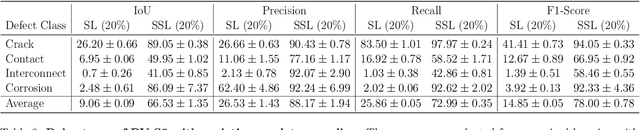
Photovoltaic (PV) systems allow us to tap into all abundant solar energy, however they require regular maintenance for high efficiency and to prevent degradation. Traditional manual health check, using Electroluminescence (EL) imaging, is expensive and logistically challenging making automated defect detection essential. Current automation approaches require extensive manual expert labeling, which is time-consuming, expensive, and prone to errors. We propose PV-S3 (Photovoltaic-Semi Supervised Segmentation), a Semi-Supervised Learning approach for semantic segmentation of defects in EL images that reduces reliance on extensive labeling. PV-S3 is a Deep learning model trained using a few labeled images along with numerous unlabeled images. We introduce a novel Semi Cross-Entropy loss function to train PV-S3 which addresses the challenges specific to automated PV defect detection, such as diverse defect types and class imbalance. We evaluate PV-S3 on multiple datasets and demonstrate its effectiveness and adaptability. With merely 20% labeled samples, we achieve an absolute improvement of 9.7% in IoU, 29.9% in Precision, 12.75% in Recall, and 20.42% in F1-Score over prior state-of-the-art supervised method (which uses 100% labeled samples) on UCF-EL dataset (largest dataset available for semantic segmentation of EL images) showing improvement in performance while reducing the annotation costs by 80%.
Semi-supervised Active Learning for Video Action Detection
Dec 12, 2023



In this work, we focus on label efficient learning for video action detection. We develop a novel semi-supervised active learning approach which utilizes both labeled as well as unlabeled data along with informative sample selection for action detection. Video action detection requires spatio-temporal localization along with classification, which poses several challenges for both active learning informative sample selection as well as semi-supervised learning pseudo label generation. First, we propose NoiseAug, a simple augmentation strategy which effectively selects informative samples for video action detection. Next, we propose fft-attention, a novel technique based on high-pass filtering which enables effective utilization of pseudo label for SSL in video action detection by emphasizing on relevant activity region within a video. We evaluate the proposed approach on three different benchmark datasets, UCF-101-24, JHMDB-21, and Youtube-VOS. First, we demonstrate its effectiveness on video action detection where the proposed approach outperforms prior works in semi-supervised and weakly-supervised learning along with several baseline approaches in both UCF101-24 and JHMDB-21. Next, we also show its effectiveness on Youtube-VOS for video object segmentation demonstrating its generalization capability for other dense prediction tasks in videos.
GAMa: Cross-view Video Geo-localization
Jul 06, 2022
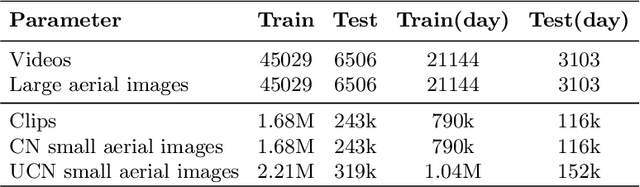


The existing work in cross-view geo-localization is based on images where a ground panorama is matched to an aerial image. In this work, we focus on ground videos instead of images which provides additional contextual cues which are important for this task. There are no existing datasets for this problem, therefore we propose GAMa dataset, a large-scale dataset with ground videos and corresponding aerial images. We also propose a novel approach to solve this problem. At clip-level, a short video clip is matched with corresponding aerial image and is later used to get video-level geo-localization of a long video. Moreover, we propose a hierarchical approach to further improve the clip-level geolocalization. It is a challenging dataset, unaligned and limited field of view, and our proposed method achieves a Top-1 recall rate of 19.4% and 45.1% @1.0mile. Code and dataset are available at following link: https://github.com/svyas23/GAMa.
Multi-modal Robustness Analysis Against Language and Visual Perturbations
Jul 06, 2022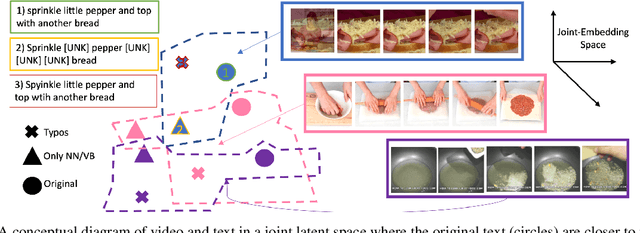

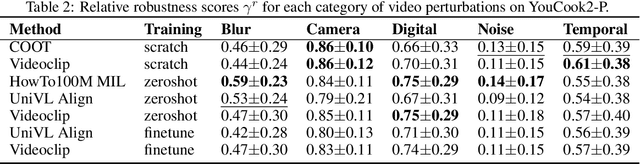
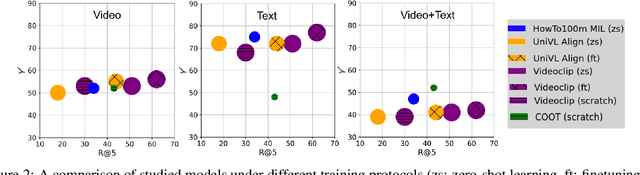
Joint visual and language modeling on large-scale datasets has recently shown a good progress in multi-modal tasks when compared to single modal learning. However, robustness of these approaches against real-world perturbations has not been studied. In this work, we perform the first extensive robustness study of such models against various real-world perturbations focusing on video and language. We focus on text-to-video retrieval and propose two large-scale benchmark datasets, MSRVTT-P and YouCook2-P, which utilize 90 different visual and 35 different textual perturbations. The study reveals some interesting findings: 1) The studied models are more robust when text is perturbed versus when video is perturbed 2) The transformer text encoder is more robust on non-semantic changing text perturbations and visual perturbations compared to word embedding approaches. 3) Using two-branch encoders in isolation is typically more robust than when architectures use cross-attention. We hope this study will serve as a benchmark and guide future research in robust multimodal learning.