 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLARNet: Latent Action Representation for Human Action Synthesis
Paper and Code
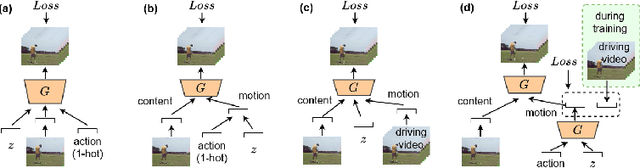
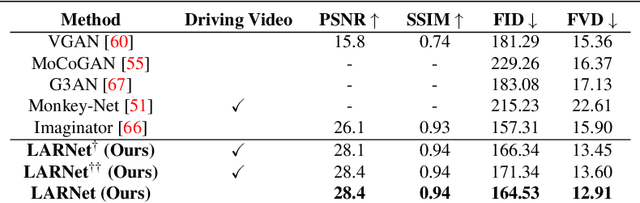
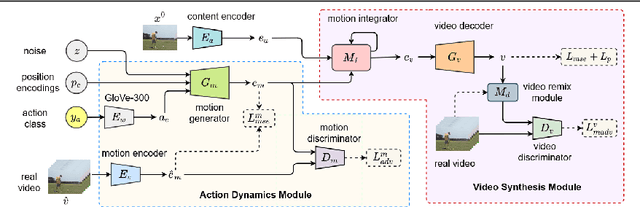
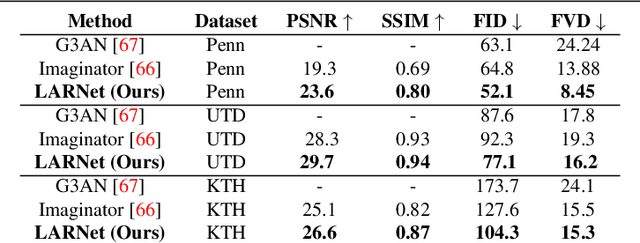
We present LARNet, a novel end-to-end approach for generating human action videos. A joint generative modeling of appearance and dynamics to synthesize a video is very challenging and therefore recent works in video synthesis have proposed to decompose these two factors. However, these methods require a driving video to model the video dynamics. In this work, we propose a generative approach instead, which explicitly learns action dynamics in latent space avoiding the need of a driving video during inference. The generated action dynamics is integrated with the appearance using a recurrent hierarchical structure which induces motion at different scales to focus on both coarse as well as fine level action details. In addition, we propose a novel mix-adversarial loss function which aims at improving the temporal coherency of synthesized videos. We evaluate the proposed approach on four real-world human action datasets demonstrating the effectiveness of the proposed approach in generating human actions. Code available at https://github.com/aayushjr/larnet.